 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTORM: Spatio-Temporal Reconstruction Model for Large-Scale Outdoor Scenes
Dec 31, 2024



We present STORM, a spatio-temporal reconstruction model designed for reconstructing dynamic outdoor scenes from sparse observations. Existing dynamic reconstruction methods often rely on per-scene optimization, dense observations across space and time, and strong motion supervision, resulting in lengthy optimization times, limited generalization to novel views or scenes, and degenerated quality caused by noisy pseudo-labels for dynamics. To address these challenges, STORM leverages a data-driven Transformer architecture that directly infers dynamic 3D scene representations--parameterized by 3D Gaussians and their velocities--in a single forward pass. Our key design is to aggregate 3D Gaussians from all frames using self-supervised scene flows, transforming them to the target timestep to enable complete (i.e., "amodal") reconstructions from arbitrary viewpoints at any moment in time. As an emergent property, STORM automatically captures dynamic instances and generates high-quality masks using only reconstruction losses. Extensive experiments on public datasets show that STORM achieves precise dynamic scene reconstruction, surpassing state-of-the-art per-scene optimization methods (+4.3 to 6.6 PSNR) and existing feed-forward approaches (+2.1 to 4.7 PSNR) in dynamic regions. STORM reconstructs large-scale outdoor scenes in 200ms, supports real-time rendering, and outperforms competitors in scene flow estimation, improving 3D EPE by 0.422m and Acc5 by 28.02%. Beyond reconstruction, we showcase four additional applications of our model, illustrating the potential of self-supervised learning for broader dynamic scene understanding.
Natural Language Fine-Tuning
Dec 29, 2024Large language model fine-tuning techniques typically depend on extensive labeled data, external guidance, and feedback, such as human alignment, scalar rewards, and demonstration. However, in practical application, the scarcity of specific knowledge poses unprecedented challenges to existing fine-tuning techniques. In this paper, focusing on fine-tuning tasks in specific domains with limited data, we introduce Natural Language Fine-Tuning (NLFT), which utilizes natural language for fine-tuning for the first time. By leveraging the strong language comprehension capability of the target LM, NLFT attaches the guidance of natural language to the token-level outputs. Then, saliency tokens are identified with calculated probabilities. Since linguistic information is effectively utilized in NLFT, our proposed method significantly reduces training costs. It markedly enhances training efficiency, comprehensively outperforming reinforcement fine-tuning algorithms in accuracy, time-saving, and resource conservation. Additionally, on the macro level, NLFT can be viewed as a token-level fine-grained optimization of SFT, thereby efficiently replacing the SFT process without the need for warm-up (as opposed to ReFT requiring multiple rounds of warm-up with SFT). Compared to SFT, NLFT does not increase the algorithmic complexity, maintaining O(n). Extensive experiments on the GSM8K dataset demonstrate that NLFT, with only 50 data instances, achieves an accuracy increase that exceeds SFT by 219%. Compared to ReFT, the time complexity and space complexity of NLFT are reduced by 78.27% and 92.24%, respectively. The superior technique of NLFT is paving the way for the deployment of various innovative LLM fine-tuning applications when resources are limited at network edges. Our code has been released at https://github.com/Julia-LiuJ/NLFT.
Aria-UI: Visual Grounding for GUI Instructions
Dec 20, 2024



Digital agents for automating tasks across different platforms by directly manipulating the GUIs are increasingly important. For these agents, grounding from language instructions to target elements remains a significant challenge due to reliance on HTML or AXTree inputs. In this paper, we introduce Aria-UI, a large multimodal model specifically designed for GUI grounding. Aria-UI adopts a pure-vision approach, eschewing reliance on auxiliary inputs. To adapt to heterogeneous planning instructions, we propose a scalable data pipeline that synthesizes diverse and high-quality instruction samples for grounding. To handle dynamic contexts in task performing, Aria-UI incorporates textual and text-image interleaved action histories, enabling robust context-aware reasoning for grounding. Aria-UI sets new state-of-the-art results across offline and online agent benchmarks, outperforming both vision-only and AXTree-reliant baselines. We release all training data and model checkpoints to foster further research at https://ariaui.github.io.
Learning from Massive Human Videos for Universal Humanoid Pose Control
Dec 18, 2024



Scalable learning of humanoid robots is crucial for their deployment in real-world applications. While traditional approaches primarily rely on reinforcement learning or teleoperation to achieve whole-body control, they are often limited by the diversity of simulated environments and the high costs of demonstration collection. In contrast, human videos are ubiquitous and present an untapped source of semantic and motion information that could significantly enhance the generalization capabilities of humanoid robots. This paper introduces Humanoid-X, a large-scale dataset of over 20 million humanoid robot poses with corresponding text-based motion descriptions, designed to leverage this abundant data. Humanoid-X is curated through a comprehensive pipeline: data mining from the Internet, video caption generation, motion retargeting of humans to humanoid robots, and policy learning for real-world deployment. With Humanoid-X, we further train a large humanoid model, UH-1, which takes text instructions as input and outputs corresponding actions to control a humanoid robot. Extensive simulated and real-world experiments validate that our scalable training approach leads to superior generalization in text-based humanoid control, marking a significant step toward adaptable, real-world-ready humanoid robots.
How to Re-enable PDE Loss for Physical Systems Modeling Under Partial Observation
Dec 12, 2024In science and engineering, machine learning techniques are increasingly successful in physical systems modeling (predicting future states of physical systems). Effectively integrating PDE loss as a constraint of system transition can improve the model's prediction by overcoming generalization issues due to data scarcity, especially when data acquisition is costly. However, in many real-world scenarios, due to sensor limitations, the data we can obtain is often only partial observation, making the calculation of PDE loss seem to be infeasible, as the PDE loss heavily relies on high-resolution states. We carefully study this problem and propose a novel framework named Re-enable PDE Loss under Partial Observation (RPLPO). The key idea is that although enabling PDE loss to constrain system transition solely is infeasible, we can re-enable PDE loss by reconstructing the learnable high-resolution state and constraining system transition simultaneously. Specifically, RPLPO combines an encoding module for reconstructing learnable high-resolution states with a transition module for predicting future states. The two modules are jointly trained by data and PDE loss. We conduct experiments in various physical systems to demonstrate that RPLPO has significant improvement in generalization, even when observation is sparse, irregular, noisy, and PDE is inaccurate. The code is available on GitHub: RPLPO.
LoRA3D: Low-Rank Self-Calibration of 3D Geometric Foundation Models
Dec 10, 2024



Emerging 3D geometric foundation models, such as DUSt3R, offer a promising approach for in-the-wild 3D vision tasks. However, due to the high-dimensional nature of the problem space and scarcity of high-quality 3D data, these pre-trained models still struggle to generalize to many challenging circumstances, such as limited view overlap or low lighting. To address this, we propose LoRA3D, an efficient self-calibration pipeline to $\textit{specialize}$ the pre-trained models to target scenes using their own multi-view predictions. Taking sparse RGB images as input, we leverage robust optimization techniques to refine multi-view predictions and align them into a global coordinate frame. In particular, we incorporate prediction confidence into the geometric optimization process, automatically re-weighting the confidence to better reflect point estimation accuracy. We use the calibrated confidence to generate high-quality pseudo labels for the calibrating views and use low-rank adaptation (LoRA) to fine-tune the models on the pseudo-labeled data. Our method does not require any external priors or manual labels. It completes the self-calibration process on a $\textbf{single standard GPU within just 5 minutes}$. Each low-rank adapter requires only $\textbf{18MB}$ of storage. We evaluated our method on $\textbf{more than 160 scenes}$ from the Replica, TUM and Waymo Open datasets, achieving up to $\textbf{88% performance improvement}$ on 3D reconstruction, multi-view pose estimation and novel-view rendering.
Extrapolated Urban View Synthesis Benchmark
Dec 10, 2024



Photorealistic simulators are essential for the training and evaluation of vision-centric autonomous vehicles (AVs). At their core is Novel View Synthesis (NVS), a crucial capability that generates diverse unseen viewpoints to accommodate the broad and continuous pose distribution of AVs. Recent advances in radiance fields, such as 3D Gaussian Splatting, achieve photorealistic rendering at real-time speeds and have been widely used in modeling large-scale driving scenes. However, their performance is commonly evaluated using an interpolated setup with highly correlated training and test views. In contrast, extrapolation, where test views largely deviate from training views, remains underexplored, limiting progress in generalizable simulation technology. To address this gap, we leverage publicly available AV datasets with multiple traversals, multiple vehicles, and multiple cameras to build the first Extrapolated Urban View Synthesis (EUVS) benchmark. Meanwhile, we conduct quantitative and qualitative evaluations of state-of-the-art Gaussian Splatting methods across different difficulty levels. Our results show that Gaussian Splatting is prone to overfitting to training views. Besides, incorporating diffusion priors and improving geometry cannot fundamentally improve NVS under large view changes, highlighting the need for more robust approaches and large-scale training. We have released our data to help advance self-driving and urban robotics simulation technology.
Wavelet Diffusion Neural Operator
Dec 06, 2024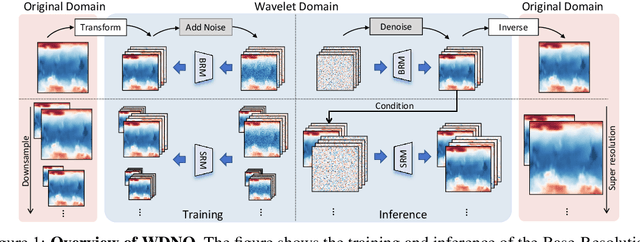
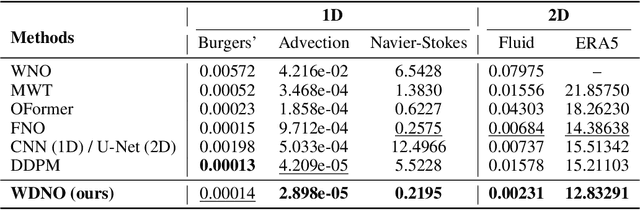
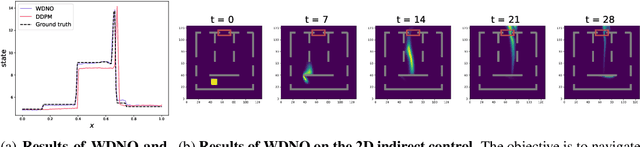
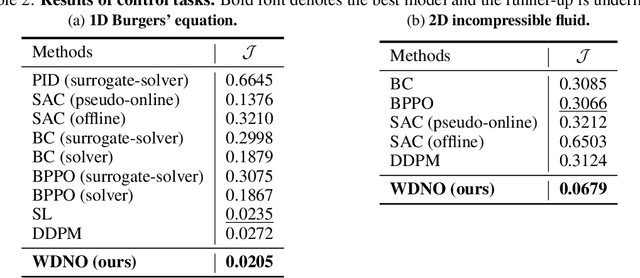
Simulating and controlling physical systems described by partial differential equations (PDEs) are crucial tasks across science and engineering. Recently, diffusion generative models have emerged as a competitive class of methods for these tasks due to their ability to capture long-term dependencies and model high-dimensional states. However, diffusion models typically struggle with handling system states with abrupt changes and generalizing to higher resolutions. In this work, we propose Wavelet Diffusion Neural Operator (WDNO), a novel PDE simulation and control framework that enhances the handling of these complexities. WDNO comprises two key innovations. Firstly, WDNO performs diffusion-based generative modeling in the wavelet domain for the entire trajectory to handle abrupt changes and long-term dependencies effectively. Secondly, to address the issue of poor generalization across different resolutions, which is one of the fundamental tasks in modeling physical systems, we introduce multi-resolution training. We validate WDNO on five physical systems, including 1D advection equation, three challenging physical systems with abrupt changes (1D Burgers' equation, 1D compressible Navier-Stokes equation and 2D incompressible fluid), and a real-world dataset ERA5, which demonstrates superior performance on both simulation and control tasks over state-of-the-art methods, with significant improvements in long-term and detail prediction accuracy. Remarkably, in the challenging context of the 2D high-dimensional and indirect control task aimed at reducing smoke leakage, WDNO reduces the leakage by 33.2% compared to the second-best baseline.
Multi-cam Multi-map Visual Inertial Localization: System, Validation and Dataset
Dec 05, 2024



Map-based localization is crucial for the autonomous movement of robots as it provides real-time positional feedback. However, existing VINS and SLAM systems cannot be directly integrated into the robot's control loop. Although VINS offers high-frequency position estimates, it suffers from drift in long-term operation. And the drift-free trajectory output by SLAM is post-processed with loop correction, which is non-causal. In practical control, it is impossible to update the current pose with future information. Furthermore, existing SLAM evaluation systems measure accuracy after aligning the entire trajectory, which overlooks the transformation error between the odometry start frame and the ground truth frame. To address these issues, we propose a multi-cam multi-map visual inertial localization system, which provides real-time, causal and drift-free position feedback to the robot control loop. Additionally, we analyze the error composition of map-based localization systems and propose a set of evaluation metric suitable for measuring causal localization performance. To validate our system, we design a multi-camera IMU hardware setup and collect a long-term challenging campus dataset. Experimental results demonstrate the higher real-time localization accuracy of the proposed system. To foster community development, both the system and the dataset have been made open source https://github.com/zoeylove/Multi-cam-Multi-map-VILO/tree/main.
InfiniCube: Unbounded and Controllable Dynamic 3D Driving Scene Generation with World-Guided Video Models
Dec 05, 2024



We present InfiniCube, a scalable method for generating unbounded dynamic 3D driving scenes with high fidelity and controllability. Previous methods for scene generation either suffer from limited scales or lack geometric and appearance consistency along generated sequences. In contrast, we leverage the recent advancements in scalable 3D representation and video models to achieve large dynamic scene generation that allows flexible controls through HD maps, vehicle bounding boxes, and text descriptions. First, we construct a map-conditioned sparse-voxel-based 3D generative model to unleash its power for unbounded voxel world generation. Then, we re-purpose a video model and ground it on the voxel world through a set of carefully designed pixel-aligned guidance buffers, synthesizing a consistent appearance. Finally, we propose a fast feed-forward approach that employs both voxel and pixel branches to lift the dynamic videos to dynamic 3D Gaussians with controllable objects. Our method can generate controllable and realistic 3D driving scenes, and extensive experiments validate the effectiveness and superiority of our model.