 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexDraft: Flexible Speculative Decoding via Attention Tuning and Bonus-Guided Calibration
May 19, 2026Speculative decoding accelerates memory-bound LLM inference without quality degradation by using a fast drafter to propose multiple candidate tokens and the target model to verify them in parallel. However, conventional sequential speculative decoding suffers from mutual waiting between drafting and verification, and repeated exchange of intermediate states further increases memory access overhead. Parallel speculative decoding addresses this limitation by performing drafting and verification within a single target forward pass, allowing future drafts to be prepared while current candidates are being verified. Although effective at small batch sizes, existing parallel speculative decoding methods either require costly continual pretraining with quality degradation or suffer from low acceptance rates. More importantly, this paradigm inherently suffers from uncertainty in both the bonus token and the accepted length, leading to draft verification mismatch and causing throughput gains to collapse at large batch sizes. To address these limitations, we introduce FlexDraft, a lossless speculative decoding framework that flexibly adapts to varying batch sizes through three key designs. (1) Attention Tuning enables block diffusion drafting by tuning only the attention projectors of the final few layers on mask tokens, while keeping the autoregressive path frozen to preserve the target distribution and produce high quality drafts with minimal trainable parameters. (2) Bonus-guided Calibration uses a lightweight MLP conditioned on the resolved bonus token to calibrate draft logits, mitigating draft verification mismatch caused by bonus token uncertainty. (3) Flex Decoding dynamically switches between parallel draft and verify at small batch sizes and sequential draft then verify at large batch sizes, and adjusts verification length based on draft confidence to eliminate redundant computation.
StreamingVLA: Streaming Vision-Language-Action Model with Action Flow Matching and Adaptive Early Observation
Mar 30, 2026Vision-language-action (VLA) models have demonstrated exceptional performance in natural language-driven perception and control. However, the high computational cost of VLA models poses significant efficiency challenges, particularly for resource-constrained edge platforms in real-world deployments. However, since different stages of VLA (observation, action generation and execution) must proceed sequentially, and wait for the completion of the preceding stage, the system suffers from frequent halting and high latency. To address this, We conduct a systematic analysis to identify the challenges for fast and fluent generation, and propose enabling VLAs with the ability to asynchronously parallelize across VLA stages in a "streaming" manner. First, we eliminate the reliance on action chunking and adopt action flow matching, which learns the trajectory of action flows rather than denoising chunk-wise actions. It overlaps the latency of action generation and execution. Second, we design an action saliency-aware adaptive observation mechanism, thereby overlapping the latency of execution and observation. Without sacrificing performance, StreamingVLA achieves substantial speedup and improves the fluency of execution. It achieves a 2.4 $\times$ latency speedup and reduces execution halting by 6.5 $\times$.
Decoupling Vision and Language: Codebook Anchored Visual Adaptation
Feb 23, 2026Large Vision-Language Models (LVLMs) use their vision encoders to translate images into representations for downstream reasoning, but the encoders often underperform in domain-specific visual tasks such as medical image diagnosis or fine-grained classification, where representation errors can cascade through the language model, leading to incorrect responses. Existing adaptation methods modify the continuous feature interface between encoder and language model through projector tuning or other parameter-efficient updates, which still couples the two components and requires re-alignment whenever the encoder changes. We introduce CRAFT (Codebook RegulAted Fine-Tuning), a lightweight method that fine-tunes the encoder using a discrete codebook that anchors visual representations to a stable token space, achieving domain adaptation without modifying other parts of the model. This decoupled design allows the adapted encoder to seamlessly boost the performance of LVLMs with different language architectures, as long as they share the same codebook. Empirically, CRAFT achieves an average gain of 13.51% across 10 domain-specific benchmarks such as VQARAD and PlantVillage, while preserving the LLM's linguistic capabilities and outperforming peer methods that operate on continuous tokens.
SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer
Jan 23, 2026Diffusion Transformers have recently demonstrated remarkable performance in video generation. However, the long input sequences result in high computational latency due to the quadratic complexity of full attention. Various sparse attention mechanisms have been proposed. Training-free sparse attention is constrained by limited sparsity and thus offers modest acceleration, whereas training-based methods can reach much higher sparsity but demand substantial data and computation for training. In this work, we propose SALAD, introducing a lightweight linear attention branch in parallel with the sparse attention. By incorporating an input-dependent gating mechanism to finely balance the two branches, our method attains 90% sparsity and 1.72x inference speedup, while maintaining generation quality comparable to the full attention baseline. Moreover, our finetuning process is highly efficient, requiring only 2,000 video samples and 1,600 training steps with a batch size of 8.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
AuthGuard: Generalizable Deepfake Detection via Language Guidance
Jun 04, 2025Existing deepfake detection techniques struggle to keep-up with the ever-evolving novel, unseen forgeries methods. This limitation stems from their reliance on statistical artifacts learned during training, which are often tied to specific generation processes that may not be representative of samples from new, unseen deepfake generation methods encountered at test time. We propose that incorporating language guidance can improve deepfake detection generalization by integrating human-like commonsense reasoning -- such as recognizing logical inconsistencies and perceptual anomalies -- alongside statistical cues. To achieve this, we train an expert deepfake vision encoder by combining discriminative classification with image-text contrastive learning, where the text is generated by generalist MLLMs using few-shot prompting. This allows the encoder to extract both language-describable, commonsense deepfake artifacts and statistical forgery artifacts from pixel-level distributions. To further enhance robustness, we integrate data uncertainty learning into vision-language contrastive learning, mitigating noise in image-text supervision. Our expert vision encoder seamlessly interfaces with an LLM, further enabling more generalized and interpretable deepfake detection while also boosting accuracy. The resulting framework, AuthGuard, achieves state-of-the-art deepfake detection accuracy in both in-distribution and out-of-distribution settings, achieving AUC gains of 6.15% on the DFDC dataset and 16.68% on the DF40 dataset. Additionally, AuthGuard significantly enhances deepfake reasoning, improving performance by 24.69% on the DDVQA dataset.
PM-KVQ: Progressive Mixed-precision KV Cache Quantization for Long-CoT LLMs
May 24, 2025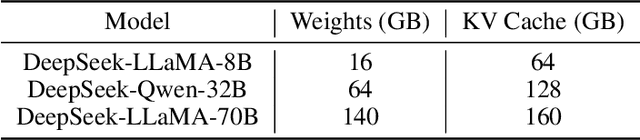
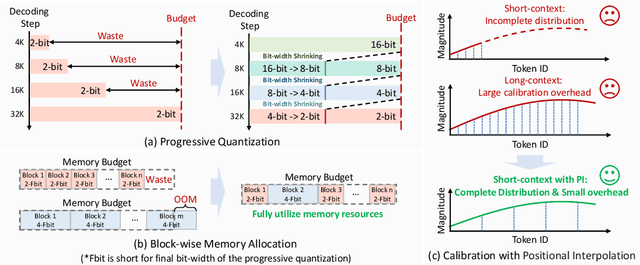


Recently, significant progress has been made in developing reasoning-capable Large Language Models (LLMs) through long Chain-of-Thought (CoT) techniques. However, this long-CoT reasoning process imposes substantial memory overhead due to the large Key-Value (KV) Cache memory overhead. Post-training KV Cache quantization has emerged as a promising compression technique and has been extensively studied in short-context scenarios. However, directly applying existing methods to long-CoT LLMs causes significant performance degradation due to the following two reasons: (1) Large cumulative error: Existing methods fail to adequately leverage available memory, and they directly quantize the KV Cache during each decoding step, leading to large cumulative quantization error. (2) Short-context calibration: Due to Rotary Positional Embedding (RoPE), the use of short-context data during calibration fails to account for the distribution of less frequent channels in the Key Cache, resulting in performance loss. We propose Progressive Mixed-Precision KV Cache Quantization (PM-KVQ) for long-CoT LLMs to address the above issues in two folds: (1) To reduce cumulative error, we design a progressive quantization strategy to gradually lower the bit-width of KV Cache in each block. Then, we propose block-wise memory allocation to assign a higher bit-width to more sensitive transformer blocks. (2) To increase the calibration length without additional overhead, we propose a new calibration strategy with positional interpolation that leverages short calibration data with positional interpolation to approximate the data distribution of long-context data. Extensive experiments on 7B-70B long-CoT LLMs show that PM-KVQ improves reasoning benchmark performance by up to 8% over SOTA baselines under the same memory budget. Our code is available at https://github.com/thu-nics/PM-KVQ.
Optimal Transport-Guided Source-Free Adaptation for Face Anti-Spoofing
Mar 29, 2025Developing a face anti-spoofing model that meets the security requirements of clients worldwide is challenging due to the domain gap between training datasets and diverse end-user test data. Moreover, for security and privacy reasons, it is undesirable for clients to share a large amount of their face data with service providers. In this work, we introduce a novel method in which the face anti-spoofing model can be adapted by the client itself to a target domain at test time using only a small sample of data while keeping model parameters and training data inaccessible to the client. Specifically, we develop a prototype-based base model and an optimal transport-guided adaptor that enables adaptation in either a lightweight training or training-free fashion, without updating base model's parameters. Furthermore, we propose geodesic mixup, an optimal transport-based synthesis method that generates augmented training data along the geodesic path between source prototypes and target data distribution. This allows training a lightweight classifier to effectively adapt to target-specific characteristics while retaining essential knowledge learned from the source domain. In cross-domain and cross-attack settings, compared with recent methods, our method achieves average relative improvements of 19.17% in HTER and 8.58% in AUC, respectively.
LiteVAR: Compressing Visual Autoregressive Modelling with Efficient Attention and Quantization
Nov 26, 2024Visual Autoregressive (VAR) has emerged as a promising approach in image generation, offering competitive potential and performance comparable to diffusion-based models. However, current AR-based visual generation models require substantial computational resources, limiting their applicability on resource-constrained devices. To address this issue, we conducted analysis and identified significant redundancy in three dimensions of the VAR model: (1) the attention map, (2) the attention outputs when using classifier free guidance, and (3) the data precision. Correspondingly, we proposed efficient attention mechanism and low-bit quantization method to enhance the efficiency of VAR models while maintaining performance. With negligible performance lost (less than 0.056 FID increase), we could achieve 85.2% reduction in attention computation, 50% reduction in overall memory and 1.5x latency reduction. To ensure deployment feasibility, we developed efficient training-free compression techniques and analyze the deployment feasibility and efficiency gain of each technique.
DiTFastAttn: Attention Compression for Diffusion Transformer Models
Jun 12, 2024



Diffusion Transformers (DiT) excel at image and video generation but face computational challenges due to self-attention's quadratic complexity. We propose DiTFastAttn, a novel post-training compression method to alleviate DiT's computational bottleneck. We identify three key redundancies in the attention computation during DiT inference: 1. spatial redundancy, where many attention heads focus on local information; 2. temporal redundancy, with high similarity between neighboring steps' attention outputs; 3. conditional redundancy, where conditional and unconditional inferences exhibit significant similarity. To tackle these redundancies, we propose three techniques: 1. Window Attention with Residual Caching to reduce spatial redundancy; 2. Temporal Similarity Reduction to exploit the similarity between steps; 3. Conditional Redundancy Elimination to skip redundant computations during conditional generation. To demonstrate the effectiveness of DiTFastAttn, we apply it to DiT, PixArt-Sigma for image generation tasks, and OpenSora for video generation tasks. Evaluation results show that for image generation, our method reduces up to 88\% of the FLOPs and achieves up to 1.6x speedup at high resolution generation.