 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePM-KVQ: Progressive Mixed-precision KV Cache Quantization for Long-CoT LLMs
May 24, 2025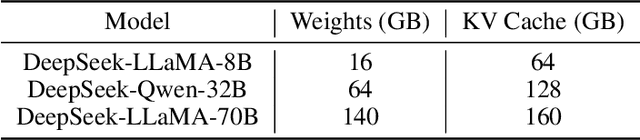
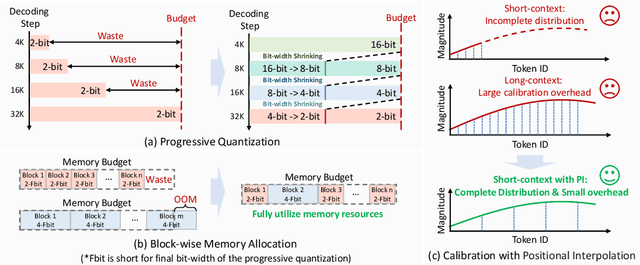


Recently, significant progress has been made in developing reasoning-capable Large Language Models (LLMs) through long Chain-of-Thought (CoT) techniques. However, this long-CoT reasoning process imposes substantial memory overhead due to the large Key-Value (KV) Cache memory overhead. Post-training KV Cache quantization has emerged as a promising compression technique and has been extensively studied in short-context scenarios. However, directly applying existing methods to long-CoT LLMs causes significant performance degradation due to the following two reasons: (1) Large cumulative error: Existing methods fail to adequately leverage available memory, and they directly quantize the KV Cache during each decoding step, leading to large cumulative quantization error. (2) Short-context calibration: Due to Rotary Positional Embedding (RoPE), the use of short-context data during calibration fails to account for the distribution of less frequent channels in the Key Cache, resulting in performance loss. We propose Progressive Mixed-Precision KV Cache Quantization (PM-KVQ) for long-CoT LLMs to address the above issues in two folds: (1) To reduce cumulative error, we design a progressive quantization strategy to gradually lower the bit-width of KV Cache in each block. Then, we propose block-wise memory allocation to assign a higher bit-width to more sensitive transformer blocks. (2) To increase the calibration length without additional overhead, we propose a new calibration strategy with positional interpolation that leverages short calibration data with positional interpolation to approximate the data distribution of long-context data. Extensive experiments on 7B-70B long-CoT LLMs show that PM-KVQ improves reasoning benchmark performance by up to 8% over SOTA baselines under the same memory budget. Our code is available at https://github.com/thu-nics/PM-KVQ.
Bridging the Dynamic Perception Gap: Training-Free Draft Chain-of-Thought for Dynamic Multimodal Spatial Reasoning
May 22, 2025While chains-of-thought (CoT) have advanced complex reasoning in multimodal large language models (MLLMs), existing methods remain confined to text or static visual domains, often faltering in dynamic spatial reasoning tasks. To bridge this gap, we present GRASSLAND, a novel maze navigation benchmark designed to evaluate dynamic spatial reasoning. Our experiments show that augmenting textual reasoning chains with dynamic visual drafts, overlaid on input images, significantly outperforms conventional approaches, offering new insights into spatial reasoning in evolving environments. To generalize this capability, we propose D2R (Dynamic Draft-Augmented Reasoning), a training-free framework that seamlessly integrates textual CoT with corresponding visual drafts into MLLMs. Extensive evaluations demonstrate that D2R consistently enhances performance across diverse tasks, establishing a robust baseline for dynamic spatial reasoning without requiring model fine-tuning. Project is open at https://github.com/Cratileo/D2R.
LLM Access Shield: Domain-Specific LLM Framework for Privacy Policy Compliance
May 22, 2025Large language models (LLMs) are increasingly applied in fields such as finance, education, and governance due to their ability to generate human-like text and adapt to specialized tasks. However, their widespread adoption raises critical concerns about data privacy and security, including the risk of sensitive data exposure. In this paper, we propose a security framework to enforce policy compliance and mitigate risks in LLM interactions. Our approach introduces three key innovations: (i) LLM-based policy enforcement: a customizable mechanism that enhances domain-specific detection of sensitive data. (ii) Dynamic policy customization: real-time policy adaptation and enforcement during user-LLM interactions to ensure compliance with evolving security requirements. (iii) Sensitive data anonymization: a format-preserving encryption technique that protects sensitive information while maintaining contextual integrity. Experimental results demonstrate that our framework effectively mitigates security risks while preserving the functional accuracy of LLM-driven tasks.
VocalBench: Benchmarking the Vocal Conversational Abilities for Speech Interaction Models
May 21, 2025The rapid advancement of large language models (LLMs) has accelerated the development of multi-modal models capable of vocal communication. Unlike text-based interactions, speech conveys rich and diverse information, including semantic content, acoustic variations, paralanguage cues, and environmental context. However, existing evaluations of speech interaction models predominantly focus on the quality of their textual responses, often overlooking critical aspects of vocal performance and lacking benchmarks with vocal-specific test instances. To address this gap, we propose VocalBench, a comprehensive benchmark designed to evaluate speech interaction models' capabilities in vocal communication. VocalBench comprises 9,400 carefully curated instances across four key dimensions: semantic quality, acoustic performance, conversational abilities, and robustness. It covers 16 fundamental skills essential for effective vocal interaction. Experimental results reveal significant variability in current model capabilities, each exhibiting distinct strengths and weaknesses, and provide valuable insights to guide future research in speech-based interaction systems. Code and evaluation instances are available at https://github.com/SJTU-OmniAgent/VocalBench.
EfficientLLM: Efficiency in Large Language Models
May 20, 2025Large Language Models (LLMs) have driven significant progress, yet their growing parameter counts and context windows incur prohibitive compute, energy, and monetary costs. We introduce EfficientLLM, a novel benchmark and the first comprehensive empirical study evaluating efficiency techniques for LLMs at scale. Conducted on a production-class cluster (48xGH200, 8xH200 GPUs), our study systematically explores three key axes: (1) architecture pretraining (efficient attention variants: MQA, GQA, MLA, NSA; sparse Mixture-of-Experts (MoE)), (2) fine-tuning (parameter-efficient methods: LoRA, RSLoRA, DoRA), and (3) inference (quantization methods: int4, float16). We define six fine-grained metrics (Memory Utilization, Compute Utilization, Latency, Throughput, Energy Consumption, Compression Rate) to capture hardware saturation, latency-throughput balance, and carbon cost. Evaluating over 100 model-technique pairs (0.5B-72B parameters), we derive three core insights: (i) Efficiency involves quantifiable trade-offs: no single method is universally optimal; e.g., MoE reduces FLOPs and improves accuracy but increases VRAM by 40%, while int4 quantization cuts memory/energy by up to 3.9x at a 3-5% accuracy drop. (ii) Optima are task- and scale-dependent: MQA offers optimal memory-latency trade-offs for constrained devices, MLA achieves lowest perplexity for quality-critical tasks, and RSLoRA surpasses LoRA efficiency only beyond 14B parameters. (iii) Techniques generalize across modalities: we extend evaluations to Large Vision Models (Stable Diffusion 3.5, Wan 2.1) and Vision-Language Models (Qwen2.5-VL), confirming effective transferability. By open-sourcing datasets, evaluation pipelines, and leaderboards, EfficientLLM provides essential guidance for researchers and engineers navigating the efficiency-performance landscape of next-generation foundation models.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
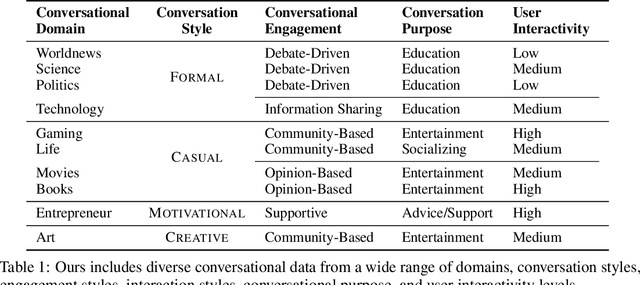


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
MoRAL: Motion-aware Multi-Frame 4D Radar and LiDAR Fusion for Robust 3D Object Detection
May 14, 2025Reliable autonomous driving systems require accurate detection of traffic participants. To this end, multi-modal fusion has emerged as an effective strategy. In particular, 4D radar and LiDAR fusion methods based on multi-frame radar point clouds have demonstrated the effectiveness in bridging the point density gap. However, they often neglect radar point clouds' inter-frame misalignment caused by object movement during accumulation and do not fully exploit the object dynamic information from 4D radar. In this paper, we propose MoRAL, a motion-aware multi-frame 4D radar and LiDAR fusion framework for robust 3D object detection. First, a Motion-aware Radar Encoder (MRE) is designed to compensate for inter-frame radar misalignment from moving objects. Later, a Motion Attention Gated Fusion (MAGF) module integrate radar motion features to guide LiDAR features to focus on dynamic foreground objects. Extensive evaluations on the View-of-Delft (VoD) dataset demonstrate that MoRAL outperforms existing methods, achieving the highest mAP of 73.30% in the entire area and 88.68% in the driving corridor. Notably, our method also achieves the best AP of 69.67% for pedestrians in the entire area and 96.25% for cyclists in the driving corridor.
The Sound of Populism: Distinct Linguistic Features Across Populist Variants
May 10, 2025This study explores the sound of populism by integrating the classic Linguistic Inquiry and Word Count (LIWC) features, which capture the emotional and stylistic tones of language, with a fine-tuned RoBERTa model, a state-of-the-art context-aware language model trained to detect nuanced expressions of populism. This approach allows us to uncover the auditory dimensions of political rhetoric in U.S. presidential inaugural and State of the Union addresses. We examine how four key populist dimensions (i.e., left-wing, right-wing, anti-elitism, and people-centrism) manifest in the linguistic markers of speech, drawing attention to both commonalities and distinct tonal shifts across these variants. Our findings reveal that populist rhetoric consistently features a direct, assertive ``sound" that forges a connection with ``the people'' and constructs a charismatic leadership persona. However, this sound is not simply informal but strategically calibrated. Notably, right-wing populism and people-centrism exhibit a more emotionally charged discourse, resonating with themes of identity, grievance, and crisis, in contrast to the relatively restrained emotional tones of left-wing and anti-elitist expressions.
Mastering Multi-Drone Volleyball through Hierarchical Co-Self-Play Reinforcement Learning
May 07, 2025In this paper, we tackle the problem of learning to play 3v3 multi-drone volleyball, a new embodied competitive task that requires both high-level strategic coordination and low-level agile control. The task is turn-based, multi-agent, and physically grounded, posing significant challenges due to its long-horizon dependencies, tight inter-agent coupling, and the underactuated dynamics of quadrotors. To address this, we propose Hierarchical Co-Self-Play (HCSP), a hierarchical reinforcement learning framework that separates centralized high-level strategic decision-making from decentralized low-level motion control. We design a three-stage population-based training pipeline to enable both strategy and skill to emerge from scratch without expert demonstrations: (I) training diverse low-level skills, (II) learning high-level strategy via self-play with fixed low-level controllers, and (III) joint fine-tuning through co-self-play. Experiments show that HCSP achieves superior performance, outperforming non-hierarchical self-play and rule-based hierarchical baselines with an average 82.9\% win rate and a 71.5\% win rate against the two-stage variant. Moreover, co-self-play leads to emergent team behaviors such as role switching and coordinated formations, demonstrating the effectiveness of our hierarchical design and training scheme.
RM-R1: Reward Modeling as Reasoning
May 05, 2025Reward modeling is essential for aligning large language models (LLMs) with human preferences, especially through reinforcement learning from human feedback (RLHF). To provide accurate reward signals, a reward model (RM) should stimulate deep thinking and conduct interpretable reasoning before assigning a score or a judgment. However, existing RMs either produce opaque scalar scores or directly generate the prediction of a preferred answer, making them struggle to integrate natural language critiques, thus lacking interpretability. Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we hypothesize and validate that integrating reasoning capabilities into reward modeling significantly enhances RM's interpretability and performance. In this work, we introduce a new class of generative reward models -- Reasoning Reward Models (ReasRMs) -- which formulate reward modeling as a reasoning task. We propose a reasoning-oriented training pipeline and train a family of ReasRMs, RM-R1. The training consists of two key stages: (1) distillation of high-quality reasoning chains and (2) reinforcement learning with verifiable rewards. RM-R1 improves LLM rollouts by self-generating reasoning traces or chat-specific rubrics and evaluating candidate responses against them. Empirically, our models achieve state-of-the-art or near state-of-the-art performance of generative RMs across multiple comprehensive reward model benchmarks, outperforming much larger open-weight models (e.g., Llama3.1-405B) and proprietary ones (e.g., GPT-4o) by up to 13.8%. Beyond final performance, we perform thorough empirical analysis to understand the key ingredients of successful ReasRM training. To facilitate future research, we release six ReasRM models along with code and data at https://github.com/RM-R1-UIUC/RM-R1.