 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMilliVid: Hierarchical Latents for Long-Range Consistency in Video Generation
Jun 08, 2026Video generative models have become increasingly powerful, but long-range consistency remains challenging to achieve because even a few dozen frames require impractically long transformer sequence lengths. We show that this issue can be mitigated by generating video using coarse-to-fine rollout within a multi-scale token space. Our approach is simple: first, we pre-train an autoencoder that compresses each frame into a hierarchy of tokens, with levels ranging from the typical latent resolution to only a handful of tokens per frame. The coarsest levels capture the most consequential information, such as scene layout and semantics, while finer levels add high-frequency appearance and texture. Then, we train a video diffusion model to generate these tokens using coarse-to-fine rollout. By carefully controlling the level of detail at which frames are generated and used as context during each rollout step, we are able to preserve long-range consistency in geometry and object permanence while spending less compute on the long-range consistency of less perceptually relevant details. We validate this approach using a custom dataset of long Minecraft videos, where it produces substantially more consistent rollouts compared to existing baselines.
RoboDream: Compositional World Models for Scalable Robot Data Synthesis
Jun 01, 2026Scaling robot learning requires large-scale, diverse demonstrations, yet real-world data collection via teleoperation remains prohibitively expensive and time-consuming. While video diffusion models offer a promising avenue for data scaling, existing generative approaches are often limited to superficial visual augmentation, or suffer from embodiment hallucinations that yield physically infeasible motions. We present a generalizable embodiment-centric world model that achieves scalable data generation by synthesizing photorealistic demonstrations with novel objects, in novel scenes, and from novel viewpoints. Our approach anchors generation to rendered robot motion while conditioning on explicit scene and object priors, effectively decoupling trajectory execution from environment synthesis. This formulation has the potential to unlock two powerful data scaling capabilities: (1) retrieval and rebirth, which repurposes existing trajectories into entirely new contexts without new motion data; and (2) prop-free teleoperation, where operators manipulate empty air and the model hallucinates the target objects and scene afterwards, eliminating reset time. We demonstrate with real-world experiments that our generated data consistently improves downstream policy performance and significantly reduces real-world data requirements across diverse manipulation tasks.
DreamPlan: Efficient Reinforcement Fine-Tuning of Vision-Language Planners via Video World Models
Mar 17, 2026Robotic manipulation requires sophisticated commonsense reasoning, a capability naturally possessed by large-scale Vision-Language Models (VLMs). While VLMs show promise as zero-shot planners, their lack of grounded physical understanding often leads to compounding errors and low success rates when deployed in complex real-world environments, particularly for challenging tasks like deformable object manipulation. Although Reinforcement Learning (RL) can adapt these planners to specific task dynamics, directly fine-tuning VLMs via real-world interaction is prohibitively expensive, unsafe, and sample-inefficient. To overcome this bottleneck, we introduce DreamPlan, a novel framework for the reinforcement fine-tuning of VLM planners via video world models. Instead of relying on costly physical rollouts, DreamPlan first leverages the zero-shot VLM to collect exploratory interaction data. We demonstrate that this sub-optimal data is sufficient to train an action-conditioned video generation model, which implicitly captures complex real-world physics. Subsequently, the VLM planner is fine-tuned entirely within the "imagination" of this video world model using Odds Ratio Policy Optimization (ORPO). By utilizing these virtual rollouts, physical and task-specific knowledge is efficiently injected into the VLM. Our results indicate that DreamPlan bridges the gap between semantic reasoning and physical grounding, significantly improving manipulation success rates without the need for large-scale real-world data collection. Our project page is https://psi-lab.ai/DreamPlan/.
Large Reward Models: Generalizable Online Robot Reward Generation with Vision-Language Models
Mar 17, 2026Reinforcement Learning (RL) has shown great potential in refining robotic manipulation policies, yet its efficacy remains strongly bottlenecked by the difficulty of designing generalizable reward functions. In this paper, we propose a framework for online policy refinement by adapting foundation VLMs into online reward generators. We develop a robust, scalable reward model based on a state-of-the-art VLM, trained on a large-scale, multi-source dataset encompassing real-world robot trajectories, human-object interactions, and diverse simulated environments. Unlike prior approaches that evaluate entire trajectories post-hoc, our method leverages the VLM to formulate a multifaceted reward signal comprising process, completion, and temporal contrastive rewards based on current visual observations. Initializing with a base policy trained via Imitation Learning (IL), we employ these VLM rewards to guide the model to correct sub-optimal behaviors in a closed-loop manner. We evaluate our framework on challenging long-horizon manipulation benchmarks requiring sequential execution and precise control. Crucially, our reward model operates in a purely zero-shot manner within these test environments. Experimental results demonstrate that our method significantly improves the success rate of the initial IL policy within just 30 RL iterations, demonstrating remarkable sample efficiency. This empirical evidence highlights that VLM-generated signals can provide reliable feedback to resolve execution errors, effectively eliminating the need for manual reward engineering and facilitating efficient online refinement for robot learning.
Fiducial Exoskeletons: Image-Centric Robot State Estimation
Jan 12, 2026We introduce Fiducial Exoskeletons, an image-based reformulation of 3D robot state estimation that replaces cumbersome procedures and motor-centric pipelines with single-image inference. Traditional approaches - especially robot-camera extrinsic estimation - often rely on high-precision actuators and require time-consuming routines such as hand-eye calibration. In contrast, modern learning-based robot control is increasingly trained and deployed from RGB observations on lower-cost hardware. Our key insight is twofold. First, we cast robot state estimation as 6D pose estimation of each link from a single RGB image: the robot-camera base transform is obtained directly as the estimated base-link pose, and the joint state is recovered via a lightweight global optimization that enforces kinematic consistency with the observed link poses (optionally warm-started with encoder readings). Second, we make per-link 6D pose estimation robust and simple - even without learning - by introducing the fiducial exoskeleton: a lightweight 3D-printed mount with a fiducial marker on each link and known marker-link geometry. This design yields robust camera-robot extrinsics, per-link SE(3) poses, and joint-angle state from a single image, enabling robust state estimation even on unplugged robots. Demonstrated on a low-cost robot arm, fiducial exoskeletons substantially simplify setup while improving calibration, state accuracy, and downstream 3D control performance. We release code and printable hardware designs to enable further algorithm-hardware co-design.
AnchorDream: Repurposing Video Diffusion for Embodiment-Aware Robot Data Synthesis
Dec 12, 2025The collection of large-scale and diverse robot demonstrations remains a major bottleneck for imitation learning, as real-world data acquisition is costly and simulators offer limited diversity and fidelity with pronounced sim-to-real gaps. While generative models present an attractive solution, existing methods often alter only visual appearances without creating new behaviors, or suffer from embodiment inconsistencies that yield implausible motions. To address these limitations, we introduce AnchorDream, an embodiment-aware world model that repurposes pretrained video diffusion models for robot data synthesis. AnchorDream conditions the diffusion process on robot motion renderings, anchoring the embodiment to prevent hallucination while synthesizing objects and environments consistent with the robot's kinematics. Starting from only a handful of human teleoperation demonstrations, our method scales them into large, diverse, high-quality datasets without requiring explicit environment modeling. Experiments show that the generated data leads to consistent improvements in downstream policy learning, with relative gains of 36.4% in simulator benchmarks and nearly double performance in real-world studies. These results suggest that grounding generative world models in robot motion provides a practical path toward scaling imitation learning.
Robot Learning from a Physical World Model
Nov 10, 2025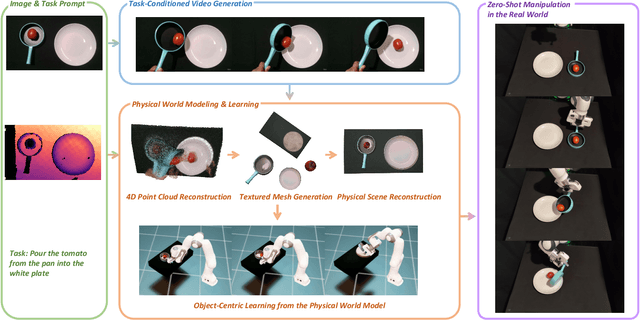

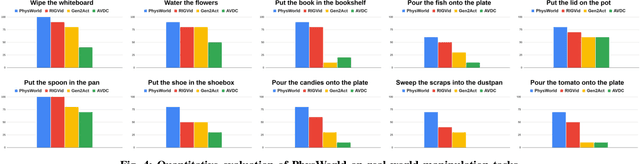

We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.
Do You Know Where Your Camera Is? View-Invariant Policy Learning with Camera Conditioning
Oct 02, 2025We study view-invariant imitation learning by explicitly conditioning policies on camera extrinsics. Using Plucker embeddings of per-pixel rays, we show that conditioning on extrinsics significantly improves generalization across viewpoints for standard behavior cloning policies, including ACT, Diffusion Policy, and SmolVLA. To evaluate policy robustness under realistic viewpoint shifts, we introduce six manipulation tasks in RoboSuite and ManiSkill that pair "fixed" and "randomized" scene variants, decoupling background cues from camera pose. Our analysis reveals that policies without extrinsics often infer camera pose using visual cues from static backgrounds in fixed scenes; this shortcut collapses when workspace geometry or camera placement shifts. Conditioning on extrinsics restores performance and yields robust RGB-only control without depth. We release the tasks, demonstrations, and code at https://ripl.github.io/know_your_camera/ .
ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping
Apr 15, 2025



Robotic grasping is a cornerstone capability of embodied systems. Many methods directly output grasps from partial information without modeling the geometry of the scene, leading to suboptimal motion and even collisions. To address these issues, we introduce ZeroGrasp, a novel framework that simultaneously performs 3D reconstruction and grasp pose prediction in near real-time. A key insight of our method is that occlusion reasoning and modeling the spatial relationships between objects is beneficial for both accurate reconstruction and grasping. We couple our method with a novel large-scale synthetic dataset, which comprises 1M photo-realistic images, high-resolution 3D reconstructions and 11.3B physically-valid grasp pose annotations for 12K objects from the Objaverse-LVIS dataset. We evaluate ZeroGrasp on the GraspNet-1B benchmark as well as through real-world robot experiments. ZeroGrasp achieves state-of-the-art performance and generalizes to novel real-world objects by leveraging synthetic data.
SIRE: SE(3) Intrinsic Rigidity Embeddings
Mar 10, 2025



Motion serves as a powerful cue for scene perception and understanding by separating independently moving surfaces and organizing the physical world into distinct entities. We introduce SIRE, a self-supervised method for motion discovery of objects and dynamic scene reconstruction from casual scenes by learning intrinsic rigidity embeddings from videos. Our method trains an image encoder to estimate scene rigidity and geometry, supervised by a simple 4D reconstruction loss: a least-squares solver uses the estimated geometry and rigidity to lift 2D point track trajectories into SE(3) tracks, which are simply re-projected back to 2D and compared against the original 2D trajectories for supervision. Crucially, our framework is fully end-to-end differentiable and can be optimized either on video datasets to learn generalizable image priors, or even on a single video to capture scene-specific structure - highlighting strong data efficiency. We demonstrate the effectiveness of our rigidity embeddings and geometry across multiple settings, including downstream object segmentation, SE(3) rigid motion estimation, and self-supervised depth estimation. Our findings suggest that SIRE can learn strong geometry and motion rigidity priors from video data, with minimal supervision.