 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality Compensation Network: Cross-Modal Adaptation for Action Recognition
Paper and Code
Jan 31, 2020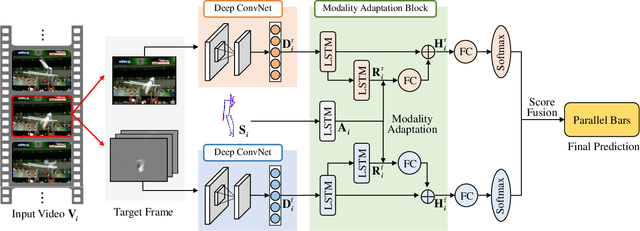
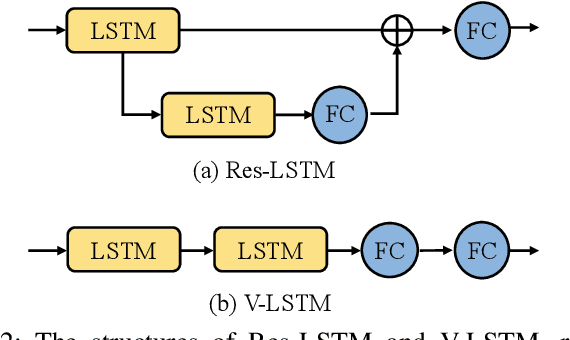
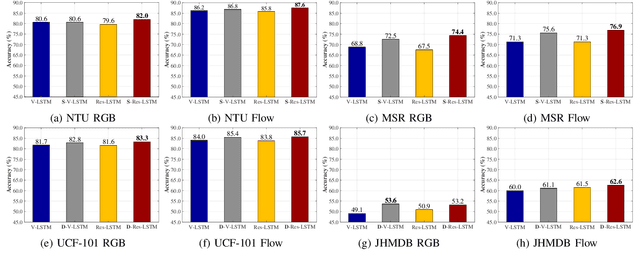
With the prevalence of RGB-D cameras, multi-modal video data have become more available for human action recognition. One main challenge for this task lies in how to effectively leverage their complementary information. In this work, we propose a Modality Compensation Network (MCN) to explore the relationships of different modalities, and boost the representations for human action recognition. We regard RGB/optical flow videos as source modalities, skeletons as auxiliary modality. Our goal is to extract more discriminative features from source modalities, with the help of auxiliary modality. Built on deep Convolutional Neural Networks (CNN) and Long Short Term Memory (LSTM) networks, our model bridges data from source and auxiliary modalities by a modality adaptation block to achieve adaptive representation learning, that the network learns to compensate for the loss of skeletons at test time and even at training time. We explore multiple adaptation schemes to narrow the distance between source and auxiliary modal distributions from different levels, according to the alignment of source and auxiliary data in training. In addition, skeletons are only required in the training phase. Our model is able to improve the recognition performance with source data when testing. Experimental results reveal that MCN outperforms state-of-the-art approaches on four widely-used action recognition benchmarks.