 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPS3D: End-to-End Feed-Forward 3D Panoptic Segmentation
Jun 08, 2026This paper introduces EPS3D, a new end-to-end feed-forward framework for open-vocabulary 3D panoptic segmentation. Unlike existing methods relying on additional preprocessing, we design an end-to-end architecture, with a distillation-based training strategy on diverse 3D scenes to predict 3D-aware semantic and instance features from multi-view images, improving 3D consistency and avoiding error accumulation. We further propose a mutual enhancement module to enforce inherent semantic-instance consistency. By aligning semantics within instances (Ins2Sem) and refining instance features with semantic guidance (Sem2Ins), we achieve more coherent 3D scene understanding. Ultimately, EPS3D outperforms SOTA baselines on two benchmarks (e.g., +13% mIoU for semantics on Replica) with high efficiency (e.g., 1s per scene), supporting tasks like robotic manipulation and 3D scene editing.
Anchor3R: Streaming 3D Reconstruction with Transient Anchors for Long-Horizon Visual Mapping
Jun 03, 2026Long-horizon online visual mapping is a core capability for robot perception, requiring continuous camera-motion and scene-geometry estimation from visual streams under bounded memory and computation. Recent feed-forward 3D reconstruction models provide strong geometric priors, but their streaming variants often predict poses in a fixed coordinate system tied to the first frame or a persistent scene memory. This fixed-gauge design leads to train--test mismatch, attention bias toward early anchors, and accumulated drift on sequences much longer than those seen during training. We propose \emph{Anchor3R}, a streaming 3D reconstruction framework that treats feed-forward reconstruction as current-centric local measurement prediction rather than persistent global-gauge regression. At each time step, Anchor3R predicts window-relative poses and a local pointmap in the current-frame coordinate system, turning streaming reconstruction into relative-pose measurement generation. These measurements support online pose updates, while loop-closure reinsertion and motion averaging align the trajectory and transform local pointmaps into a coherent global reconstruction. Experiments on indoor, outdoor, driving, and RGB-D benchmarks show that Anchor3R improves long-horizon pose accuracy and dense reconstruction quality over existing streaming baselines, while supporting bounded-memory online inference.
HorizonStream: Long-Horizon Attention for Streaming 3D Reconstruction
May 22, 2026Online 3D reconstruction requires estimating camera pose and scene geometry under strict causal and bounded-memory constraints. Existing methods often suffer from drift, jitter, or collapse on long sequences. We trace these failures to a fundamental mismatch. Streaming geometry is inherently temporally heterogeneous, with evidence ranging from short-lived correspondences to persistent global scale. However, current architectures impose uniform and pathological influence patterns. For example, sliding windows enforce hard cutoffs, while ungated recurrence and causal attention cause cache saturation and spike-like attention sinks. To resolve this, we formalize geometric propagation as an \emph{evidence influence kernel} and propose HorizonStream, a long-horizon Transformer that explicitly factorizes this kernel. For the long-range temporal factor, Geometric Linear Attention learns channel-wise decay rates to enable bounded, multi-timescale propagation of geometric evidence. For the short-range spatial factor, Geometric Local Attention with Spatiotemporal RoPE performs reliable 3D matching while suppressing attention sinks. Finally, Metric Readout Tokens recover stable scale and rigid pose directly from the persistent geometric state. Extensive experiments show that HorizonStream, trained on only 48-frame clips, generalizes stably to sequences exceeding 10,000\ frames with constant memory and linear time, achieving state-of-the-art streaming 3D reconstruction performance. Project Page: https://3dagentworld.github.io/horizonstream/
HorizonDrive: Self-Corrective Autoregressive World Model for Long-horizon Driving Simulation
May 12, 2026Closed-loop driving simulation requires real-time interaction beyond short offline clips, pushing current driving world models toward autoregressive (AR) rollout. Existing AR distillation approaches typically rely on frame sinks or student-side degradation training. The former transfers poorly to driving due to fast ego-motion and rapid scene changes, while the latter remains bounded by the teacher's single-pass output length and thus provides only a limited supervision horizon. A natural question is: can the teacher itself be extended via AR rollout to provide unbounded-horizon supervision at bounded memory cost? The key difficulty is that a standard teacher drifts under its own predictions, contaminating the supervision it provides. Our key insight is to make the teacher rollout-capable, ensuring reliable supervision from its own AR rollouts. This is instantiated as HorizonDrive, an anti-drifting training-and-distillation framework for AR driving simulation. First, scheduled rollout recovery (SRR) trains the base model to reconstruct ground-truth future clips from prediction-corrupted histories, yielding a teacher that remains stable across long AR rollouts. Second, the rollout-capable teacher is extended via AR rollout, providing long-horizon distribution-matching supervision under bounded memory, while a short-window student aligns to it with teacher rollout DMD (TRD) for efficient real-time deployment. HorizonDrive natively supports minute-scale AR rollout under bounded memory; on nuScenes, HorizonDrive reduces FID by 52% and FVD by 37%, and lowers ARE and DTW by 21% and 9% relative to the strongest long-horizon streaming baselines, while remaining competitive with single-pass driving video generators.
Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
Apr 09, 2026This paper addresses the task of large-scale 3D scene reconstruction from long video sequences. Recent feed-forward reconstruction models have shown promising results by directly regressing 3D geometry from RGB images without explicit 3D priors or geometric constraints. However, these methods often struggle to maintain reconstruction accuracy and consistency over long sequences due to limited memory capacity and the inability to effectively capture global contextual cues. In contrast, humans can naturally exploit the global understanding of the scene to inform local perception. Motivated by this, we propose a novel neural global context representation that efficiently compresses and retains long-range scene information, enabling the model to leverage extensive contextual cues for enhanced reconstruction accuracy and consistency. The context representation is realized through a set of lightweight neural sub-networks that are rapidly adapted during test time via self-supervised objectives, which substantially increases memory capacity without incurring significant computational overhead. The experiments on multiple large-scale benchmarks, including the KITTI Odometry~\cite{Geiger2012CVPR} and Oxford Spires~\cite{tao2025spires} datasets, demonstrate the effectiveness of our approach in handling ultra-large scenes, achieving leading pose accuracy and state-of-the-art 3D reconstruction accuracy while maintaining efficiency. Code is available at https://zju3dv.github.io/scal3r.
Composing Driving Worlds through Disentangled Control for Adversarial Scenario Generation
Mar 13, 2026A major challenge in autonomous driving is the "long tail" of safety-critical edge cases, which often emerge from unusual combinations of common traffic elements. Synthesizing these scenarios is crucial, yet current controllable generative models provide incomplete or entangled guidance, preventing the independent manipulation of scene structure, object identity, and ego actions. We introduce CompoSIA, a compositional driving video simulator that disentangles these traffic factors, enabling fine-grained control over diverse adversarial driving scenarios. To support controllable identity replacement of scene elements, we propose a noise-level identity injection, allowing pose-agnostic identity generation across diverse element poses, all from a single reference image. Furthermore, a hierarchical dual-branch action control mechanism is introduced to improve action controllability. Such disentangled control enables adversarial scenario synthesis-systematically combining safe elements into dangerous configurations that entangled generators cannot produce. Extensive comparisons demonstrate superior controllable generation quality over state-of-the-art baselines, with a 17% improvement in FVD for identity editing and reductions of 30% and 47% in rotation and translation errors for action control. Furthermore, downstream stress-testing reveals substantial planner failures: across editing modalities, the average collision rate of 3s increases by 173%.
TexSpot: 3D Texture Enhancement with Spatially-uniform Point Latent Representation
Feb 14, 2026High-quality 3D texture generation remains a fundamental challenge due to the view-inconsistency inherent in current mainstream multi-view diffusion pipelines. Existing representations either rely on UV maps, which suffer from distortion during unwrapping, or point-based methods, which tightly couple texture fidelity to geometric density that limits high-resolution texture generation. To address these limitations, we introduce TexSpot, a diffusion-based texture enhancement framework. At its core is Texlet, a novel 3D texture representation that merges the geometric expressiveness of point-based 3D textures with the compactness of UV-based representation. Each Texlet latent vector encodes a local texture patch via a 2D encoder and is further aggregated using a 3D encoder to incorporate global shape context. A cascaded 3D-to-2D decoder reconstructs high-quality texture patches, enabling the Texlet space learning. Leveraging this representation, we train a diffusion transformer conditioned on Texlets to refine and enhance textures produced by multi-view diffusion methods. Extensive experiments demonstrate that TexSpot significantly improves visual fidelity, geometric consistency, and robustness over existing state-of-the-art 3D texture generation and enhancement approaches. Project page: https://texlet-arch.github.io/TexSpot-page.
Adaptive-VoCo: Complexity-Aware Visual Token Compression for Vision-Language Models
Dec 20, 2025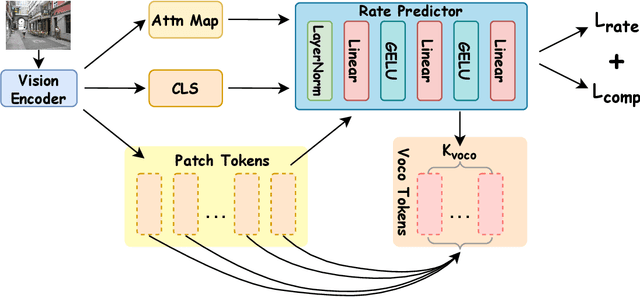
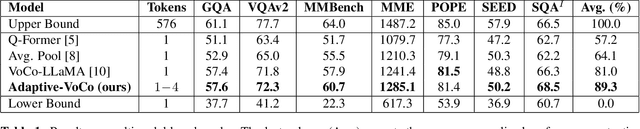
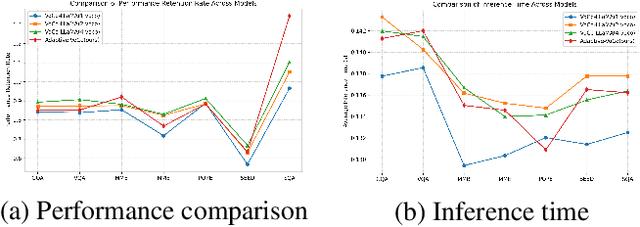
In recent years, large-scale vision-language models (VLMs) have demonstrated remarkable performance on multimodal understanding and reasoning tasks. However, handling high-dimensional visual features often incurs substantial computational and memory costs. VoCo-LLaMA alleviates this issue by compressing visual patch tokens into a few VoCo tokens, reducing computational overhead while preserving strong cross-modal alignment. Nevertheless, such approaches typically adopt a fixed compression rate, limiting their ability to adapt to varying levels of visual complexity. To address this limitation, we propose Adaptive-VoCo, a framework that augments VoCo-LLaMA with a lightweight predictor for adaptive compression. This predictor dynamically selects an optimal compression rate by quantifying an image's visual complexity using statistical cues from the vision encoder, such as patch token entropy and attention map variance. Furthermore, we introduce a joint loss function that integrates rate regularization with complexity alignment. This enables the model to balance inference efficiency with representational capacity, particularly in challenging scenarios. Experimental results show that our method consistently outperforms fixed-rate baselines across multiple multimodal tasks, highlighting the potential of adaptive visual compression for creating more efficient and robust VLMs.
UniPart: Part-Level 3D Generation with Unified 3D Geom-Seg Latents
Dec 10, 2025Part-level 3D generation is essential for applications requiring decomposable and structured 3D synthesis. However, existing methods either rely on implicit part segmentation with limited granularity control or depend on strong external segmenters trained on large annotated datasets. In this work, we observe that part awareness emerges naturally during whole-object geometry learning and propose Geom-Seg VecSet, a unified geometry-segmentation latent representation that jointly encodes object geometry and part-level structure. Building on this representation, we introduce UniPart, a two-stage latent diffusion framework for image-guided part-level 3D generation. The first stage performs joint geometry generation and latent part segmentation, while the second stage conditions part-level diffusion on both whole-object and part-specific latents. A dual-space generation scheme further enhances geometric fidelity by predicting part latents in both global and canonical spaces. Extensive experiments demonstrate that UniPart achieves superior segmentation controllability and part-level geometric quality compared with existing approaches.
MM-CoT:A Benchmark for Probing Visual Chain-of-Thought Reasoning in Multimodal Models
Dec 09, 2025



The ability to perform Chain-of-Thought (CoT) reasoning marks a major milestone for multimodal models (MMs), enabling them to solve complex visual reasoning problems. Yet a critical question remains: is such reasoning genuinely grounded in visual evidence and logically coherent? Existing benchmarks emphasize generation but neglect verification, i.e., the capacity to assess whether a reasoning chain is both visually consistent and logically valid. To fill this gap, we introduce MM-CoT, a diagnostic benchmark specifically designed to probe the visual grounding and logical coherence of CoT reasoning in MMs. Instead of generating free-form explanations, models must select the sole event chain that satisfies two orthogonal constraints: (i) visual consistency, ensuring all steps are anchored in observable evidence, and (ii) logical coherence, ensuring causal and commonsense validity. Adversarial distractors are engineered to violate one of these constraints, exposing distinct reasoning failures. We evaluate leading vision-language models on MM-CoT and find that even the most advanced systems struggle, revealing a sharp discrepancy between generative fluency and true reasoning fidelity. MM-CoT shows low correlation with existing benchmarks, confirming that it measures a unique combination of visual grounding and logical reasoning. This benchmark provides a foundation for developing future models that reason not just plausibly, but faithfully and coherently within the visual world.