 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReformulate LLM Reinforcement Learning for Efficient Training under Black-box Discrepancy
Jun 09, 2026Reinforcement Learning (RL) has emerged as a pivotal post-training paradigm, yet it frequently suffers from unpredictable sub-optimum performance or even training collapses. Recent findings attribute these failures to a hidden train-inference discrepancy (or mismatch), stemming from the disparate underlying engines and architecture. We find that the training policy can actively self-correct such a discrepancy when provided with an appropriate learning signal. Then, we further empirically identify a discrepancy tolerance region: within this region, aggressively narrowing the discrepancy can suppress policy exploration and reduce learning efficiency, whereas outside this region, reducing excessive discrepancy improves optimization consistency and raises the achievable local performance ceiling. According to such findings, we formulate this problem as a Discrepancy-Constrained Markov Decision Process (DCMDP), where reward maximization is coupled with a constraint that aligns training-Inference behavior, achieving stable dual-objective optimization. To adaptively balance performance improvement and discrepancy control, we introduce a Lagrangian relaxation mechanism that dynamically adjusts the relative weight of the two objectives according to the current degree of discrepancy violation. This enables stable dual-objective optimization: the policy is allowed to explore freely within the tolerance region, while being guided back when the discrepancy exceeds the safe boundary. Empirically, DCMDP significantly improves the performance of 8B dense model (Qwen-3-8b) and 30B Mixture-of-Expert model (Qwen-3-30bA3b), and enables a heterogeneous training paradigm, where LLMs can be optimized in high-fidelity training setup while being explicitly aligned for low-cost, resource-constrained inference deployment.
When RL Fails after SFT: Rejuvenating Model Plasticity for Robust SFT-to-RL Handoff
Jun 07, 2026Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) has become a standard pipeline for Large Language Model (LLM) post-training. SFT is expected to provide a useful behavioral prior for RL to further enhance model capabilities. However, checkpoints with excessive SFT often show limited improvement during RL. We attribute this failure to the loss of model plasticity: the reduced ability of an SFT-initialized policy to be effectively reshaped by subsequent RL. To better understand this phenomenon, we conduct detailed analysis from multiple perspectives, including parameter changes, output spaces, and RL optimization dynamics. Our results show that models from excessive SFT tend to produce over-confident token distributions and exhibit sharp parameter landscapes, which make them harder to optimize in the RL stage. To enable a more robust SFT-to-RL handoff, we propose \texttt{Rejuvenation}, a simple yet effective method that restores plasticity while preserving useful SFT-acquired priors. Rejuvenation leverages base-anchored model fusion to reduce excessive SFT-induced drift with targeted neuron reset to mitigate model rigidity. Experimental results on both math reasoning tasks and agentic tasks demonstrate that our approach consistently improves RL performance on over-trained SFT models, while also enhancing generalization to out-of-distribution tasks.
Local Guidance, Global Impact: Gaussian-Reshaped Trust Region Unlocks Behavior Transitions
Jun 04, 2026While Proximal Policy Optimization (PPO) demonstrates strong performance in stationary settings, we show that its standard optimization paradigm struggles in continual and non-stationary environments. The failure does not stem from insufficient model capacity or overly restrictive clipping. Instead, PPO performs persistent, directionally inefficient local updates, which indicates a lack of geometry-aware guidance for accumulating meaningful behavioral change and ultimately hindering transitions toward new behavior patterns. Although divergence-based regularization introduces partial geometric awareness, its monotonically increasing penalties implicitly discourage large policy deviations, even when such shifts are necessary for effective adaptation. To address this limitation, we propose Gaussian Trust Region Policy Optimization (GTR), which reshapes the trust region using a Gaussian kernel. The resulting constraint is bounded and non-monotonic, providing strong local stability while progressively relaxing under sustained high-advantage updates. To further improve robustness, we introduce a Mixture Gaussian Anchor that adapts to recent policy trajectories, reducing variance induced by stale references. GTR is architecture-agnostic and achieves strong performance across games, simulated robotic control, open-world exploration, and language model post-training. These results demonstrate that geometry-aware trust-region design can be a promising direction for robust reinforcement learning in complex non-stationary environments. Our code is available at https://anonymous.4open.science/r/GTR_demo/README.md.
Temporal Difference Learning with Constrained Initial Representations
Feb 12, 2026Recently, there have been numerous attempts to enhance the sample efficiency of off-policy reinforcement learning (RL) agents when interacting with the environment, including architecture improvements and new algorithms. Despite these advances, they overlook the potential of directly constraining the initial representations of the input data, which can intuitively alleviate the distribution shift issue and stabilize training. In this paper, we introduce the Tanh function into the initial layer to fulfill such a constraint. We theoretically unpack the convergence property of the temporal difference learning with the Tanh function under linear function approximation. Motivated by theoretical insights, we present our Constrained Initial Representations framework, tagged CIR, which is made up of three components: (i) the Tanh activation along with normalization methods to stabilize representations; (ii) the skip connection module to provide a linear pathway from the shallow layer to the deep layer; (iii) the convex Q-learning that allows a more flexible value estimate and mitigates potential conservatism. Empirical results show that CIR exhibits strong performance on numerous continuous control tasks, even being competitive or surpassing existing strong baseline methods.
PROF: An LLM-based Reward Code Preference Optimization Framework for Offline Imitation Learning
Nov 14, 2025



Offline imitation learning (offline IL) enables training effective policies without requiring explicit reward annotations. Recent approaches attempt to estimate rewards for unlabeled datasets using a small set of expert demonstrations. However, these methods often assume that the similarity between a trajectory and an expert demonstration is positively correlated with the reward, which oversimplifies the underlying reward structure. We propose PROF, a novel framework that leverages large language models (LLMs) to generate and improve executable reward function codes from natural language descriptions and a single expert trajectory. We propose Reward Preference Ranking (RPR), a novel reward function quality assessment and ranking strategy without requiring environment interactions or RL training. RPR calculates the dominance scores of the reward functions, where higher scores indicate better alignment with expert preferences. By alternating between RPR and text-based gradient optimization, PROF fully automates the selection and refinement of optimal reward functions for downstream policy learning. Empirical results on D4RL demonstrate that PROF surpasses or matches recent strong baselines across numerous datasets and domains, highlighting the effectiveness of our approach.
Attention as a Compass: Efficient Exploration for Process-Supervised RL in Reasoning Models
Sep 30, 2025Reinforcement Learning (RL) has shown remarkable success in enhancing the reasoning capabilities of Large Language Models (LLMs). Process-Supervised RL (PSRL) has emerged as a more effective paradigm compared to outcome-based RL. However, existing PSRL approaches suffer from limited exploration efficiency, both in terms of branching positions and sampling. In this paper, we introduce a novel PSRL framework (AttnRL), which enables efficient exploration for reasoning models. Motivated by preliminary observations that steps exhibiting high attention scores correlate with reasoning behaviors, we propose to branch from positions with high values. Furthermore, we develop an adaptive sampling strategy that accounts for problem difficulty and historical batch size, ensuring that the whole training batch maintains non-zero advantage values. To further improve sampling efficiency, we design a one-step off-policy training pipeline for PSRL. Extensive experiments on multiple challenging mathematical reasoning benchmarks demonstrate that our method consistently outperforms prior approaches in terms of performance and sampling and training efficiency.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
ReviewRL: Towards Automated Scientific Review with RL
Aug 14, 2025Peer review is essential for scientific progress but faces growing challenges due to increasing submission volumes and reviewer fatigue. Existing automated review approaches struggle with factual accuracy, rating consistency, and analytical depth, often generating superficial or generic feedback lacking the insights characteristic of high-quality human reviews. We introduce ReviewRL, a reinforcement learning framework for generating comprehensive and factually grounded scientific paper reviews. Our approach combines: (1) an ArXiv-MCP retrieval-augmented context generation pipeline that incorporates relevant scientific literature, (2) supervised fine-tuning that establishes foundational reviewing capabilities, and (3) a reinforcement learning procedure with a composite reward function that jointly enhances review quality and rating accuracy. Experiments on ICLR 2025 papers demonstrate that ReviewRL significantly outperforms existing methods across both rule-based metrics and model-based quality assessments. ReviewRL establishes a foundational framework for RL-driven automatic critique generation in scientific discovery, demonstrating promising potential for future development in this domain. The implementation of ReviewRL will be released at GitHub.
GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning
Apr 01, 2025Recent advancements in Large Language Models (LLMs) have shown that it is promising to utilize Process Reward Models (PRMs) as verifiers to enhance the performance of LLMs. However, current PRMs face three key challenges: (1) limited process supervision and generalization capabilities, (2) dependence on scalar value prediction without leveraging the generative abilities of LLMs, and (3) inability to scale the test-time compute of PRMs. In this work, we introduce GenPRM, a generative process reward model that performs explicit Chain-of-Thought (CoT) reasoning with code verification before providing judgment for each reasoning step. To obtain high-quality process supervision labels and rationale data, we propose Relative Progress Estimation (RPE) and a rationale synthesis framework that incorporates code verification. Experimental results on ProcessBench and several mathematical reasoning tasks show that GenPRM significantly outperforms prior PRMs with only 23K training data from MATH dataset. Through test-time scaling, a 1.5B GenPRM outperforms GPT-4o, and a 7B GenPRM surpasses Qwen2.5-Math-PRM-72B on ProcessBench. Additionally, GenPRM demonstrates strong abilities to serve as a critic model for policy model refinement. This work establishes a new paradigm for process supervision that bridges the gap between PRMs and critic models in LLMs. Our code, model, and data will be available in https://ryanliu112.github.io/GenPRM.
VLP: Vision-Language Preference Learning for Embodied Manipulation
Feb 17, 2025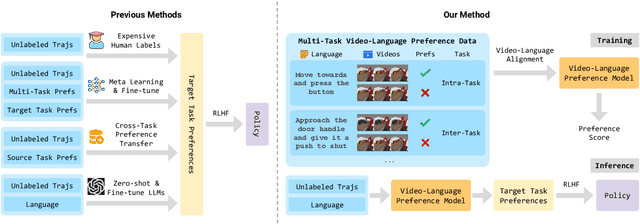

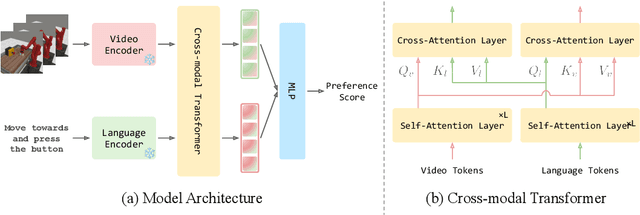
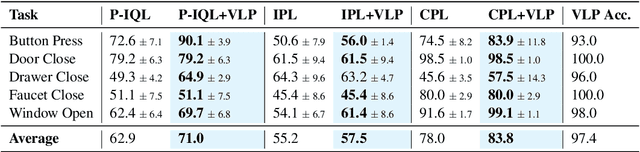
Reward engineering is one of the key challenges in Reinforcement Learning (RL). Preference-based RL effectively addresses this issue by learning from human feedback. However, it is both time-consuming and expensive to collect human preference labels. In this paper, we propose a novel \textbf{V}ision-\textbf{L}anguage \textbf{P}reference learning framework, named \textbf{VLP}, which learns a vision-language preference model to provide preference feedback for embodied manipulation tasks. To achieve this, we define three types of language-conditioned preferences and construct a vision-language preference dataset, which contains versatile implicit preference orders without human annotations. The preference model learns to extract language-related features, and then serves as a preference annotator in various downstream tasks. The policy can be learned according to the annotated preferences via reward learning or direct policy optimization. Extensive empirical results on simulated embodied manipulation tasks demonstrate that our method provides accurate preferences and generalizes to unseen tasks and unseen language instructions, outperforming the baselines by a large margin.