 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamPlan: Efficient Reinforcement Fine-Tuning of Vision-Language Planners via Video World Models
Mar 17, 2026Robotic manipulation requires sophisticated commonsense reasoning, a capability naturally possessed by large-scale Vision-Language Models (VLMs). While VLMs show promise as zero-shot planners, their lack of grounded physical understanding often leads to compounding errors and low success rates when deployed in complex real-world environments, particularly for challenging tasks like deformable object manipulation. Although Reinforcement Learning (RL) can adapt these planners to specific task dynamics, directly fine-tuning VLMs via real-world interaction is prohibitively expensive, unsafe, and sample-inefficient. To overcome this bottleneck, we introduce DreamPlan, a novel framework for the reinforcement fine-tuning of VLM planners via video world models. Instead of relying on costly physical rollouts, DreamPlan first leverages the zero-shot VLM to collect exploratory interaction data. We demonstrate that this sub-optimal data is sufficient to train an action-conditioned video generation model, which implicitly captures complex real-world physics. Subsequently, the VLM planner is fine-tuned entirely within the "imagination" of this video world model using Odds Ratio Policy Optimization (ORPO). By utilizing these virtual rollouts, physical and task-specific knowledge is efficiently injected into the VLM. Our results indicate that DreamPlan bridges the gap between semantic reasoning and physical grounding, significantly improving manipulation success rates without the need for large-scale real-world data collection. Our project page is https://psi-lab.ai/DreamPlan/.
Large Reward Models: Generalizable Online Robot Reward Generation with Vision-Language Models
Mar 17, 2026Reinforcement Learning (RL) has shown great potential in refining robotic manipulation policies, yet its efficacy remains strongly bottlenecked by the difficulty of designing generalizable reward functions. In this paper, we propose a framework for online policy refinement by adapting foundation VLMs into online reward generators. We develop a robust, scalable reward model based on a state-of-the-art VLM, trained on a large-scale, multi-source dataset encompassing real-world robot trajectories, human-object interactions, and diverse simulated environments. Unlike prior approaches that evaluate entire trajectories post-hoc, our method leverages the VLM to formulate a multifaceted reward signal comprising process, completion, and temporal contrastive rewards based on current visual observations. Initializing with a base policy trained via Imitation Learning (IL), we employ these VLM rewards to guide the model to correct sub-optimal behaviors in a closed-loop manner. We evaluate our framework on challenging long-horizon manipulation benchmarks requiring sequential execution and precise control. Crucially, our reward model operates in a purely zero-shot manner within these test environments. Experimental results demonstrate that our method significantly improves the success rate of the initial IL policy within just 30 RL iterations, demonstrating remarkable sample efficiency. This empirical evidence highlights that VLM-generated signals can provide reliable feedback to resolve execution errors, effectively eliminating the need for manual reward engineering and facilitating efficient online refinement for robot learning.
$Ψ_0$: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
Mar 12, 2026We introduce $Ψ_0$ (Psi-Zero), an open foundation model to address challenging humanoid loco-manipulation tasks. While existing approaches often attempt to address this fundamental problem by co-training on large and diverse human and humanoid data, we argue that this strategy is suboptimal due to the fundamental kinematic and motion disparities between humans and humanoid robots. Therefore, data efficiency and model performance remain unsatisfactory despite the considerable data volume. To address this challenge, \ours\;decouples the learning process to maximize the utility of heterogeneous data sources. Specifically, we propose a staged training paradigm with different learning objectives: First, we autoregressively pre-train a VLM backbone on large-scale egocentric human videos to acquire generalizable visual-action representations. Then, we post-train a flow-based action expert on high-quality humanoid robot data to learn precise robot joint control. Our research further identifies a critical yet often overlooked data recipe: in contrast to approaches that scale with noisy Internet clips or heterogeneous cross-embodiment robot datasets, we demonstrate that pre-training on high-quality egocentric human manipulation data followed by post-training on domain-specific real-world humanoid trajectories yields superior performance. Extensive real-world experiments demonstrate that \ours\ achieves the best performance using only about 800 hours of human video data and 30 hours of real-world robot data, outperforming baselines pre-trained on more than 10$\times$ as much data by over 40\% in overall success rate across multiple tasks. We will open-source the entire ecosystem to the community, including a data processing and training pipeline, a humanoid foundation model, and a real-time action inference engine.
D-REX: Differentiable Real-to-Sim-to-Real Engine for Learning Dexterous Grasping
Mar 01, 2026Simulation provides a cost-effective and flexible platform for data generation and policy learning to develop robotic systems. However, bridging the gap between simulation and real-world dynamics remains a significant challenge, especially in physical parameter identification. In this work, we introduce a real-to-sim-to-real engine that leverages the Gaussian Splat representations to build a differentiable engine, enabling object mass identification from real-world visual observations and robot control signals, while enabling grasping policy learning simultaneously. Through optimizing the mass of the manipulated object, our method automatically builds high-fidelity and physically plausible digital twins. Additionally, we propose a novel approach to train force-aware grasping policies from limited data by transferring feasible human demonstrations into simulated robot demonstrations. Through comprehensive experiments, we demonstrate that our engine achieves accurate and robust performance in mass identification across various object geometries and mass values. Those optimized mass values facilitate force-aware policy learning, achieving superior and high performance in object grasping, effectively reducing the sim-to-real gap.
SeFA-Policy: Fast and Accurate Visuomotor Policy Learning with Selective Flow Alignment
Nov 11, 2025Developing efficient and accurate visuomotor policies poses a central challenge in robotic imitation learning. While recent rectified flow approaches have advanced visuomotor policy learning, they suffer from a key limitation: After iterative distillation, generated actions may deviate from the ground-truth actions corresponding to the current visual observation, leading to accumulated error as the reflow process repeats and unstable task execution. We present Selective Flow Alignment (SeFA), an efficient and accurate visuomotor policy learning framework. SeFA resolves this challenge by a selective flow alignment strategy, which leverages expert demonstrations to selectively correct generated actions and restore consistency with observations, while preserving multimodality. This design introduces a consistency correction mechanism that ensures generated actions remain observation-aligned without sacrificing the efficiency of one-step flow inference. Extensive experiments across both simulated and real-world manipulation tasks show that SeFA Policy surpasses state-of-the-art diffusion-based and flow-based policies, achieving superior accuracy and robustness while reducing inference latency by over 98%. By unifying rectified flow efficiency with observation-consistent action generation, SeFA provides a scalable and dependable solution for real-time visuomotor policy learning. Code is available on https://github.com/RongXueZoe/SeFA.
Robot Learning from a Physical World Model
Nov 10, 2025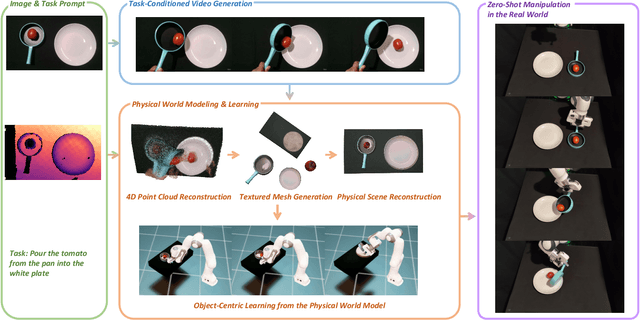

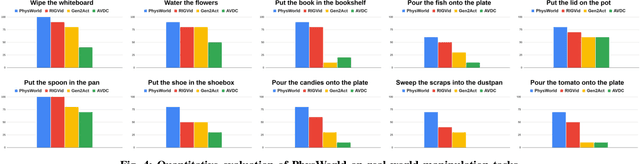

We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.
Learning an Implicit Physics Model for Image-based Fluid Simulation
Aug 11, 2025Humans possess an exceptional ability to imagine 4D scenes, encompassing both motion and 3D geometry, from a single still image. This ability is rooted in our accumulated observations of similar scenes and an intuitive understanding of physics. In this paper, we aim to replicate this capacity in neural networks, specifically focusing on natural fluid imagery. Existing methods for this task typically employ simplistic 2D motion estimators to animate the image, leading to motion predictions that often defy physical principles, resulting in unrealistic animations. Our approach introduces a novel method for generating 4D scenes with physics-consistent animation from a single image. We propose the use of a physics-informed neural network that predicts motion for each surface point, guided by a loss term derived from fundamental physical principles, including the Navier-Stokes equations. To capture appearance, we predict feature-based 3D Gaussians from the input image and its estimated depth, which are then animated using the predicted motions and rendered from any desired camera perspective. Experimental results highlight the effectiveness of our method in producing physically plausible animations, showcasing significant performance improvements over existing methods. Our project page is https://physfluid.github.io/ .
ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation
May 14, 2025Vision-Language Models (VLMs) have revolutionized artificial intelligence and robotics due to their commonsense reasoning capabilities. In robotic manipulation, VLMs are used primarily as high-level planners, but recent work has also studied their lower-level reasoning ability, which refers to making decisions about precise robot movements. However, the community currently lacks a clear and common benchmark that can evaluate how well VLMs can aid low-level reasoning in robotics. Consequently, we propose a novel benchmark, ManipBench, to evaluate the low-level robot manipulation reasoning capabilities of VLMs across various dimensions, including how well they understand object-object interactions and deformable object manipulation. We extensively test 33 representative VLMs across 10 model families on our benchmark, including variants to test different model sizes. Our evaluation shows that the performance of VLMs significantly varies across tasks, and there is a strong correlation between this performance and trends in our real-world manipulation tasks. It also shows that there remains a significant gap between these models and human-level understanding. See our website at: https://manipbench.github.io.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding
Jan 29, 2025Understanding the physical world is a fundamental challenge in embodied AI, critical for enabling agents to perform complex tasks and operate safely in real-world environments. While Vision-Language Models (VLMs) have shown great promise in reasoning and task planning for embodied agents, their ability to comprehend physical phenomena remains extremely limited. To close this gap, we introduce PhysBench, a comprehensive benchmark designed to evaluate VLMs' physical world understanding capability across a diverse set of tasks. PhysBench contains 10,002 entries of interleaved video-image-text data, categorized into four major domains: physical object properties, physical object relationships, physical scene understanding, and physics-based dynamics, further divided into 19 subclasses and 8 distinct capability dimensions. Our extensive experiments, conducted on 75 representative VLMs, reveal that while these models excel in common-sense reasoning, they struggle with understanding the physical world -- likely due to the absence of physical knowledge in their training data and the lack of embedded physical priors. To tackle the shortfall, we introduce PhysAgent, a novel framework that combines the generalization strengths of VLMs with the specialized expertise of vision models, significantly enhancing VLMs' physical understanding across a variety of tasks, including an 18.4\% improvement on GPT-4o. Furthermore, our results demonstrate that enhancing VLMs' physical world understanding capabilities can help embodied agents such as MOKA. We believe that PhysBench and PhysAgent offer valuable insights and contribute to bridging the gap between VLMs and physical world understanding.