 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
Revisiting Feature Alignment for One-stage Object Detection
Aug 05, 2019
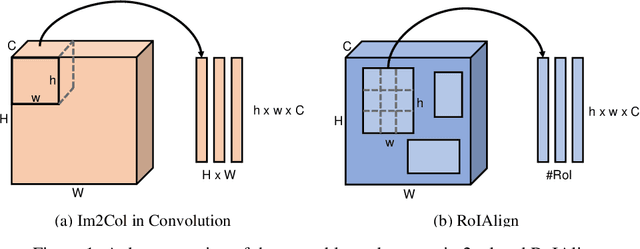
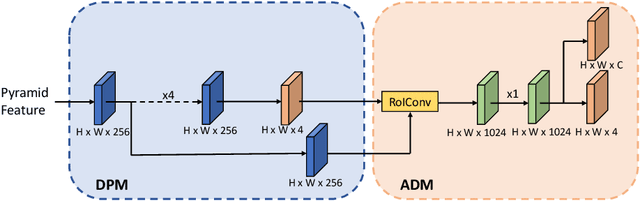

Recently, one-stage object detectors gain much attention due to their simplicity in practice. Its fully convolutional nature greatly reduces the difficulty of training and deployment compared with two-stage detectors which require NMS and sorting for the proposal stage. However, a fundamental issue lies in all one-stage detectors is the misalignment between anchor boxes and convolutional features, which significantly hinders the performance of one-stage detectors. In this work, we first reveal the deep connection between the widely used im2col operator and the RoIAlign operator. Guided by this illuminating observation, we propose a RoIConv operator which aligns the features and its corresponding anchors in one-stage detection in a principled way. We then design a fully convolutional AlignDet architecture which combines the flexibility of learned anchors and the preciseness of aligned features. Specifically, our AlignDet achieves a state-of-the-art mAP of 44.1 on the COCO test-dev with ResNeXt-101 backbone.
SimpleDet: A Simple and Versatile Distributed Framework for Object Detection and Instance Recognition
Mar 14, 2019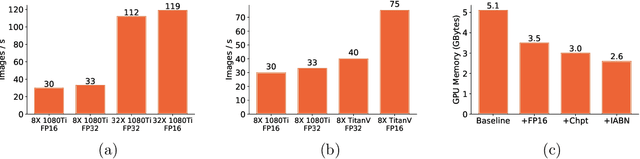

Object detection and instance recognition play a central role in many AI applications like autonomous driving, video surveillance and medical image analysis. However, training object detection models on large scale datasets remains computationally expensive and time consuming. This paper presents an efficient and open source object detection framework called SimpleDet which enables the training of state-of-the-art detection models on consumer grade hardware at large scale. SimpleDet supports up-to-date detection models with best practice. SimpleDet also supports distributed training with near linear scaling out of box. Codes, examples and documents of SimpleDet can be found at https://github.com/tusimple/simpledet .