 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaSR: Context-Aware Speech Recognition via Latent Reasoning
May 30, 2026Recent advances in Speech Large Language Models (Speech LLMs) have significantly enhanced spoken language understanding and reasoning. However, their contextual awareness is limited, struggling to perform speech recognition that effectively reflects the speaker's intent and topical context. In this paper, we propose LaSR (Latent Speech Reasoning), a novel training paradigm featuring a context-aware reasoning trajectory that leverages the latent reasoning process. Instead of generating explicit intermediate tokens, LaSR aligns chain-of-thought (CoT) supervision around the acoustic feature region of the targeted word, and introduces latent reasoning periods for context information grounding and transcriptional transition. Furthermore, to effectively benchmark contextual recognition on specialized vocabulary, we propose Spoken Darwin-Science, a large-scale corpus focusing on academic terminologies. Preliminary experiments on Fun-Audio-Chat demonstrate that LaSR significantly improves terminology recognition without introducing additional latency and consistently outperforms standard supervised fine-tuning baselines. Our findings highlight the potential of latent reasoning in building efficient, context-aware speech assistants.
Agentic Active Omni-Modal Perception for Multi-Hop Audio-Visual Reasoning
May 27, 2026Multi-hop audio-visual reasoning remains challenging for Omni-LLMs, as relevant evidence is often sparse, temporally dispersed, and distributed across both audio and visual streams. Existing benchmarks provide limited investigation of this setting, typically involving only a limited number of modalities, relevant temporal segments, or reasoning steps. In this work, we introduce MOV-Bench, a benchmark containing 519 carefully curated questions that require multi-hop reasoning over temporally dispersed audio-visual evidence. Evaluations on MOV-Bench reveal that current Omni-LLMs still struggle with multi-hop cross-modal reasoning. To address this challenge, we further propose AOP-Agent, an efficient agentic framework built on open-source Omni-LLMs for active omni-modal perception. By combining a hierarchical omni-modal memory with a collaborative observe-reflect-replan loop, AOP-Agent enables open-source Omni-LLMs to perform active perception without additional training or proprietary models. Experiments on MOV-Bench and OmniVideoBench demonstrate that AOP-Agent consistently improves reasoning performance, with particularly notable gains on long videos and reasoning-intensive questions.
CMP: Robust Whole-Body Tracking for Loco-Manipulation via Competence Manifold Projection
Apr 08, 2026While decoupled control schemes for legged mobile manipulators have shown robustness, learning holistic whole-body control policies for tracking global end-effector poses remains fragile against Out-of-Distribution (OOD) inputs induced by sensor noise or infeasible user commands. To improve robustness against these perturbations without sacrificing task performance and continuity, we propose Competence Manifold Projection (CMP). Specifically, we utilize a Frame-Wise Safety Scheme that transforms the infinite-horizon safety constraint into a computationally efficient single-step manifold inclusion. To instantiate this competence manifold, we employ a Lower-Bounded Safety Estimator that distinguishes unmastered intentions from the training distribution. We then introduce an Isomorphic Latent Space (ILS) that aligns manifold geometry with safety probability, enabling efficient O(1) seamless defense against arbitrary OOD intents. Experiments demonstrate that CMP achieves up to a 10-fold survival rate improvement in typical OOD scenarios where baselines suffer catastrophic failure, incurring under 10% tracking degradation. Notably, the system exhibits emergent ``best-effort'' generalization behaviors to progressively accomplish OOD goals by adhering to the competence boundaries. Result videos are available at: https://shepherd1226.github.io/CMP.
F2F-AP: Flow-to-Future Asynchronous Policy for Real-time Dynamic Manipulation
Apr 02, 2026Asynchronous inference has emerged as a prevalent paradigm in robotic manipulation, achieving significant progress in ensuring trajectory smoothness and efficiency. However, a systemic challenge remains unresolved, as inherent latency causes generated actions to inevitably lag behind the real-time environment. This issue is particularly exacerbated in dynamic scenarios, where such temporal misalignment severely compromises the policy's ability to interpret and react to rapidly evolving surroundings. In this paper, we propose a novel framework that leverages predicted object flow to synthesize future observations, incorporating a flow-based contrastive learning objective to align the visual feature representations of predicted observations with ground-truth future states. Empowered by this anticipated visual context, our asynchronous policy gains the capacity for proactive planning and motion, enabling it to explicitly compensate for latency and robustly execute manipulation tasks involving actively moving objects. Experimental results demonstrate that our approach significantly enhances responsiveness and success rates in complex dynamic manipulation tasks.
VocalNet-MDM: Accelerating Streaming Speech LLM via Self-Distilled Masked Diffusion Modeling
Feb 09, 2026Recent Speech Large Language Models~(LLMs) have achieved impressive capabilities in end-to-end speech interaction. However, the prevailing autoregressive paradigm imposes strict serial constraints, limiting generation efficiency and introducing exposure bias. In this paper, we investigate Masked Diffusion Modeling~(MDM) as a non-autoregressive paradigm for speech LLMs and introduce VocalNet-MDM. To adapt MDM for streaming speech interaction, we address two critical challenges: training-inference mismatch and iterative overhead. We propose Hierarchical Block-wise Masking to align training objectives with the progressive masked states encountered during block diffusion decoding, and Iterative Self-Distillation to compress multi-step refinement into fewer steps for low-latency inference. Trained on a limited scale of only 6K hours of speech data, VocalNet-MDM achieves a 3.7$\times$--10$\times$ decoding speedup and reduces first-chunk latency by 34\% compared to AR baselines. It maintains competitive recognition accuracy while achieving state-of-the-art text quality and speech naturalness, demonstrating that MDM is a promising and scalable alternative for low-latency, efficient speech LLMs.
Edge AI Inference in ISCC Networks: Sensing Accuracy Analysis and Precoding Design
Jan 01, 2026This work explores the relationship between sensing accuracy and precoding coefficients for edge artificial intelligence (AI) inference in integrated sensing, communication and computation (ISCC) networks. We start by constructing a system model of an over-the-air-empowered ISCC network for edge AI inference, involving distributed edge sensors for feature extraction and an edge server for classification. Based on this model, we introduce a discriminant gain (DG) to characterize sensing accuracy and novelly derive an explicit function of the DG about precoding coefficients, giving valuable insights into precoding design. Guided by this, we propose an effective precoding algorithm to solve a non-convex DG-maximization problem. Simulation results verify the effectiveness and feasibility of the proposed design for edge inference in ISCC networks.
Grad: Guided Relation Diffusion Generation for Graph Augmentation in Graph Fraud Detection
Dec 19, 2025



Nowadays, Graph Fraud Detection (GFD) in financial scenarios has become an urgent research topic to protect online payment security. However, as organized crime groups are becoming more professional in real-world scenarios, fraudsters are employing more sophisticated camouflage strategies. Specifically, fraudsters disguise themselves by mimicking the behavioral data collected by platforms, ensuring that their key characteristics are consistent with those of benign users to a high degree, which we call Adaptive Camouflage. Consequently, this narrows the differences in behavioral traits between them and benign users within the platform's database, thereby making current GFD models lose efficiency. To address this problem, we propose a relation diffusion-based graph augmentation model Grad. In detail, Grad leverages a supervised graph contrastive learning module to enhance the fraud-benign difference and employs a guided relation diffusion generator to generate auxiliary homophilic relations from scratch. Based on these, weak fraudulent signals would be enhanced during the aggregation process, thus being obvious enough to be captured. Extensive experiments have been conducted on two real-world datasets provided by WeChat Pay, one of the largest online payment platforms with billions of users, and three public datasets. The results show that our proposed model Grad outperforms SOTA methods in both various scenarios, achieving at most 11.10% and 43.95% increases in AUC and AP, respectively. Our code is released at https://github.com/AI4Risk/antifraud and https://github.com/Muyiiiii/WWW25-Grad.
* Accepted by The Web Conference 2025 (WWW'25). 12 pages, includes implementation details. Code: https://github.com/AI4Risk/antifraud and https://github.com/Muyiiiiii/WWW25-Grad
VocalBench-zh: Decomposing and Benchmarking the Speech Conversational Abilities in Mandarin Context
Nov 17, 2025



The development of multi-modal large language models (LLMs) leads to intelligent approaches capable of speech interactions. As one of the most widely spoken languages globally, Mandarin is supported by most models to enhance their applicability and reach. However, the scarcity of comprehensive speech-to-speech (S2S) benchmarks in Mandarin contexts impedes systematic evaluation for developers and hinders fair model comparison for users. In this work, we propose VocalBench-zh, an ability-level divided evaluation suite adapted to Mandarin context consisting of 10 well-crafted subsets and over 10K high-quality instances, covering 12 user-oriented characters. The evaluation experiment on 14 mainstream models reveals the common challenges for current routes, and highlights the need for new insights into next-generation speech interactive systems. The evaluation codes and datasets will be available at https://github.com/SJTU-OmniAgent/VocalBench-zh.
VocalNet-M2: Advancing Low-Latency Spoken Language Modeling via Integrated Multi-Codebook Tokenization and Multi-Token Prediction
Nov 13, 2025Current end-to-end spoken language models (SLMs) have made notable progress, yet they still encounter considerable response latency. This delay primarily arises from the autoregressive generation of speech tokens and the reliance on complex flow-matching models for speech synthesis. To overcome this, we introduce VocalNet-M2, a novel low-latency SLM that integrates a multi-codebook tokenizer and a multi-token prediction (MTP) strategy. Our model directly generates multi-codebook speech tokens, thus eliminating the need for a latency-inducing flow-matching model. Furthermore, our MTP strategy enhances generation efficiency and improves overall performance. Extensive experiments demonstrate that VocalNet-M2 achieves a substantial reduction in first chunk latency (from approximately 725ms to 350ms) while maintaining competitive performance across mainstream SLMs. This work also provides a comprehensive comparison of single-codebook and multi-codebook strategies, offering valuable insights for developing efficient and high-performance SLMs for real-time interactive applications.
CS3-Bench: Evaluating and Enhancing Speech-to-Speech LLMs for Mandarin-English Code-Switching
Oct 09, 2025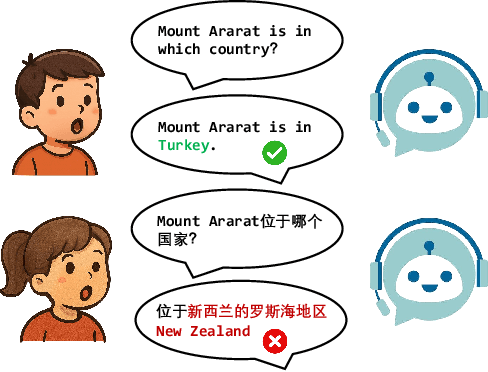

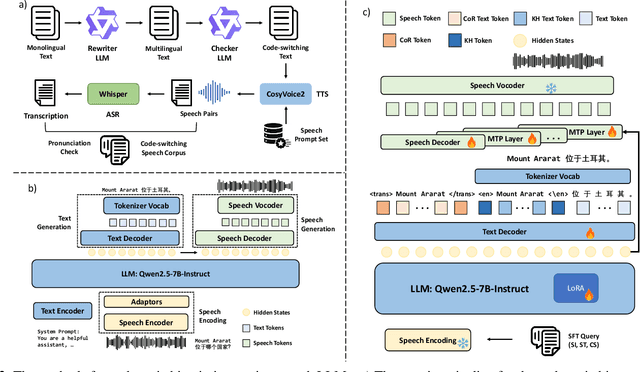
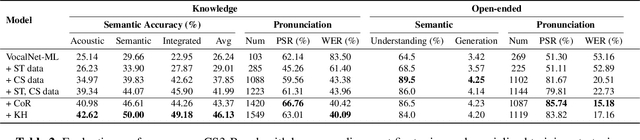
The advancement of multimodal large language models has accelerated the development of speech-to-speech interaction systems. While natural monolingual interaction has been achieved, we find existing models exhibit deficiencies in language alignment. In our proposed Code-Switching Speech-to-Speech Benchmark (CS3-Bench), experiments on 7 mainstream models demonstrate a relative performance drop of up to 66% in knowledge-intensive question answering and varying degrees of misunderstanding in open-ended conversations. Starting from a model with severe performance deterioration, we propose both data constructions and training approaches to improve the language alignment capabilities, specifically employing Chain of Recognition (CoR) to enhance understanding and Keyword Highlighting (KH) to guide generation. Our approach improves the knowledge accuracy from 25.14% to 46.13%, with open-ended understanding rate from 64.5% to 86.5%, and significantly reduces pronunciation errors in the secondary language. CS3-Bench is available at https://huggingface.co/datasets/VocalNet/CS3-Bench.