 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
Paper and Code
May 20, 2025
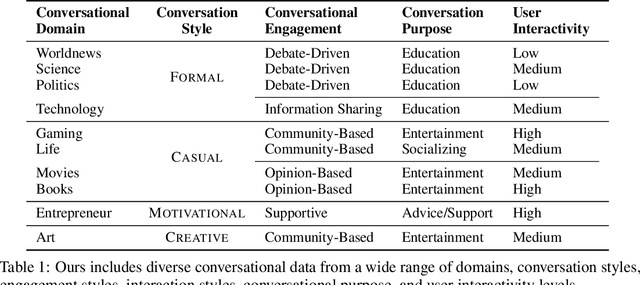


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.