 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafactory: A Scalable Agent Factory for Trustworthy Autonomous Intelligence
May 07, 2026As large models evolve from conversational assistants into autonomous agents, challenges increasingly arise from long-horizon decision making, tool use, and real environment interaction. Existing agenticinfrastructure remain fragmented across evaluation, data management, and agent evolution, making it difficult to discover risks systematically and improve models in a continuous closed loop. In this report, we present \textbf{Safactory}, a scalable agent factory for trustworthy autonomous intelligence. Safactory integrates three tightly coupled platforms: a \textbf{Parallel Simulation Platform} for trajectory generation, a \textbf{Trustworthy Data Platform} for trajectory storage and experience extraction, and an \textbf{Autonomous Evolution Platform} for asynchronous reinforcement learning and on-policy distillation. As far as we know, Safactory is the first framework to propose a unified evolutionary pipeline for next-generation trustworthy autonomous intelligence.
Towards Self-Improving Error Diagnosis in Multi-Agent Systems
Apr 19, 2026Large Language Model (LLM)-based Multi-Agent Systems (MAS) enable complex problem-solving but introduce significant debugging challenges, characterized by long interaction traces, inter-agent dependencies, and delayed error manifestation. Existing diagnostic approaches often rely on expensive expert annotation or ''LLM-as-a-judge'' paradigms, which struggle to pinpoint decisive error steps within extended contexts. In this paper, we introduce ErrorProbe, a self-improving framework for semantic failure attribution that identifies responsible agents and the originating error step. The framework operates via a three-stage pipeline: (1) operationalizing the MAS failure taxonomy to detect local anomalies, (2) performing symptom-driven backward tracing to prune irrelevant context, and (3) employing a specialized multi-agent team (Strategist, Investigator, Arbiter) to validate error hypotheses through tool-grounded execution. Crucially, ErrorProbe maintains a verified episodic memory that updates only when error patterns are confirmed by executable evidence, without the need for annotation. Experiments across the TracerTraj and Who&When benchmarks demonstrate that ErrorProbe significantly outperforms baselines, particularly in step-level localization, while the verified memory enables robust cross-domain transfer without retraining.
DeepInnovator: Triggering the Innovative Capabilities of LLMs
Feb 21, 2026The application of Large Language Models (LLMs) in accelerating scientific discovery has garnered increasing attention, with a key focus on constructing research agents endowed with innovative capability, i.e., the ability to autonomously generate novel and significant research ideas. Existing approaches predominantly rely on sophisticated prompt engineering and lack a systematic training paradigm. To address this, we propose DeepInnovator, a training framework designed to trigger the innovative capability of LLMs. Our approach comprises two core components. (1) ``Standing on the shoulders of giants''. We construct an automated data extraction pipeline to extract and organize structured research knowledge from a vast corpus of unlabeled scientific literature. (2) ``Conjectures and refutations''. We introduce a ``Next Idea Prediction'' training paradigm, which models the generation of research ideas as an iterative process of continuously predicting, evaluating, and refining plausible and novel next idea. Both automatic and expert evaluations demonstrate that our DeepInnovator-14B significantly outperforms untrained baselines, achieving win rates of 80.53\%-93.81\%, and attains performance comparable to that of current leading LLMs. This work provides a scalable training pathway toward building research agents with genuine, originative innovative capability, and will open-source the dataset to foster community advancement. Source code and data are available at: https://github.com/HKUDS/DeepInnovator.
Steering Large Reasoning Models towards Concise Reasoning via Flow Matching
Feb 05, 2026Large Reasoning Models (LRMs) excel at complex reasoning tasks, but their efficiency is often hampered by overly verbose outputs. Prior steering methods attempt to address this issue by applying a single, global vector to hidden representations -- an approach grounded in the restrictive linear representation hypothesis. In this work, we introduce FlowSteer, a nonlinear steering method that goes beyond uniform linear shifts by learning a complete transformation between the distributions associated with verbose and concise reasoning. This transformation is learned via Flow Matching as a velocity field, enabling precise, input-dependent control over the model's reasoning process. By aligning steered representations with the distribution of concise-reasoning activations, FlowSteer yields more compact reasoning than the linear shifts. Across diverse reasoning benchmarks, FlowSteer demonstrates strong task performance and token efficiency compared to leading inference-time baselines. Our work demonstrates that modeling the full distributional transport with generative techniques offers a more effective and principled foundation for controlling LRMs.
A$^2$Search: Ambiguity-Aware Question Answering with Reinforcement Learning
Oct 09, 2025



Recent advances in Large Language Models (LLMs) and Reinforcement Learning (RL) have led to strong performance in open-domain question answering (QA). However, existing models still struggle with questions that admit multiple valid answers. Standard QA benchmarks, which typically assume a single gold answer, overlook this reality and thus produce inappropriate training signals. Existing attempts to handle ambiguity often rely on costly manual annotation, which is difficult to scale to multi-hop datasets such as HotpotQA and MuSiQue. In this paper, we present A$^2$Search, an annotation-free, end-to-end training framework to recognize and handle ambiguity. At its core is an automated pipeline that detects ambiguous questions and gathers alternative answers via trajectory sampling and evidence verification. The model is then optimized with RL using a carefully designed $\mathrm{AnsF1}$ reward, which naturally accommodates multiple answers. Experiments on eight open-domain QA benchmarks demonstrate that A$^2$Search achieves new state-of-the-art performance. With only a single rollout, A$^2$Search-7B yields an average $\mathrm{AnsF1}@1$ score of $48.4\%$ across four multi-hop benchmarks, outperforming all strong baselines, including the substantially larger ReSearch-32B ($46.2\%$). Extensive analyses further show that A$^2$Search resolves ambiguity and generalizes across benchmarks, highlighting that embracing ambiguity is essential for building more reliable QA systems. Our code, data, and model weights can be found at https://github.com/zfj1998/A2Search
Understanding DeepResearch via Reports
Oct 09, 2025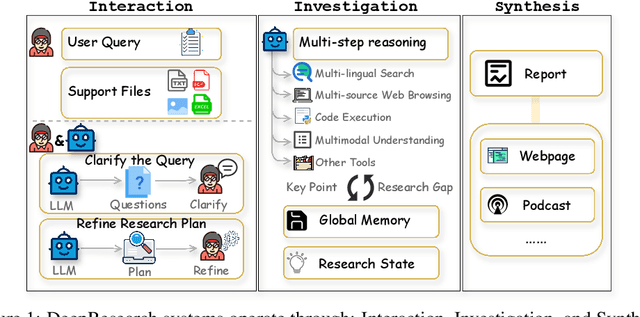

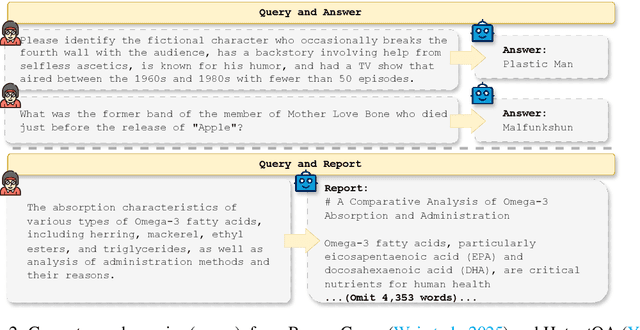

DeepResearch agents represent a transformative AI paradigm, conducting expert-level research through sophisticated reasoning and multi-tool integration. However, evaluating these systems remains critically challenging due to open-ended research scenarios and existing benchmarks that focus on isolated capabilities rather than holistic performance. Unlike traditional LLM tasks, DeepResearch systems must synthesize diverse sources, generate insights, and present coherent findings, which are capabilities that resist simple verification. To address this gap, we introduce DeepResearch-ReportEval, a comprehensive framework designed to assess DeepResearch systems through their most representative outputs: research reports. Our approach systematically measures three dimensions: quality, redundancy, and factuality, using an innovative LLM-as-a-Judge methodology achieving strong expert concordance. We contribute a standardized benchmark of 100 curated queries spanning 12 real-world categories, enabling systematic capability comparison. Our evaluation of four leading commercial systems reveals distinct design philosophies and performance trade-offs, establishing foundational insights as DeepResearch evolves from information assistants toward intelligent research partners. Source code and data are available at: https://github.com/HKUDS/DeepResearch-Eval.
Generative Frame Sampler for Long Video Understanding
Mar 12, 2025



Despite recent advances in Video Large Language Models (VideoLLMs), effectively understanding long-form videos remains a significant challenge. Perceiving lengthy videos containing thousands of frames poses substantial computational burden. To mitigate this issue, this paper introduces Generative Frame Sampler (GenS), a plug-and-play module integrated with VideoLLMs to facilitate efficient lengthy video perception. Built upon a lightweight VideoLLM, GenS leverages its inherent vision-language capabilities to identify question-relevant frames. To facilitate effective retrieval, we construct GenS-Video-150K, a large-scale video instruction dataset with dense frame relevance annotations. Extensive experiments demonstrate that GenS consistently boosts the performance of various VideoLLMs, including open-source models (Qwen2-VL-7B, Aria-25B, VILA-40B, LLaVA-Video-7B/72B) and proprietary assistants (GPT-4o, Gemini). When equipped with GenS, open-source VideoLLMs achieve impressive state-of-the-art results on long-form video benchmarks: LLaVA-Video-72B reaches 66.8 (+4.3) on LongVideoBench and 77.0 (+2.7) on MLVU, while Aria obtains 39.2 on HourVideo surpassing the Gemini-1.5-pro by 1.9 points. We will release all datasets and models at https://generative-sampler.github.io.
ProBench: Judging Multimodal Foundation Models on Open-ended Multi-domain Expert Tasks
Mar 10, 2025Solving expert-level multimodal tasks is a key milestone towards general intelligence. As the capabilities of multimodal large language models (MLLMs) continue to improve, evaluation of such advanced multimodal intelligence becomes necessary yet challenging. In this work, we introduce ProBench, a benchmark of open-ended user queries that require professional expertise and advanced reasoning. ProBench consists of 4,000 high-quality samples independently submitted by professionals based on their daily productivity demands. It spans across 10 fields and 56 sub-fields, including science, arts, humanities, coding, mathematics, and creative writing. Experimentally, we evaluate and compare 24 latest models using MLLM-as-a-Judge. Our results reveal that although the best open-source models rival the proprietary ones, ProBench presents significant challenges in visual perception, textual understanding, domain knowledge and advanced reasoning, thus providing valuable directions for future multimodal AI research efforts.
Aria-UI: Visual Grounding for GUI Instructions
Dec 20, 2024



Digital agents for automating tasks across different platforms by directly manipulating the GUIs are increasingly important. For these agents, grounding from language instructions to target elements remains a significant challenge due to reliance on HTML or AXTree inputs. In this paper, we introduce Aria-UI, a large multimodal model specifically designed for GUI grounding. Aria-UI adopts a pure-vision approach, eschewing reliance on auxiliary inputs. To adapt to heterogeneous planning instructions, we propose a scalable data pipeline that synthesizes diverse and high-quality instruction samples for grounding. To handle dynamic contexts in task performing, Aria-UI incorporates textual and text-image interleaved action histories, enabling robust context-aware reasoning for grounding. Aria-UI sets new state-of-the-art results across offline and online agent benchmarks, outperforming both vision-only and AXTree-reliant baselines. We release all training data and model checkpoints to foster further research at https://ariaui.github.io.
Yi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.