 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Combinatorial Reasoning of GNNs via Graph Concept Bottleneck Layer
Mar 02, 2026Despite their success in various domains, the growing dependence on GNNs raises a critical concern about the nature of the combinatorial reasoning underlying their predictions, which is often hidden within their black-box architectures. Addressing this challenge requires understanding how GNNs translate topological patterns into logical rules. However, current works only uncover the hard logical rules over graph concepts, which cannot quantify the contribution of each concept to prediction. Moreover, they are post-hoc interpretable methods that generate explanations after model training and may not accurately reflect the true combinatorial reasoning of GNNs, since they approximate it with a surrogate. In this work, we develop a graph concept bottleneck layer that can be integrated into any GNN architectures to guide them to predict the selected discriminative global graph concepts. The predicted concept scores are further projected to class labels by a sparse linear layer. It enforces the combinatorial reasoning of GNNs' predictions to fit the soft logical rule over graph concepts and thus can quantify the contribution of each concept. To further improve the quality of the concept bottleneck, we treat concepts as "graph words" and graphs as "graph sentences", and leverage language models to learn graph concept embeddings. Extensive experiments on multiple datasets show that our method GCBMs achieve state-of-the-art performance both in classification and interpretability.
PM-KVQ: Progressive Mixed-precision KV Cache Quantization for Long-CoT LLMs
May 24, 2025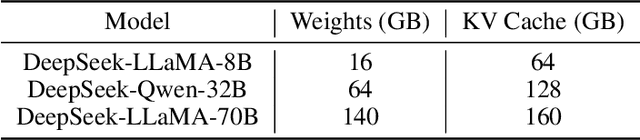
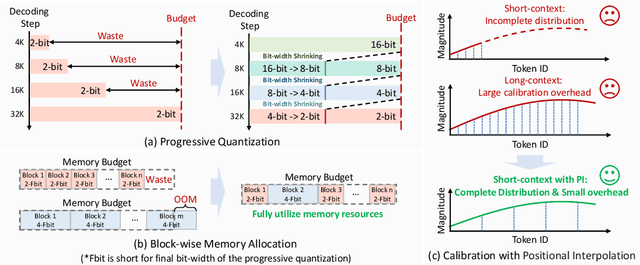


Recently, significant progress has been made in developing reasoning-capable Large Language Models (LLMs) through long Chain-of-Thought (CoT) techniques. However, this long-CoT reasoning process imposes substantial memory overhead due to the large Key-Value (KV) Cache memory overhead. Post-training KV Cache quantization has emerged as a promising compression technique and has been extensively studied in short-context scenarios. However, directly applying existing methods to long-CoT LLMs causes significant performance degradation due to the following two reasons: (1) Large cumulative error: Existing methods fail to adequately leverage available memory, and they directly quantize the KV Cache during each decoding step, leading to large cumulative quantization error. (2) Short-context calibration: Due to Rotary Positional Embedding (RoPE), the use of short-context data during calibration fails to account for the distribution of less frequent channels in the Key Cache, resulting in performance loss. We propose Progressive Mixed-Precision KV Cache Quantization (PM-KVQ) for long-CoT LLMs to address the above issues in two folds: (1) To reduce cumulative error, we design a progressive quantization strategy to gradually lower the bit-width of KV Cache in each block. Then, we propose block-wise memory allocation to assign a higher bit-width to more sensitive transformer blocks. (2) To increase the calibration length without additional overhead, we propose a new calibration strategy with positional interpolation that leverages short calibration data with positional interpolation to approximate the data distribution of long-context data. Extensive experiments on 7B-70B long-CoT LLMs show that PM-KVQ improves reasoning benchmark performance by up to 8% over SOTA baselines under the same memory budget. Our code is available at https://github.com/thu-nics/PM-KVQ.
ChangeDiff: A Multi-Temporal Change Detection Data Generator with Flexible Text Prompts via Diffusion Model
Dec 20, 2024



Data-driven deep learning models have enabled tremendous progress in change detection (CD) with the support of pixel-level annotations. However, collecting diverse data and manually annotating them is costly, laborious, and knowledge-intensive. Existing generative methods for CD data synthesis show competitive potential in addressing this issue but still face the following limitations: 1) difficulty in flexibly controlling change events, 2) dependence on additional data to train the data generators, 3) focus on specific change detection tasks. To this end, this paper focuses on the semantic CD (SCD) task and develops a multi-temporal SCD data generator ChangeDiff by exploring powerful diffusion models. ChangeDiff innovatively generates change data in two steps: first, it uses text prompts and a text-to-layout (T2L) model to create continuous layouts, and then it employs layout-to-image (L2I) to convert these layouts into images. Specifically, we propose multi-class distribution-guided text prompts (MCDG-TP), allowing for layouts to be generated flexibly through controllable classes and their corresponding ratios. Subsequently, to generalize the T2L model to the proposed MCDG-TP, a class distribution refinement loss is further designed as training supervision. %For the former, a multi-classdistribution-guided text prompt (MCDG-TP) is proposed to complement via controllable classes and ratios. To generalize the text-to-image diffusion model to the proposed MCDG-TP, a class distribution refinement loss is designed as training supervision. For the latter, MCDG-TP in three modes is proposed to synthesize new layout masks from various texts. Our generated data shows significant progress in temporal continuity, spatial diversity, and quality realism, empowering change detectors with accuracy and transferability. The code is available at https://github.com/DZhaoXd/ChangeDiff
PICNN: A Pathway towards Interpretable Convolutional Neural Networks
Dec 19, 2023Convolutional Neural Networks (CNNs) have exhibited great performance in discriminative feature learning for complex visual tasks. Besides discrimination power, interpretability is another important yet under-explored property for CNNs. One difficulty in the CNN interpretability is that filters and image classes are entangled. In this paper, we introduce a novel pathway to alleviate the entanglement between filters and image classes. The proposed pathway groups the filters in a late conv-layer of CNN into class-specific clusters. Clusters and classes are in a one-to-one relationship. Specifically, we use the Bernoulli sampling to generate the filter-cluster assignment matrix from a learnable filter-class correspondence matrix. To enable end-to-end optimization, we develop a novel reparameterization trick for handling the non-differentiable Bernoulli sampling. We evaluate the effectiveness of our method on ten widely used network architectures (including nine CNNs and a ViT) and five benchmark datasets. Experimental results have demonstrated that our method PICNN (the combination of standard CNNs with our proposed pathway) exhibits greater interpretability than standard CNNs while achieving higher or comparable discrimination power.
Incorporating Heterophily into Graph Neural Networks for Graph Classification
Mar 15, 2022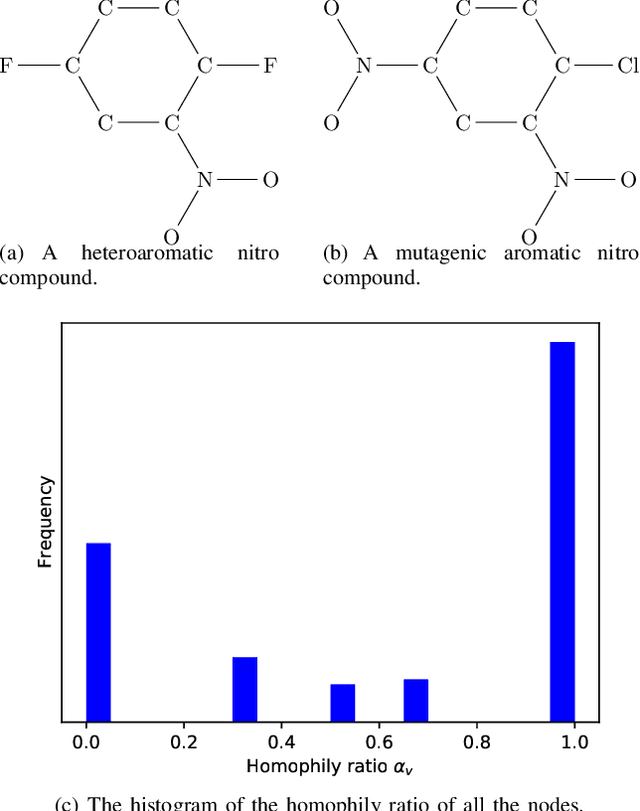
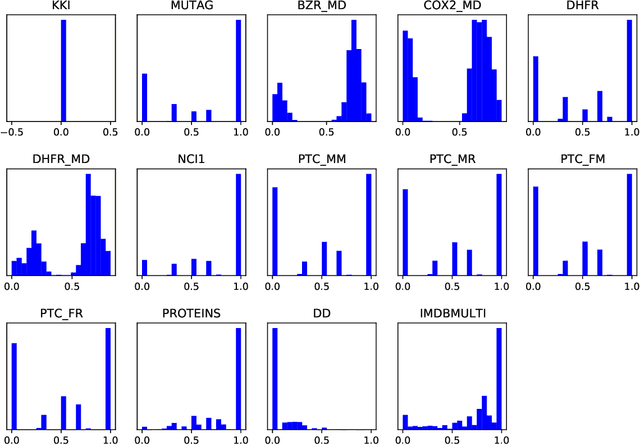
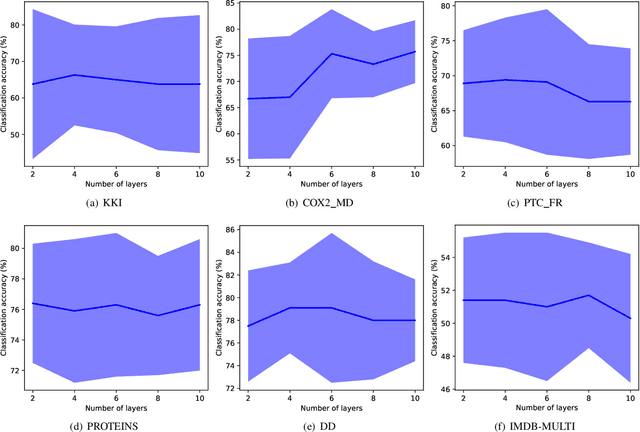
Graph neural networks (GNNs) often assume strong homophily in graphs, seldom considering heterophily which means connected nodes tend to have different class labels and dissimilar features. In real-world scenarios, graphs may have nodes that exhibit both homophily and heterophily. Failing to generalize to this setting makes many GNNs underperform in graph classification. In this paper, we address this limitation by identifying two useful designs and develop a novel GNN architecture called IHGNN (Incorporating Heterophily into Graph Neural Networks). These designs include integration and separation of the ego- and neighbor-embeddings of nodes; and concatenation of all the node embeddings as the final graph-level readout function. In the first design, integration is combined with separation by an injective function which is the composition of the MLP and the concatenation function. The second design enables the graph-level readout function to differentiate between different node embeddings. As the functions used in both the designs are injective, IHGNN, while being simple, has an expressiveness as powerful as the 1-WL. We empirically validate IHGNN on various graph datasets and demonstrate that it achieves state-of-the-art performance on the graph classification task.
Training and Inference for Integer-Based Semantic Segmentation Network
Nov 30, 2020Semantic segmentation has been a major topic in research and industry in recent years. However, due to the computation complexity of pixel-wise prediction and backpropagation algorithm, semantic segmentation has been demanding in computation resources, resulting in slow training and inference speed and large storage space to store models. Existing schemes that speed up segmentation network change the network structure and come with noticeable accuracy degradation. However, neural network quantization can be used to reduce computation load while maintaining comparable accuracy and original network structure. Semantic segmentation networks are different from traditional deep convolutional neural networks (DCNNs) in many ways, and this topic has not been thoroughly explored in existing works. In this paper, we propose a new quantization framework for training and inference of segmentation networks, where parameters and operations are constrained to 8-bit integer-based values for the first time. Full quantization of the data flow and the removal of square and root operations in batch normalization give our framework the ability to perform inference on fixed-point devices. Our proposed framework is evaluated on mainstream semantic segmentation networks like FCN-VGG16 and DeepLabv3-ResNet50, achieving comparable accuracy against floating-point framework on ADE20K dataset and PASCAL VOC 2012 dataset.