 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAViL: Masked Audio-Video Learners
Dec 15, 2022



We present Masked Audio-Video Learners (MAViL) to train audio-visual representations. Our approach learns with three complementary forms of self-supervision: (1) reconstruction of masked audio and video input data, (2) intra- and inter-modal contrastive learning with masking, and (3) self-training by reconstructing joint audio-video contextualized features learned from the first two objectives. Pre-training with MAViL not only enables the model to perform well in audio-visual classification and retrieval tasks but also improves representations of each modality in isolation, without using information from the other modality for fine-tuning or inference. Empirically, MAViL sets a new state-of-the-art on AudioSet (53.1 mAP) and VGGSound (67.1% accuracy). For the first time, a self-supervised audio-visual model outperforms ones that use external supervision on these benchmarks. Code will be available soon.
Scaling Language-Image Pre-training via Masking
Dec 01, 2022



We present Fast Language-Image Pre-training (FLIP), a simple and more efficient method for training CLIP. Our method randomly masks out and removes a large portion of image patches during training. Masking allows us to learn from more image-text pairs given the same wall-clock time and contrast more samples per iteration with similar memory footprint. It leads to a favorable trade-off between accuracy and training time. In our experiments on 400 million image-text pairs, FLIP improves both accuracy and speed over the no-masking baseline. On a large diversity of downstream tasks, FLIP dominantly outperforms the CLIP counterparts trained on the same data. Facilitated by the speedup, we explore the scaling behavior of increasing the model size, data size, or training length, and report encouraging results and comparisons. We hope that our work will foster future research on scaling vision-language learning.
Where is my Wallet? Modeling Object Proposal Sets for Egocentric Visual Query Localization
Nov 18, 2022



This paper deals with the problem of localizing objects in image and video datasets from visual exemplars. In particular, we focus on the challenging problem of egocentric visual query localization. We first identify grave implicit biases in current query-conditioned model design and visual query datasets. Then, we directly tackle such biases at both frame and object set levels. Concretely, our method solves these issues by expanding limited annotations and dynamically dropping object proposals during training. Additionally, we propose a novel transformer-based module that allows for object-proposal set context to be considered while incorporating query information. We name our module Conditioned Contextual Transformer or CocoFormer. Our experiments show the proposed adaptations improve egocentric query detection, leading to a better visual query localization system in both 2D and 3D configurations. Thus, we are able to improve frame-level detection performance from 26.28% to 31.26 in AP, which correspondingly improves the VQ2D and VQ3D localization scores by significant margins. Our improved context-aware query object detector ranked first and second in the VQ2D and VQ3D tasks in the 2nd Ego4D challenge. In addition to this, we showcase the relevance of our proposed model in the Few-Shot Detection (FSD) task, where we also achieve SOTA results. Our code is available at https://github.com/facebookresearch/vq2d_cvpr.
Bit Allocation using Optimization
Sep 20, 2022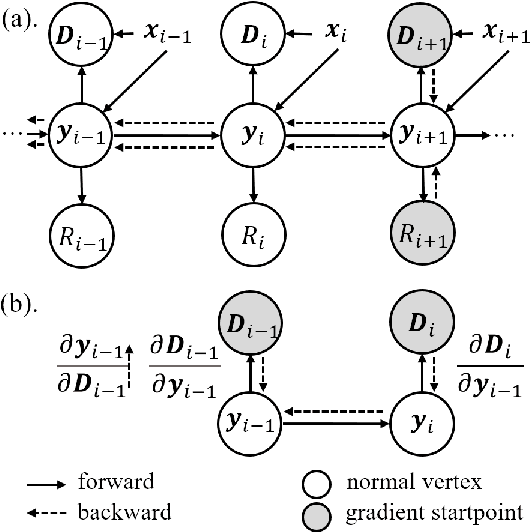
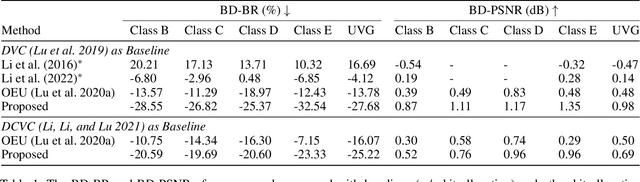


In this paper, we consider the problem of bit allocation in neural video compression (NVC). Due to the frame reference structure, current NVC methods using the same R-D (Rate-Distortion) trade-off parameter $\lambda$ for all frames are suboptimal, which brings the need for bit allocation. Unlike previous methods based on heuristic and empirical R-D models, we propose to solve this problem by gradient-based optimization. Specifically, we first propose a continuous bit implementation method based on Semi-Amortized Variational Inference (SAVI). Then, we propose a pixel-level implicit bit allocation method using iterative optimization by changing the SAVI target. Moreover, we derive the precise R-D model based on the differentiable trait of NVC. And we show the optimality of our method by proofing its equivalence to the bit allocation with precise R-D model. Experimental results show that our approach significantly improves NVC methods and outperforms existing bit allocation methods. Our approach is plug-and-play for all differentiable NVC methods, and it can be directly adopted on existing pre-trained models.
Negative Frames Matter in Egocentric Visual Query 2D Localization
Aug 03, 2022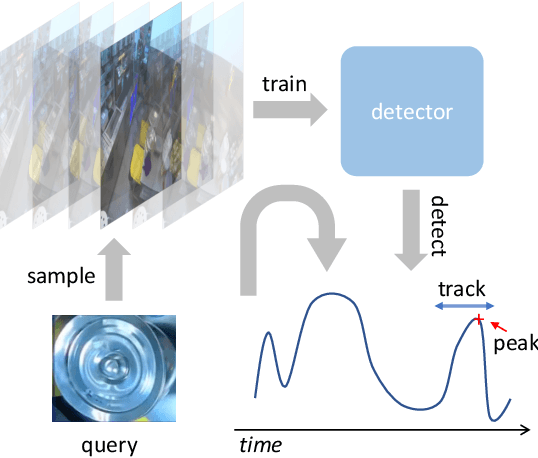
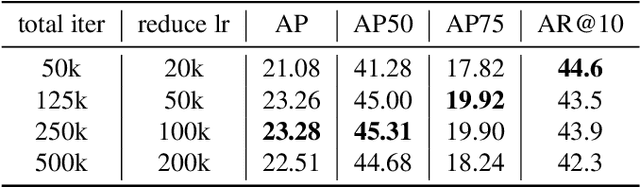

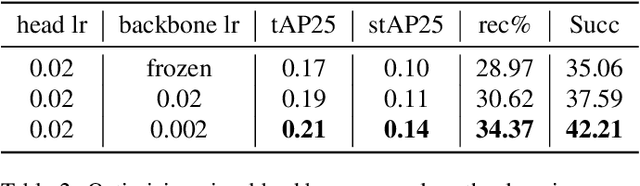
The recently released Ego4D dataset and benchmark significantly scales and diversifies the first-person visual perception data. In Ego4D, the Visual Queries 2D Localization task aims to retrieve objects appeared in the past from the recording in the first-person view. This task requires a system to spatially and temporally localize the most recent appearance of a given object query, where query is registered by a single tight visual crop of the object in a different scene. Our study is based on the three-stage baseline introduced in the Episodic Memory benchmark. The baseline solves the problem by detection and tracking: detect the similar objects in all the frames, then run a tracker from the most confident detection result. In the VQ2D challenge, we identified two limitations of the current baseline. (1) The training configuration has redundant computation. Although the training set has millions of instances, most of them are repetitive and the number of unique object is only around 14.6k. The repeated gradient computation of the same object lead to an inefficient training; (2) The false positive rate is high on background frames. This is due to the distribution gap between training and evaluation. During training, the model is only able to see the clean, stable, and labeled frames, but the egocentric videos also have noisy, blurry, or unlabeled background frames. To this end, we developed a more efficient and effective solution. Concretely, we bring the training loop from ~15 days to less than 24 hours, and we achieve 0.17% spatial-temporal AP, which is 31% higher than the baseline. Our solution got the first ranking on the public leaderboard. Our code is publicly available at https://github.com/facebookresearch/vq2d_cvpr.
Masked Autoencoders As Spatiotemporal Learners
May 18, 2022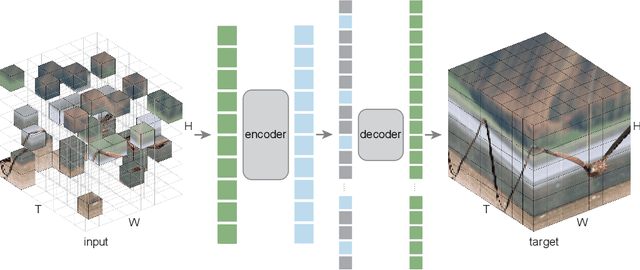



This paper studies a conceptually simple extension of Masked Autoencoders (MAE) to spatiotemporal representation learning from videos. We randomly mask out spacetime patches in videos and learn an autoencoder to reconstruct them in pixels. Interestingly, we show that our MAE method can learn strong representations with almost no inductive bias on spacetime (only except for patch and positional embeddings), and spacetime-agnostic random masking performs the best. We observe that the optimal masking ratio is as high as 90% (vs. 75% on images), supporting the hypothesis that this ratio is related to information redundancy of the data. A high masking ratio leads to a large speedup, e.g., > 4x in wall-clock time or even more. We report competitive results on several challenging video datasets using vanilla Vision Transformers. We observe that MAE can outperform supervised pre-training by large margins. We further report encouraging results of training on real-world, uncurated Instagram data. Our study suggests that the general framework of masked autoencoding (BERT, MAE, etc.) can be a unified methodology for representation learning with minimal domain knowledge.
Exploring Plain Vision Transformer Backbones for Object Detection
Mar 30, 2022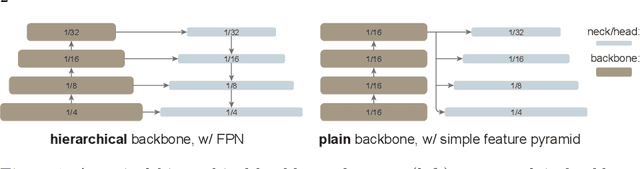



We explore the plain, non-hierarchical Vision Transformer (ViT) as a backbone network for object detection. This design enables the original ViT architecture to be fine-tuned for object detection without needing to redesign a hierarchical backbone for pre-training. With minimal adaptations for fine-tuning, our plain-backbone detector can achieve competitive results. Surprisingly, we observe: (i) it is sufficient to build a simple feature pyramid from a single-scale feature map (without the common FPN design) and (ii) it is sufficient to use window attention (without shifting) aided with very few cross-window propagation blocks. With plain ViT backbones pre-trained as Masked Autoencoders (MAE), our detector, named ViTDet, can compete with the previous leading methods that were all based on hierarchical backbones, reaching up to 61.3 box AP on the COCO dataset using only ImageNet-1K pre-training. We hope our study will draw attention to research on plain-backbone detectors. Code will be made available.
MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition
Jan 20, 2022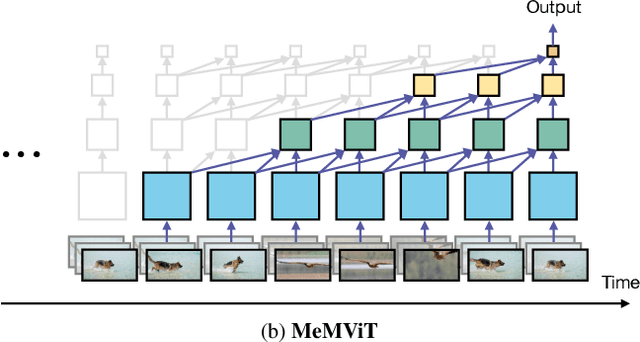

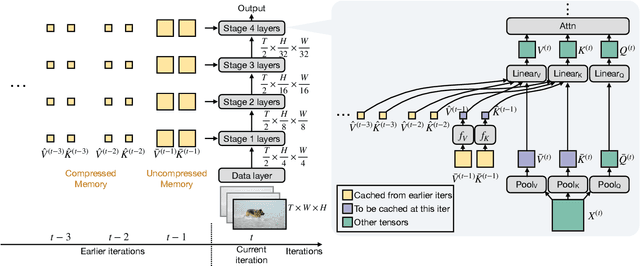

While today's video recognition systems parse snapshots or short clips accurately, they cannot connect the dots and reason across a longer range of time yet. Most existing video architectures can only process <5 seconds of a video without hitting the computation or memory bottlenecks. In this paper, we propose a new strategy to overcome this challenge. Instead of trying to process more frames at once like most existing methods, we propose to process videos in an online fashion and cache "memory" at each iteration. Through the memory, the model can reference prior context for long-term modeling, with only a marginal cost. Based on this idea, we build MeMViT, a Memory-augmented Multiscale Vision Transformer, that has a temporal support 30x longer than existing models with only 4.5% more compute; traditional methods need >3,000% more compute to do the same. On a wide range of settings, the increased temporal support enabled by MeMViT brings large gains in recognition accuracy consistently. MeMViT obtains state-of-the-art results on the AVA, EPIC-Kitchens-100 action classification, and action anticipation datasets. Code and models will be made publicly available.
Improved Multiscale Vision Transformers for Classification and Detection
Dec 02, 2021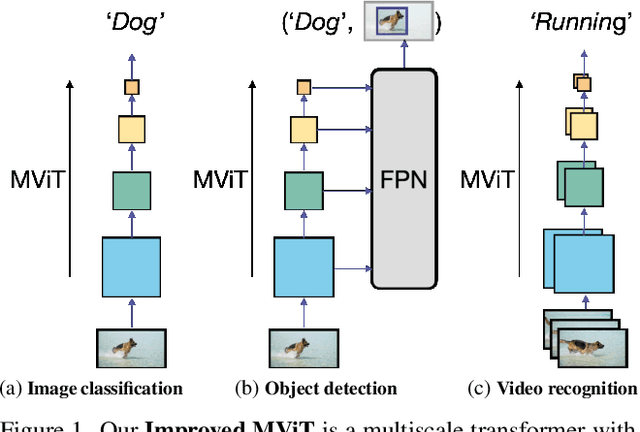
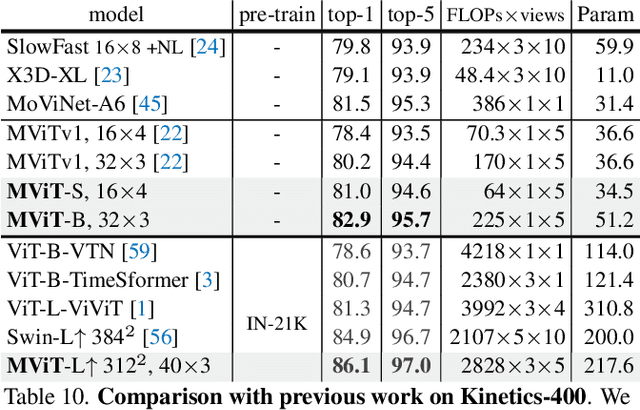
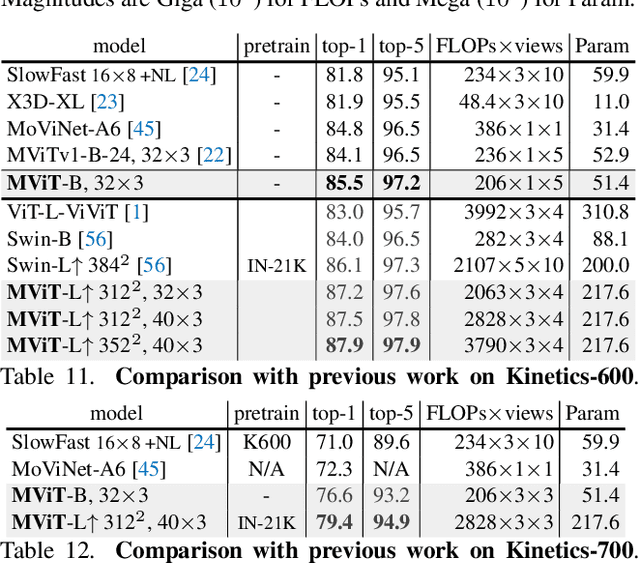
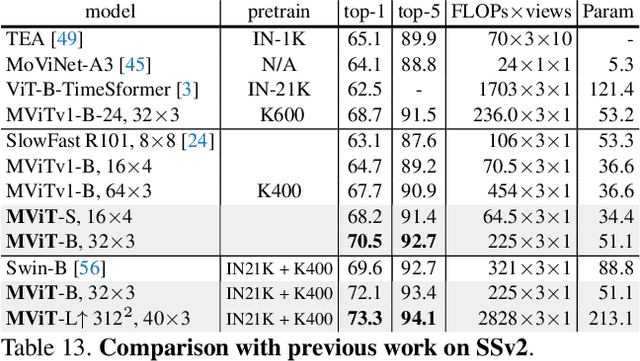
In this paper, we study Multiscale Vision Transformers (MViT) as a unified architecture for image and video classification, as well as object detection. We present an improved version of MViT that incorporates decomposed relative positional embeddings and residual pooling connections. We instantiate this architecture in five sizes and evaluate it for ImageNet classification, COCO detection and Kinetics video recognition where it outperforms prior work. We further compare MViTs' pooling attention to window attention mechanisms where it outperforms the latter in accuracy/compute. Without bells-and-whistles, MViT has state-of-the-art performance in 3 domains: 88.8% accuracy on ImageNet classification, 56.1 box AP on COCO object detection as well as 86.1% on Kinetics-400 video classification. Code and models will be made publicly available.
Masked Autoencoders Are Scalable Vision Learners
Dec 02, 2021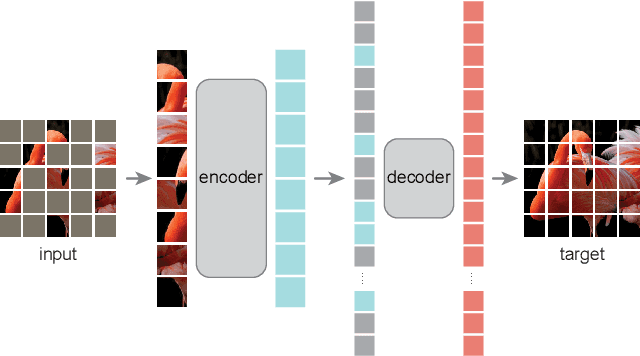
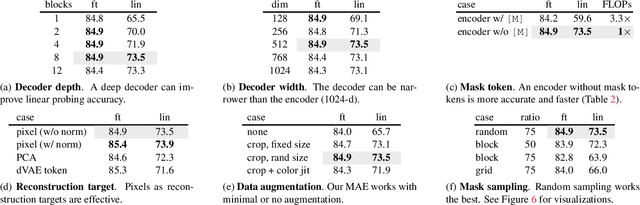

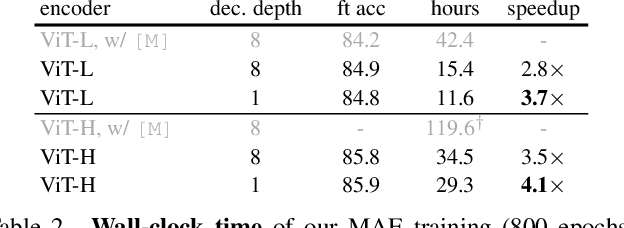
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pre-training and shows promising scaling behavior.