 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaSR: Context-Aware Speech Recognition via Latent Reasoning
May 30, 2026Recent advances in Speech Large Language Models (Speech LLMs) have significantly enhanced spoken language understanding and reasoning. However, their contextual awareness is limited, struggling to perform speech recognition that effectively reflects the speaker's intent and topical context. In this paper, we propose LaSR (Latent Speech Reasoning), a novel training paradigm featuring a context-aware reasoning trajectory that leverages the latent reasoning process. Instead of generating explicit intermediate tokens, LaSR aligns chain-of-thought (CoT) supervision around the acoustic feature region of the targeted word, and introduces latent reasoning periods for context information grounding and transcriptional transition. Furthermore, to effectively benchmark contextual recognition on specialized vocabulary, we propose Spoken Darwin-Science, a large-scale corpus focusing on academic terminologies. Preliminary experiments on Fun-Audio-Chat demonstrate that LaSR significantly improves terminology recognition without introducing additional latency and consistently outperforms standard supervised fine-tuning baselines. Our findings highlight the potential of latent reasoning in building efficient, context-aware speech assistants.
Adaptive Learned Image Compression with Graph Neural Networks
Mar 26, 2026Efficient image compression relies on modeling both local and global redundancy. Most state-of-the-art (SOTA) learned image compression (LIC) methods are based on CNNs or Transformers, which are inherently rigid. Standard CNN kernels and window-based attention mechanisms impose fixed receptive fields and static connectivity patterns, which potentially couple non-redundant pixels simply due to their proximity in Euclidean space. This rigidity limits the model's ability to adaptively capture spatially varying redundancy across the image, particularly at the global level. To overcome these limitations, we propose a content-adaptive image compression framework based on Graph Neural Networks (GNNs). Specifically, our approach constructs dual-scale graphs that enable flexible, data-driven receptive fields. Furthermore, we introduce adaptive connectivity by dynamically adjusting the number of neighbors for each node based on local content complexity. These innovations empower our Graph-based Learned Image Compression (GLIC) model to effectively model diverse redundancy patterns across images, leading to more efficient and adaptive compression. Experiments demonstrate that GLIC achieves state-of-the-art performance, achieving BD-rate reductions of 19.29%, 21.69%, and 18.71% relative to VTM-9.1 on Kodak, Tecnick, and CLIC, respectively. Code will be released at https://github.com/UnoC-727/GLIC.
OmniZip: Learning a Unified and Lightweight Lossless Compressor for Multi-Modal Data
Feb 25, 2026Lossless compression is essential for efficient data storage and transmission. Although learning-based lossless compressors achieve strong results, most of them are designed for a single modality, leading to redundant compressor deployments in multi-modal settings. Designing a unified multi-modal compressor is critical yet challenging, as different data types vary largely in format, dimension, and statistics. Multi-modal large language models offer a promising resolution but remain too complex for practical use. Thus, we propose \textbf{OmniZip}, \textbf{a unified and lightweight lossless compressor for multi-modal data (like image, text, speech, tactile, database, and gene sequence)}. Built on a lightweight backbone, OmniZip incorporates three key components to enable efficient multi-modal lossless compression: a modality-unified tokenizer that reversibly transforms diverse data into tokens, a modality-routing context learning mechanism that enables flexible multi-modal context modeling, and a modality-routing feedforward design that further enhances the model's nonlinear representation flexibility. A reparameterization training strategy is used to enhance model capacity. OmniZip outperforms or matches other state-of-the-art compressors on multiple modalities, achieving 42\%, 57\%, 62\% and 42\%, 53\% higher compression efficiency than gzip on CLIC-M, TouchandGo, enwik9, LibriSpeech, and WikiSQL datasets, respectively. It also supports near real-time inference on resource-constrained edge devices, reaching about 1MB/s on MacBook CPUs and iPhone NPUs. Our code is released at https://github.com/adminasmi/OmniZip-CVPR2026.
VocalNet-MDM: Accelerating Streaming Speech LLM via Self-Distilled Masked Diffusion Modeling
Feb 09, 2026Recent Speech Large Language Models~(LLMs) have achieved impressive capabilities in end-to-end speech interaction. However, the prevailing autoregressive paradigm imposes strict serial constraints, limiting generation efficiency and introducing exposure bias. In this paper, we investigate Masked Diffusion Modeling~(MDM) as a non-autoregressive paradigm for speech LLMs and introduce VocalNet-MDM. To adapt MDM for streaming speech interaction, we address two critical challenges: training-inference mismatch and iterative overhead. We propose Hierarchical Block-wise Masking to align training objectives with the progressive masked states encountered during block diffusion decoding, and Iterative Self-Distillation to compress multi-step refinement into fewer steps for low-latency inference. Trained on a limited scale of only 6K hours of speech data, VocalNet-MDM achieves a 3.7$\times$--10$\times$ decoding speedup and reduces first-chunk latency by 34\% compared to AR baselines. It maintains competitive recognition accuracy while achieving state-of-the-art text quality and speech naturalness, demonstrating that MDM is a promising and scalable alternative for low-latency, efficient speech LLMs.
VocalBench-zh: Decomposing and Benchmarking the Speech Conversational Abilities in Mandarin Context
Nov 17, 2025



The development of multi-modal large language models (LLMs) leads to intelligent approaches capable of speech interactions. As one of the most widely spoken languages globally, Mandarin is supported by most models to enhance their applicability and reach. However, the scarcity of comprehensive speech-to-speech (S2S) benchmarks in Mandarin contexts impedes systematic evaluation for developers and hinders fair model comparison for users. In this work, we propose VocalBench-zh, an ability-level divided evaluation suite adapted to Mandarin context consisting of 10 well-crafted subsets and over 10K high-quality instances, covering 12 user-oriented characters. The evaluation experiment on 14 mainstream models reveals the common challenges for current routes, and highlights the need for new insights into next-generation speech interactive systems. The evaluation codes and datasets will be available at https://github.com/SJTU-OmniAgent/VocalBench-zh.
VocalNet-M2: Advancing Low-Latency Spoken Language Modeling via Integrated Multi-Codebook Tokenization and Multi-Token Prediction
Nov 13, 2025Current end-to-end spoken language models (SLMs) have made notable progress, yet they still encounter considerable response latency. This delay primarily arises from the autoregressive generation of speech tokens and the reliance on complex flow-matching models for speech synthesis. To overcome this, we introduce VocalNet-M2, a novel low-latency SLM that integrates a multi-codebook tokenizer and a multi-token prediction (MTP) strategy. Our model directly generates multi-codebook speech tokens, thus eliminating the need for a latency-inducing flow-matching model. Furthermore, our MTP strategy enhances generation efficiency and improves overall performance. Extensive experiments demonstrate that VocalNet-M2 achieves a substantial reduction in first chunk latency (from approximately 725ms to 350ms) while maintaining competitive performance across mainstream SLMs. This work also provides a comprehensive comparison of single-codebook and multi-codebook strategies, offering valuable insights for developing efficient and high-performance SLMs for real-time interactive applications.
CS3-Bench: Evaluating and Enhancing Speech-to-Speech LLMs for Mandarin-English Code-Switching
Oct 09, 2025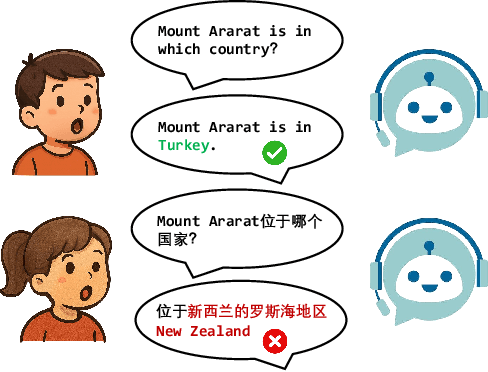

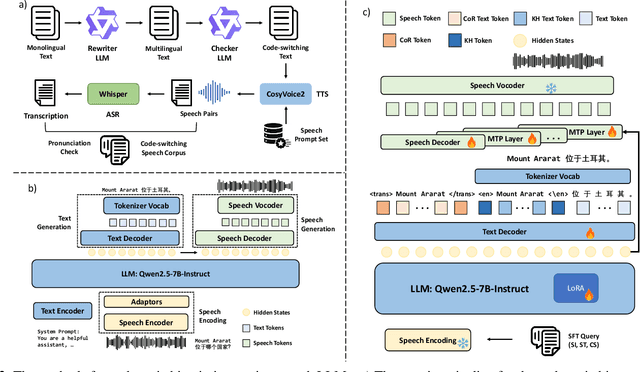
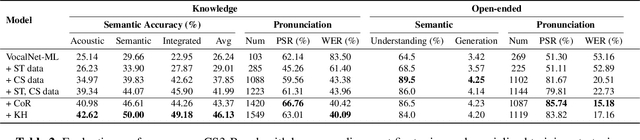
The advancement of multimodal large language models has accelerated the development of speech-to-speech interaction systems. While natural monolingual interaction has been achieved, we find existing models exhibit deficiencies in language alignment. In our proposed Code-Switching Speech-to-Speech Benchmark (CS3-Bench), experiments on 7 mainstream models demonstrate a relative performance drop of up to 66% in knowledge-intensive question answering and varying degrees of misunderstanding in open-ended conversations. Starting from a model with severe performance deterioration, we propose both data constructions and training approaches to improve the language alignment capabilities, specifically employing Chain of Recognition (CoR) to enhance understanding and Keyword Highlighting (KH) to guide generation. Our approach improves the knowledge accuracy from 25.14% to 46.13%, with open-ended understanding rate from 64.5% to 86.5%, and significantly reduces pronunciation errors in the secondary language. CS3-Bench is available at https://huggingface.co/datasets/VocalNet/CS3-Bench.
DualComp: End-to-End Learning of a Unified Dual-Modality Lossless Compressor
May 22, 2025Most learning-based lossless compressors are designed for a single modality, requiring separate models for multi-modal data and lacking flexibility. However, different modalities vary significantly in format and statistical properties, making it ineffective to use compressors that lack modality-specific adaptations. While multi-modal large language models (MLLMs) offer a potential solution for modality-unified compression, their excessive complexity hinders practical deployment. To address these challenges, we focus on the two most common modalities, image and text, and propose DualComp, the first unified and lightweight learning-based dual-modality lossless compressor. Built on a lightweight backbone, DualComp incorporates three key structural enhancements to handle modality heterogeneity: modality-unified tokenization, modality-switching contextual learning, and modality-routing mixture-of-experts. A reparameterization training strategy is also used to boost compression performance. DualComp integrates both modality-specific and shared parameters for efficient parameter utilization, enabling near real-time inference (200KB/s) on desktop CPUs. With much fewer parameters, DualComp achieves compression performance on par with the SOTA LLM-based methods for both text and image datasets. Its simplified single-modality variant surpasses the previous best image compressor on the Kodak dataset by about 9% using just 1.2% of the model size.
VocalBench: Benchmarking the Vocal Conversational Abilities for Speech Interaction Models
May 21, 2025The rapid advancement of large language models (LLMs) has accelerated the development of multi-modal models capable of vocal communication. Unlike text-based interactions, speech conveys rich and diverse information, including semantic content, acoustic variations, paralanguage cues, and environmental context. However, existing evaluations of speech interaction models predominantly focus on the quality of their textual responses, often overlooking critical aspects of vocal performance and lacking benchmarks with vocal-specific test instances. To address this gap, we propose VocalBench, a comprehensive benchmark designed to evaluate speech interaction models' capabilities in vocal communication. VocalBench comprises 9,400 carefully curated instances across four key dimensions: semantic quality, acoustic performance, conversational abilities, and robustness. It covers 16 fundamental skills essential for effective vocal interaction. Experimental results reveal significant variability in current model capabilities, each exhibiting distinct strengths and weaknesses, and provide valuable insights to guide future research in speech-based interaction systems. Code and evaluation instances are available at https://github.com/SJTU-OmniAgent/VocalBench.
VocalNet: Speech LLM with Multi-Token Prediction for Faster and High-Quality Generation
Apr 05, 2025Speech large language models (LLMs) have emerged as a prominent research focus in speech processing. We propose VocalNet-1B and VocalNet-8B, a series of high-performance, low-latency speech LLMs enabled by a scalable and model-agnostic training framework for real-time voice interaction. Departing from the conventional next-token prediction (NTP), we introduce multi-token prediction (MTP), a novel approach optimized for speech LLMs that simultaneously improves generation speed and quality. Experiments show that VocalNet outperforms mainstream Omni LLMs despite using significantly less training data, while also surpassing existing open-source speech LLMs by a substantial margin. To support reproducibility and community advancement, we will open-source all model weights, inference code, training data, and framework implementations upon publication.