 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOG-DPO:Dynamic Optimization in Geometry for Safety Alignment
Jun 04, 2026Safety alignment for large language models relies on preference data, but current pipelines often train on large, redundant datasets. Existing data selection methods typically score each preference pair independently, collapsing directional preference information into scalar quality or diversity scores. This sample-centric view is especially limiting in multi-dataset settings, where shared safety directions coexist with dataset-specific residual risks. We propose DOG-DPO, a training-free data selection framework that treats preference pairs as structured geometric signals. DOG-DPO first represents each preference pair as a direction in model representation space. It then decomposes multi-dataset preference geometry into a global anchor subspace and dataset-specific residual subspaces. Finally, it selects subsets by maximizing diversity-based coverage, encouraging broad, non-redundant coverage of alignment directions before DPO training. Across six safety benchmarks and two model backbones, DOG-DPO achieves a strong utility-robustness trade-off using only 11% of the preference pairs. It recovers most of the safety gains of full-data training while remaining entirely teacher-free, training-free, and substantially faster than representative selection baselines.
CoAct: Co-Active LLM Preference Learning with Human-AI Synergy
Apr 19, 2026Learning from preference-based feedback has become an effective approach for aligning LLMs across diverse tasks. However, high-quality human-annotated preference data remains expensive and scarce. Existing methods address this challenge through either self-rewarding, which scales by using purely AI-generated labels but risks unreliability, or active learning, which ensures quality through oracle annotation but cannot fully leverage unlabeled data. In this paper, we present CoAct, a novel framework that synergistically combines self-rewarding and active learning through strategic human-AI collaboration. CoAct leverages self-consistency to identify both reliable self-labeled data and samples that require oracle verification. Additionally, oracle feedback guides the model to generate new instructions within its solvable capability. Evaluated on three reasoning benchmarks across two model families, CoAct achieves average improvements of +13.25% on GSM8K, +8.19% on MATH, and +13.16% on WebInstruct, consistently outperforming all baselines.
No Attacker Needed: Unintentional Cross-User Contamination in Shared-State LLM Agents
Apr 01, 2026LLM-based agents increasingly operate across repeated sessions, maintaining task states to ensure continuity. In many deployments, a single agent serves multiple users within a team or organization, reusing a shared knowledge layer across user identities. This shared persistence expands the failure surface: information that is locally valid for one user can silently degrade another user's outcome when the agent reapplies it without regard for scope. We refer to this failure mode as unintentional cross-user contamination (UCC). Unlike adversarial memory poisoning, UCC requires no attacker; it arises from benign interactions whose scope-bound artifacts persist and are later misapplied. We formalize UCC through a controlled evaluation protocol, introduce a taxonomy of three contamination types, and evaluate the problem in two shared-state mechanisms. Under raw shared state, benign interactions alone produce contamination rates of 57--71%. A write-time sanitization is effective when shared state is conversational, but leaves substantial residual risk when shared state includes executable artifacts, with contamination often manifesting as silent wrong answers. These results indicate that shared-state agents need artifact-level defenses beyond text-level sanitization to prevent silent cross-user failures.
Ground-Effect-Aware Modeling and Control for Multicopters
Jun 24, 2025The ground effect on multicopters introduces several challenges, such as control errors caused by additional lift, oscillations that may occur during near-ground flight due to external torques, and the influence of ground airflow on models such as the rotor drag and the mixing matrix. This article collects and analyzes the dynamics data of near-ground multicopter flight through various methods, including force measurement platforms and real-world flights. For the first time, we summarize the mathematical model of the external torque of multicopters under ground effect. The influence of ground airflow on rotor drag and the mixing matrix is also verified through adequate experimentation and analysis. Through simplification and derivation, the differential flatness of the multicopter's dynamic model under ground effect is confirmed. To mitigate the influence of these disturbance models on control, we propose a control method that combines dynamic inverse and disturbance models, ensuring consistent control effectiveness at both high and low altitudes. In this method, the additional thrust and variations in rotor drag under ground effect are both considered and compensated through feedforward models. The leveling torque of ground effect can be equivalently represented as variations in the center of gravity and the moment of inertia. In this way, the leveling torque does not explicitly appear in the dynamic model. The final experimental results show that the method proposed in this paper reduces the control error (RMSE) by \textbf{45.3\%}. Please check the supplementary material at: https://github.com/ZJU-FAST-Lab/Ground-effect-controller.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
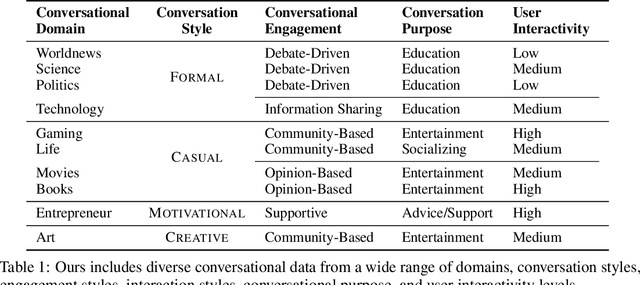


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
AD-AGENT: A Multi-agent Framework for End-to-end Anomaly Detection
May 19, 2025



Anomaly detection (AD) is essential in areas such as fraud detection, network monitoring, and scientific research. However, the diversity of data modalities and the increasing number of specialized AD libraries pose challenges for non-expert users who lack in-depth library-specific knowledge and advanced programming skills. To tackle this, we present AD-AGENT, an LLM-driven multi-agent framework that turns natural-language instructions into fully executable AD pipelines. AD-AGENT coordinates specialized agents for intent parsing, data preparation, library and model selection, documentation mining, and iterative code generation and debugging. Using a shared short-term workspace and a long-term cache, the agents integrate popular AD libraries like PyOD, PyGOD, and TSLib into a unified workflow. Experiments demonstrate that AD-AGENT produces reliable scripts and recommends competitive models across libraries. The system is open-sourced to support further research and practical applications in AD.
StealthRank: LLM Ranking Manipulation via Stealthy Prompt Optimization
Apr 08, 2025



The integration of large language models (LLMs) into information retrieval systems introduces new attack surfaces, particularly for adversarial ranking manipulations. We present StealthRank, a novel adversarial ranking attack that manipulates LLM-driven product recommendation systems while maintaining textual fluency and stealth. Unlike existing methods that often introduce detectable anomalies, StealthRank employs an energy-based optimization framework combined with Langevin dynamics to generate StealthRank Prompts (SRPs)-adversarial text sequences embedded within product descriptions that subtly yet effectively influence LLM ranking mechanisms. We evaluate StealthRank across multiple LLMs, demonstrating its ability to covertly boost the ranking of target products while avoiding explicit manipulation traces that can be easily detected. Our results show that StealthRank consistently outperforms state-of-the-art adversarial ranking baselines in both effectiveness and stealth, highlighting critical vulnerabilities in LLM-driven recommendation systems.
Efficient Model Selection for Time Series Forecasting via LLMs
Apr 02, 2025



Model selection is a critical step in time series forecasting, traditionally requiring extensive performance evaluations across various datasets. Meta-learning approaches aim to automate this process, but they typically depend on pre-constructed performance matrices, which are costly to build. In this work, we propose to leverage Large Language Models (LLMs) as a lightweight alternative for model selection. Our method eliminates the need for explicit performance matrices by utilizing the inherent knowledge and reasoning capabilities of LLMs. Through extensive experiments with LLaMA, GPT and Gemini, we demonstrate that our approach outperforms traditional meta-learning techniques and heuristic baselines, while significantly reducing computational overhead. These findings underscore the potential of LLMs in efficient model selection for time series forecasting.
Treble Counterfactual VLMs: A Causal Approach to Hallucination
Mar 08, 2025



Vision-Language Models (VLMs) have advanced multi-modal tasks like image captioning, visual question answering, and reasoning. However, they often generate hallucinated outputs inconsistent with the visual context or prompt, limiting reliability in critical applications like autonomous driving and medical imaging. Existing studies link hallucination to statistical biases, language priors, and biased feature learning but lack a structured causal understanding. In this work, we introduce a causal perspective to analyze and mitigate hallucination in VLMs. We hypothesize that hallucination arises from unintended direct influences of either the vision or text modality, bypassing proper multi-modal fusion. To address this, we construct a causal graph for VLMs and employ counterfactual analysis to estimate the Natural Direct Effect (NDE) of vision, text, and their cross-modal interaction on the output. We systematically identify and mitigate these unintended direct effects to ensure that responses are primarily driven by genuine multi-modal fusion. Our approach consists of three steps: (1) designing structural causal graphs to distinguish correct fusion pathways from spurious modality shortcuts, (2) estimating modality-specific and cross-modal NDE using perturbed image representations, hallucinated text embeddings, and degraded visual inputs, and (3) implementing a test-time intervention module to dynamically adjust the model's dependence on each modality. Experimental results demonstrate that our method significantly reduces hallucination while preserving task performance, providing a robust and interpretable framework for improving VLM reliability. To enhance accessibility and reproducibility, our code is publicly available at https://github.com/TREE985/Treble-Counterfactual-VLMs.
Safe and Agile Transportation of Cable-Suspended Payload via Multiple Aerial Robots
Jan 25, 2025



Transporting a heavy payload using multiple aerial robots (MARs) is an efficient manner to extend the load capacity of a single aerial robot. However, existing schemes for the multiple aerial robots transportation system (MARTS) still lack the capability to generate a collision-free and dynamically feasible trajectory in real-time and further track an agile trajectory especially when there are no sensors available to measure the states of payload and cable. Therefore, they are limited to low-agility transportation in simple environments. To bridge the gap, we propose complete planning and control schemes for the MARTS, achieving safe and agile aerial transportation (SAAT) of a cable-suspended payload in complex environments. Flatness maps for the aerial robot considering the complete kinematical constraint and the dynamical coupling between each aerial robot and payload are derived. To improve the responsiveness for the generation of the safe, dynamically feasible, and agile trajectory in complex environments, a real-time spatio-temporal trajectory planning scheme is proposed for the MARTS. Besides, we break away from the reliance on the state measurement for both the payload and cable, as well as the closed-loop control for the payload, and propose a fully distributed control scheme to track the agile trajectory that is robust against imprecise payload mass and non-point mass payload. The proposed schemes are extensively validated through benchmark comparisons, ablation studies, and simulations. Finally, extensive real-world experiments are conducted on a MARTS integrated by three aerial robots with onboard computers and sensors. The result validates the efficiency and robustness of our proposed schemes for SAAT in complex environments.