 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation
Mar 25, 2025We introduce HunyuanPortrait, a diffusion-based condition control method that employs implicit representations for highly controllable and lifelike portrait animation. Given a single portrait image as an appearance reference and video clips as driving templates, HunyuanPortrait can animate the character in the reference image by the facial expression and head pose of the driving videos. In our framework, we utilize pre-trained encoders to achieve the decoupling of portrait motion information and identity in videos. To do so, implicit representation is adopted to encode motion information and is employed as control signals in the animation phase. By leveraging the power of stable video diffusion as the main building block, we carefully design adapter layers to inject control signals into the denoising unet through attention mechanisms. These bring spatial richness of details and temporal consistency. HunyuanPortrait also exhibits strong generalization performance, which can effectively disentangle appearance and motion under different image styles. Our framework outperforms existing methods, demonstrating superior temporal consistency and controllability. Our project is available at https://kkakkkka.github.io/HunyuanPortrait.
GIVEPose: Gradual Intra-class Variation Elimination for RGB-based Category-Level Object Pose Estimation
Mar 20, 2025



Recent advances in RGBD-based category-level object pose estimation have been limited by their reliance on precise depth information, restricting their broader applicability. In response, RGB-based methods have been developed. Among these methods, geometry-guided pose regression that originated from instance-level tasks has demonstrated strong performance. However, we argue that the NOCS map is an inadequate intermediate representation for geometry-guided pose regression method, as its many-to-one correspondence with category-level pose introduces redundant instance-specific information, resulting in suboptimal results. This paper identifies the intra-class variation problem inherent in pose regression based solely on the NOCS map and proposes the Intra-class Variation-Free Consensus (IVFC) map, a novel coordinate representation generated from the category-level consensus model. By leveraging the complementary strengths of the NOCS map and the IVFC map, we introduce GIVEPose, a framework that implements Gradual Intra-class Variation Elimination for category-level object pose estimation. Extensive evaluations on both synthetic and real-world datasets demonstrate that GIVEPose significantly outperforms existing state-of-the-art RGB-based approaches, achieving substantial improvements in category-level object pose estimation. Our code is available at https://github.com/ziqin-h/GIVEPose.
IQPFR: An Image Quality Prior for Blind Face Restoration and Beyond
Mar 12, 2025Blind Face Restoration (BFR) addresses the challenge of reconstructing degraded low-quality (LQ) facial images into high-quality (HQ) outputs. Conventional approaches predominantly rely on learning feature representations from ground-truth (GT) data; however, inherent imperfections in GT datasets constrain restoration performance to the mean quality level of the training data, rather than attaining maximally attainable visual quality. To overcome this limitation, we propose a novel framework that incorporates an Image Quality Prior (IQP) derived from No-Reference Image Quality Assessment (NR-IQA) models to guide the restoration process toward optimal HQ reconstructions. Our methodology synergizes this IQP with a learned codebook prior through two critical innovations: (1) During codebook learning, we devise a dual-branch codebook architecture that disentangles feature extraction into universal structural components and HQ-specific attributes, ensuring comprehensive representation of both common and high-quality facial characteristics. (2) In the codebook lookup stage, we implement a quality-conditioned Transformer-based framework. NR-IQA-derived quality scores act as dynamic conditioning signals to steer restoration toward the highest feasible quality standard. This score-conditioned paradigm enables plug-and-play enhancement of existing BFR architectures without modifying the original structure. We also formulate a discrete representation-based quality optimization strategy that circumvents over-optimization artifacts prevalent in continuous latent space approaches. Extensive experiments demonstrate that our method outperforms state-of-the-art techniques across multiple benchmarks. Besides, our quality-conditioned framework demonstrates consistent performance improvements when integrated with prior BFR models. The code will be released.
Gamma: Toward Generic Image Assessment with Mixture of Assessment Experts
Mar 09, 2025



Image assessment aims to evaluate the quality and aesthetics of images and has been applied across various scenarios, such as natural and AIGC scenes. Existing methods mostly address these sub-tasks or scenes individually. While some works attempt to develop unified image assessment models, they have struggled to achieve satisfactory performance or cover a broad spectrum of assessment scenarios. In this paper, we present \textbf{Gamma}, a \textbf{G}eneric im\textbf{A}ge assess\textbf{M}ent model using \textbf{M}ixture of \textbf{A}ssessment Experts, which can effectively assess images from diverse scenes through mixed-dataset training. Achieving unified training in image assessment presents significant challenges due to annotation biases across different datasets. To address this issue, we first propose a Mixture of Assessment Experts (MoAE) module, which employs shared and adaptive experts to dynamically learn common and specific knowledge for different datasets, respectively. In addition, we introduce a Scene-based Differential Prompt (SDP) strategy, which uses scene-specific prompts to provide prior knowledge and guidance during the learning process, further boosting adaptation for various scenes. Our Gamma model is trained and evaluated on 12 datasets spanning 6 image assessment scenarios. Extensive experiments show that our unified Gamma outperforms other state-of-the-art mixed-training methods by significant margins while covering more scenes. Code: https://github.com/zht8506/Gamma.
ART: Anonymous Region Transformer for Variable Multi-Layer Transparent Image Generation
Feb 25, 2025Multi-layer image generation is a fundamental task that enables users to isolate, select, and edit specific image layers, thereby revolutionizing interactions with generative models. In this paper, we introduce the Anonymous Region Transformer (ART), which facilitates the direct generation of variable multi-layer transparent images based on a global text prompt and an anonymous region layout. Inspired by Schema theory suggests that knowledge is organized in frameworks (schemas) that enable people to interpret and learn from new information by linking it to prior knowledge.}, this anonymous region layout allows the generative model to autonomously determine which set of visual tokens should align with which text tokens, which is in contrast to the previously dominant semantic layout for the image generation task. In addition, the layer-wise region crop mechanism, which only selects the visual tokens belonging to each anonymous region, significantly reduces attention computation costs and enables the efficient generation of images with numerous distinct layers (e.g., 50+). When compared to the full attention approach, our method is over 12 times faster and exhibits fewer layer conflicts. Furthermore, we propose a high-quality multi-layer transparent image autoencoder that supports the direct encoding and decoding of the transparency of variable multi-layer images in a joint manner. By enabling precise control and scalable layer generation, ART establishes a new paradigm for interactive content creation.
Generative Models in Decision Making: A Survey
Feb 25, 2025In recent years, the exceptional performance of generative models in generative tasks has sparked significant interest in their integration into decision-making processes. Due to their ability to handle complex data distributions and their strong model capacity, generative models can be effectively incorporated into decision-making systems by generating trajectories that guide agents toward high-reward state-action regions or intermediate sub-goals. This paper presents a comprehensive review of the application of generative models in decision-making tasks. We classify seven fundamental types of generative models: energy-based models, generative adversarial networks, variational autoencoders, normalizing flows, diffusion models, generative flow networks, and autoregressive models. Regarding their applications, we categorize their functions into three main roles: controllers, modelers and optimizers, and discuss how each role contributes to decision-making. Furthermore, we examine the deployment of these models across five critical real-world decision-making scenarios. Finally, we summarize the strengths and limitations of current approaches and propose three key directions for advancing next-generation generative directive models: high-performance algorithms, large-scale generalized decision-making models, and self-evolving and adaptive models.
Integrating Extra Modality Helps Segmentor Find Camouflaged Objects Well
Feb 20, 2025Camouflaged Object Segmentation (COS) remains a challenging problem due to the subtle visual differences between camouflaged objects and backgrounds. Owing to the exceedingly limited visual cues available from visible spectrum, previous RGB single-modality approaches often struggle to achieve satisfactory results, prompting the exploration of multimodal data to enhance detection accuracy. In this work, we present UniCOS, a novel framework that effectively leverages diverse data modalities to improve segmentation performance. UniCOS comprises two key components: a multimodal segmentor, UniSEG, and a cross-modal knowledge learning module, UniLearner. UniSEG employs a state space fusion mechanism to integrate cross-modal features within a unified state space, enhancing contextual understanding and improving robustness to integration of heterogeneous data. Additionally, it includes a fusion-feedback mechanism that facilitate feature extraction. UniLearner exploits multimodal data unrelated to the COS task to improve the segmentation ability of the COS models by generating pseudo-modal content and cross-modal semantic associations. Extensive experiments demonstrate that UniSEG outperforms existing Multimodal COS (MCOS) segmentors, regardless of whether real or pseudo-multimodal COS data is available. Moreover, in scenarios where multimodal COS data is unavailable but multimodal non-COS data is accessible, UniLearner effectively exploits these data to enhance segmentation performance. Our code will be made publicly available on \href{https://github.com/cnyvfang/UniCOS}{GitHub}.
MagicArticulate: Make Your 3D Models Articulation-Ready
Feb 18, 2025



With the explosive growth of 3D content creation, there is an increasing demand for automatically converting static 3D models into articulation-ready versions that support realistic animation. Traditional approaches rely heavily on manual annotation, which is both time-consuming and labor-intensive. Moreover, the lack of large-scale benchmarks has hindered the development of learning-based solutions. In this work, we present MagicArticulate, an effective framework that automatically transforms static 3D models into articulation-ready assets. Our key contributions are threefold. First, we introduce Articulation-XL, a large-scale benchmark containing over 33k 3D models with high-quality articulation annotations, carefully curated from Objaverse-XL. Second, we propose a novel skeleton generation method that formulates the task as a sequence modeling problem, leveraging an auto-regressive transformer to naturally handle varying numbers of bones or joints within skeletons and their inherent dependencies across different 3D models. Third, we predict skinning weights using a functional diffusion process that incorporates volumetric geodesic distance priors between vertices and joints. Extensive experiments demonstrate that MagicArticulate significantly outperforms existing methods across diverse object categories, achieving high-quality articulation that enables realistic animation. Project page: https://chaoyuesong.github.io/MagicArticulate.
VLP: Vision-Language Preference Learning for Embodied Manipulation
Feb 17, 2025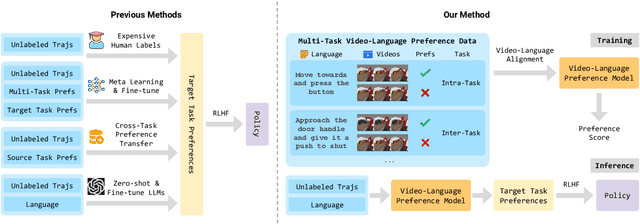

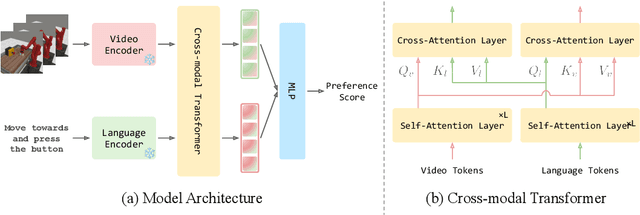
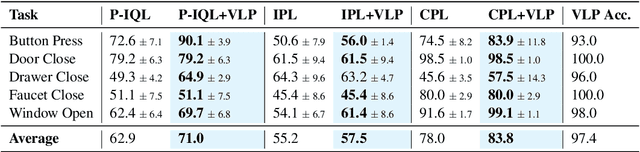
Reward engineering is one of the key challenges in Reinforcement Learning (RL). Preference-based RL effectively addresses this issue by learning from human feedback. However, it is both time-consuming and expensive to collect human preference labels. In this paper, we propose a novel \textbf{V}ision-\textbf{L}anguage \textbf{P}reference learning framework, named \textbf{VLP}, which learns a vision-language preference model to provide preference feedback for embodied manipulation tasks. To achieve this, we define three types of language-conditioned preferences and construct a vision-language preference dataset, which contains versatile implicit preference orders without human annotations. The preference model learns to extract language-related features, and then serves as a preference annotator in various downstream tasks. The policy can be learned according to the annotated preferences via reward learning or direct policy optimization. Extensive empirical results on simulated embodied manipulation tasks demonstrate that our method provides accurate preferences and generalizes to unseen tasks and unseen language instructions, outperforming the baselines by a large margin.
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling
Feb 10, 2025Test-Time Scaling (TTS) is an important method for improving the performance of Large Language Models (LLMs) by using additional computation during the inference phase. However, current studies do not systematically analyze how policy models, Process Reward Models (PRMs), and problem difficulty influence TTS. This lack of analysis limits the understanding and practical use of TTS methods. In this paper, we focus on two core questions: (1) What is the optimal approach to scale test-time computation across different policy models, PRMs, and problem difficulty levels? (2) To what extent can extended computation improve the performance of LLMs on complex tasks, and can smaller language models outperform larger ones through this approach? Through comprehensive experiments on MATH-500 and challenging AIME24 tasks, we have the following observations: (1) The compute-optimal TTS strategy is highly dependent on the choice of policy model, PRM, and problem difficulty. (2) With our compute-optimal TTS strategy, extremely small policy models can outperform larger models. For example, a 1B LLM can exceed a 405B LLM on MATH-500. Moreover, on both MATH-500 and AIME24, a 0.5B LLM outperforms GPT-4o, a 3B LLM surpasses a 405B LLM, and a 7B LLM beats o1 and DeepSeek-R1, while with higher inference efficiency. These findings show the significance of adapting TTS strategies to the specific characteristics of each task and model and indicate that TTS is a promising approach for enhancing the reasoning abilities of LLMs.