 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR-Mamba:Towards Accurate, Adaptive and Trustworthy Multi-Sequence Ophthalmic Angiography Classification
Jan 28, 2026Medical image classification is a core task in computer-aided diagnosis (CAD), playing a pivotal role in early disease detection, treatment planning, and patient prognosis assessment. In ophthalmic practice, fluorescein fundus angiography (FFA) and indocyanine green angiography (ICGA) provide hemodynamic and lesion-structural information that conventional fundus photography cannot capture. However, due to the single-modality nature, subtle lesion patterns, and significant inter-device variability, existing methods still face limitations in generalization and high-confidence prediction. To address these challenges, we propose CLEAR-Mamba, an enhanced framework built upon MedMamba with optimizations in both architecture and training strategy. Architecturally, we introduce HaC, a hypernetwork-based adaptive conditioning layer that dynamically generates parameters according to input feature distributions, thereby improving cross-domain adaptability. From a training perspective, we develop RaP, a reliability-aware prediction scheme built upon evidential uncertainty learning, which encourages the model to emphasize low-confidence samples and improves overall stability and reliability. We further construct a large-scale ophthalmic angiography dataset covering both FFA and ICGA modalities, comprising multiple retinal disease categories for model training and evaluation. Experimental results demonstrate that CLEAR-Mamba consistently outperforms multiple baseline models, including the original MedMamba, across various metrics-showing particular advantages in multi-disease classification and reliability-aware prediction. This study provides an effective solution that balances generalizability and reliability for modality-specific medical image classification tasks.
PM-KVQ: Progressive Mixed-precision KV Cache Quantization for Long-CoT LLMs
May 24, 2025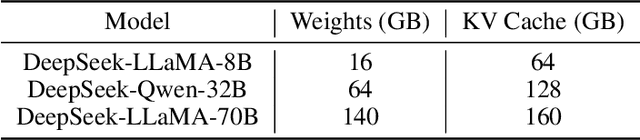
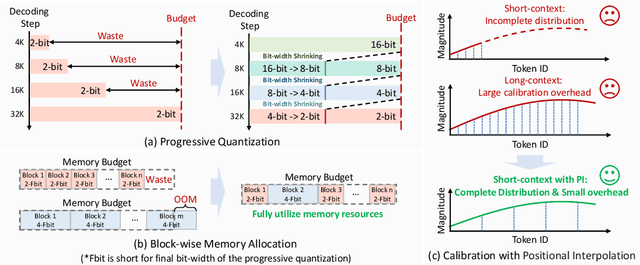


Recently, significant progress has been made in developing reasoning-capable Large Language Models (LLMs) through long Chain-of-Thought (CoT) techniques. However, this long-CoT reasoning process imposes substantial memory overhead due to the large Key-Value (KV) Cache memory overhead. Post-training KV Cache quantization has emerged as a promising compression technique and has been extensively studied in short-context scenarios. However, directly applying existing methods to long-CoT LLMs causes significant performance degradation due to the following two reasons: (1) Large cumulative error: Existing methods fail to adequately leverage available memory, and they directly quantize the KV Cache during each decoding step, leading to large cumulative quantization error. (2) Short-context calibration: Due to Rotary Positional Embedding (RoPE), the use of short-context data during calibration fails to account for the distribution of less frequent channels in the Key Cache, resulting in performance loss. We propose Progressive Mixed-Precision KV Cache Quantization (PM-KVQ) for long-CoT LLMs to address the above issues in two folds: (1) To reduce cumulative error, we design a progressive quantization strategy to gradually lower the bit-width of KV Cache in each block. Then, we propose block-wise memory allocation to assign a higher bit-width to more sensitive transformer blocks. (2) To increase the calibration length without additional overhead, we propose a new calibration strategy with positional interpolation that leverages short calibration data with positional interpolation to approximate the data distribution of long-context data. Extensive experiments on 7B-70B long-CoT LLMs show that PM-KVQ improves reasoning benchmark performance by up to 8% over SOTA baselines under the same memory budget. Our code is available at https://github.com/thu-nics/PM-KVQ.
EyecareGPT: Boosting Comprehensive Ophthalmology Understanding with Tailored Dataset, Benchmark and Model
Apr 18, 2025Medical Large Vision-Language Models (Med-LVLMs) demonstrate significant potential in healthcare, but their reliance on general medical data and coarse-grained global visual understanding limits them in intelligent ophthalmic diagnosis. Currently, intelligent ophthalmic diagnosis faces three major challenges: (i) Data. The lack of deeply annotated, high-quality, multi-modal ophthalmic visual instruction data; (ii) Benchmark. The absence of a comprehensive and systematic benchmark for evaluating diagnostic performance; (iii) Model. The difficulty of adapting holistic visual architectures to fine-grained, region-specific ophthalmic lesion identification. In this paper, we propose the Eyecare Kit, which systematically tackles the aforementioned three key challenges with the tailored dataset, benchmark and model: First, we construct a multi-agent data engine with real-life ophthalmology data to produce Eyecare-100K, a high-quality ophthalmic visual instruction dataset. Subsequently, we design Eyecare-Bench, a benchmark that comprehensively evaluates the overall performance of LVLMs on intelligent ophthalmic diagnosis tasks across multiple dimensions. Finally, we develop the EyecareGPT, optimized for fine-grained ophthalmic visual understanding thoroughly, which incorporates an adaptive resolution mechanism and a layer-wise dense connector. Extensive experimental results indicate that the EyecareGPT achieves state-of-the-art performance in a range of ophthalmic tasks, underscoring its significant potential for the advancement of open research in intelligent ophthalmic diagnosis. Our project is available at https://github.com/DCDmllm/EyecareGPT.
Align Attention Heads Before Merging Them: An Effective Way for Converting MHA to GQA
Dec 30, 2024Large language models have been shown to perform well on a variety of natural language processing problems. However, as the model size and the input sequence's length increase, the rapid increase of KV Cache significantly slows down inference speed. Therefore GQA model, as an alternative to MHA model, has been widely introduced into LLMs. In this work, we propose a low-cost method for pruning MHA models into GQA models with any compression ratio of key-value heads. Our method is based on $\mathit{L_0}$ masks to gradually remove redundant parameters. In addition, we apply orthogonal transformations to attention heads without changing the model to increase similarity between attention heads before pruning training, in order to further improve performance of the model. Our method can be compatible with rotary position embedding (RoPE), which means the model after training can be fully adapted to the mainstream standard GQA framework. Experiments demonstrate that our strategy can compress up to 87.5% of key-value heads of the LLaMA2-7B model without too much performance degradation, just achieved through supervised fine-tuning.
BiLD: Bi-directional Logits Difference Loss for Large Language Model Distillation
Jun 19, 2024In recent years, large language models (LLMs) have shown exceptional capabilities across various natural language processing (NLP) tasks. However, such impressive performance often comes with the trade-off of an increased parameter size, posing significant challenges for widespread deployment. Knowledge distillation (KD) provides a solution by transferring knowledge from a large teacher model to a smaller student model. In this paper, we explore the task-specific distillation of LLMs at the logit level. Our investigation reveals that the logits of fine-tuned LLMs exhibit a more extreme long-tail distribution than those from vision models, with hidden "noise" in the long tail affecting distillation performance. Furthermore, existing logits distillation methods often struggle to effectively utilize the internal ranking information from the logits. To address these, we propose the Bi-directional Logits Difference (BiLD) loss. The BiLD loss filters out the long-tail noise by utilizing only top-$k$ teacher and student logits, and leverages the internal logits ranking information by constructing logits differences. To evaluate BiLD loss, we conduct comprehensive experiments on 13 datasets using two types of LLMs. Our results show that the BiLD loss, with only the top-8 logits, outperforms supervised fine-tuning (SFT), vanilla KL loss, and five other distillation methods from both NLP and CV fields.
Supervised Prototypical Contrastive Learning for Emotion Recognition in Conversation
Oct 19, 2022
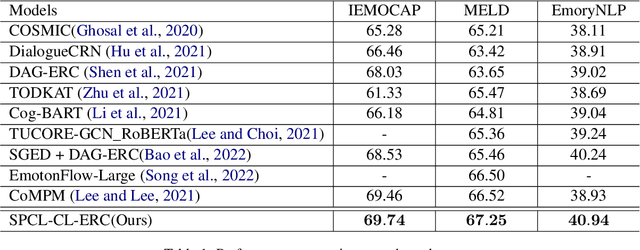
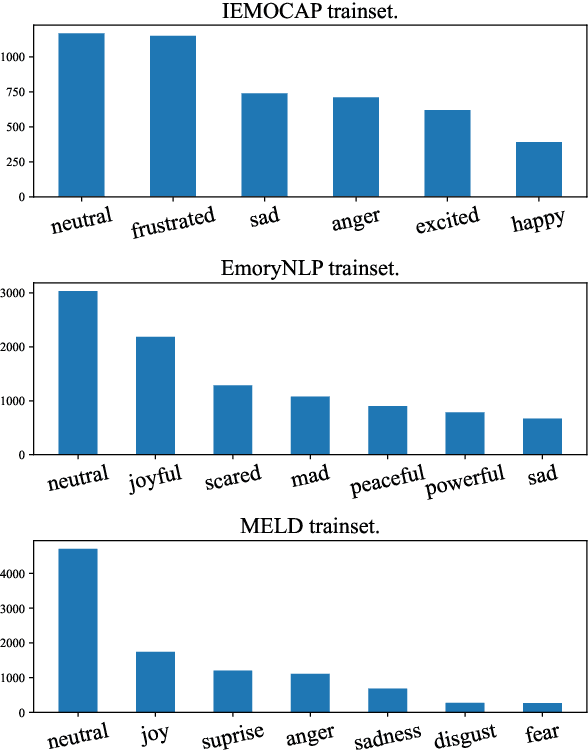
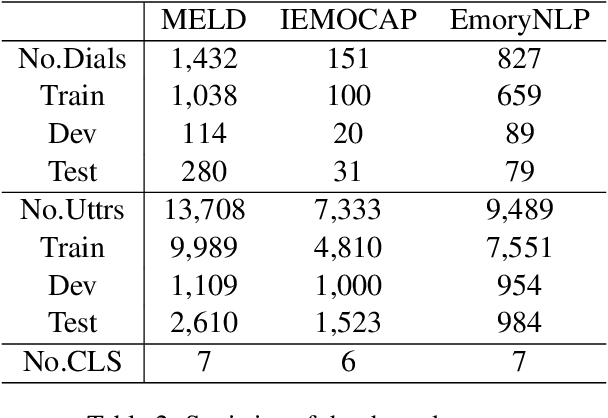
Capturing emotions within a conversation plays an essential role in modern dialogue systems. However, the weak correlation between emotions and semantics brings many challenges to emotion recognition in conversation (ERC). Even semantically similar utterances, the emotion may vary drastically depending on contexts or speakers. In this paper, we propose a Supervised Prototypical Contrastive Learning (SPCL) loss for the ERC task. Leveraging the Prototypical Network, the SPCL targets at solving the imbalanced classification problem through contrastive learning and does not require a large batch size. Meanwhile, we design a difficulty measure function based on the distance between classes and introduce curriculum learning to alleviate the impact of extreme samples. We achieve state-of-the-art results on three widely used benchmarks. Further, we conduct analytical experiments to demonstrate the effectiveness of our proposed SPCL and curriculum learning strategy. We release the code at https://github.com/caskcsg/SPCL.
Data Augmentation for Copy-Mechanism in Dialogue State Tracking
Feb 22, 2020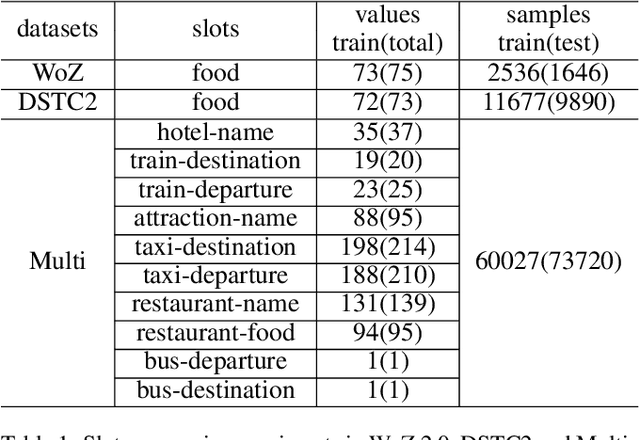
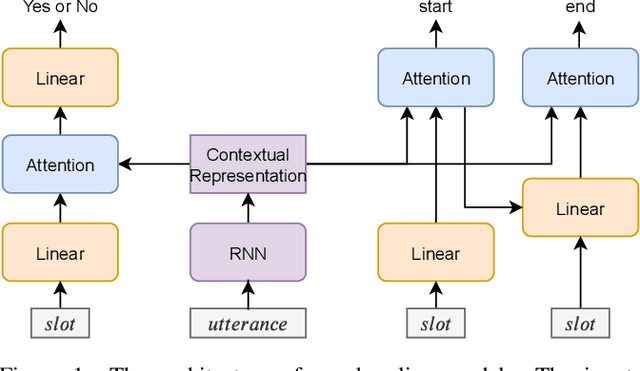
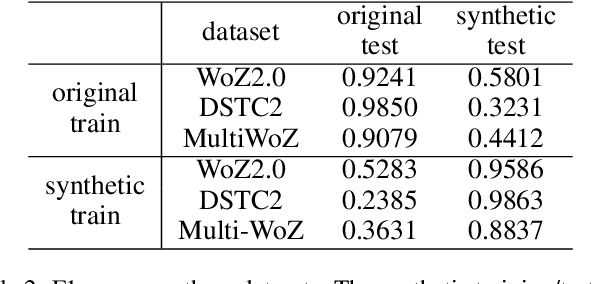
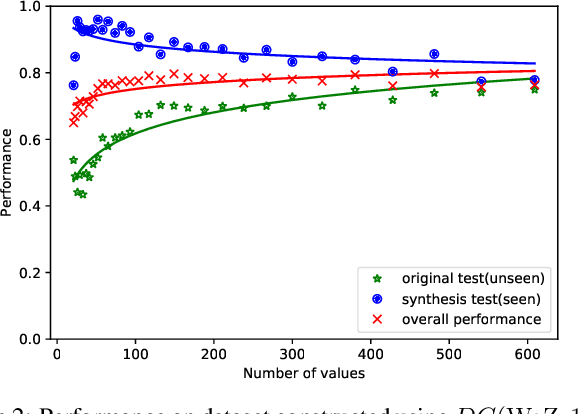
While several state-of-the-art approaches to dialogue state tracking (DST) have shown promising performances on several benchmarks, there is still a significant performance gap between seen slot values (i.e., values that occur in both training set and test set) and unseen ones (values that occur in training set but not in test set). Recently, the copy-mechanism has been widely used in DST models to handle unseen slot values, which copies slot values from user utterance directly. In this paper, we aim to find out the factors that influence the generalization ability of a common copy-mechanism model for DST. Our key observations include: 1) the copy-mechanism tends to memorize values rather than infer them from contexts, which is the primary reason for unsatisfactory generalization performance; 2) greater diversity of slot values in the training set increase the performance on unseen values but slightly decrease the performance on seen values. Moreover, we propose a simple but effective algorithm of data augmentation to train copy-mechanism models, which augments the input dataset by copying user utterances and replacing the real slot values with randomly generated strings. Users could use two hyper-parameters to realize a trade-off between the performances on seen values and unseen ones, as well as a trade-off between overall performance and computational cost. Experimental results on three widely used datasets (WoZ 2.0, DSTC2, and Multi-WoZ 2.0) show the effectiveness of our approach.