 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Auto-Bidding with Unified Modeling and Exploration
May 19, 2026Automated bidding is central to modern digital advertising. Early rule-based methods lacked adaptability, while subsequent Reinforcement Learning approaches modeled bidding as a Markov Decision Process but struggled with long-term dependencies. Recent generative models show promise, yet they lack explicit mechanisms to balance exploration and safety, relying solely on action perturbations or trajectory guidance without a safety fallback. This results in inefficient exploration and elevated financial risk for advertising platforms. To address this gap, we propose GUIDE (Generative Auto-Bidding with Unified Modeling and Exploration), a framework that synergistically integrates directed exploration with a safe fallback mechanism. GUIDE employs a Decision Transformer (DT) to jointly model historical bidding actions and environmental state transitions. A Q-value module guides the DT's exploration via regularization constraints, while an Inverse Dynamics Module (IDM) leverages DT-predicted future states to infer robust, behaviorally consistent actions as a safe policy fallback. The Q-value module then adaptively selects the final action between these two options, balancing exploration and safety. Together, these components form an integrated "explore-safeguard-select" pipeline that unifies efficiency and safety. We conduct extensive experiments on public datasets, in simulated auction environments, and through large-scale online deployment on Taobao, a leading Chinese advertising platform. Results show GUIDE consistently outperforms state-of-the-art baselines across all scenarios. In real-world deployment, GUIDE achieves notable gains: +4.10% ad GMV, +1.40% ad clicks, +1.66% ad cost, and +3.52% ad ROI, demonstrating its effectiveness and strong industrial applicability.
Cross-Domain Offline Policy Adaptation via Selective Transition Correction
Feb 05, 2026It remains a critical challenge to adapt policies across domains with mismatched dynamics in reinforcement learning (RL). In this paper, we study cross-domain offline RL, where an offline dataset from another similar source domain can be accessed to enhance policy learning upon a target domain dataset. Directly merging the two datasets may lead to suboptimal performance due to potential dynamics mismatches. Existing approaches typically mitigate this issue through source domain transition filtering or reward modification, which, however, may lead to insufficient exploitation of the valuable source domain data. Instead, we propose to modify the source domain data into the target domain data. To that end, we leverage an inverse policy model and a reward model to correct the actions and rewards of source transitions, explicitly achieving alignment with the target dynamics. Since limited data may result in inaccurate model training, we further employ a forward dynamics model to retain corrected samples that better match the target dynamics than the original transitions. Consequently, we propose the Selective Transition Correction (STC) algorithm, which enables reliable usage of source domain data for policy adaptation. Experiments on various environments with dynamics shifts demonstrate that STC achieves superior performance against existing baselines.
AM$^3$Safety: Towards Data Efficient Alignment of Multi-modal Multi-turn Safety for MLLMs
Jan 08, 2026Multi-modal Large Language Models (MLLMs) are increasingly deployed in interactive applications. However, their safety vulnerabilities become pronounced in multi-turn multi-modal scenarios, where harmful intent can be gradually reconstructed across turns, and security protocols fade into oblivion as the conversation progresses. Existing Reinforcement Learning from Human Feedback (RLHF) alignment methods are largely developed for single-turn visual question-answer (VQA) task and often require costly manual preference annotations, limiting their effectiveness and scalability in dialogues. To address this challenge, we present InterSafe-V, an open-source multi-modal dialogue dataset containing 11,270 dialogues and 500 specially designed refusal VQA samples. This dataset, constructed through interaction between several models, is designed to more accurately reflect real-world scenarios and includes specialized VQA pairs tailored for specific domains. Building on this dataset, we propose AM$^3$Safety, a framework that combines a cold-start refusal phase with Group Relative Policy Optimization (GRPO) fine-tuning using turn-aware dual-objective rewards across entire dialogues. Experiments on Qwen2.5-VL-7B-Instruct and LLaVA-NeXT-7B show more than 10\% decrease in Attack Success Rate (ASR) together with an increment of at least 8\% in harmless dimension and over 13\% in helpful dimension of MLLMs on multi-modal multi-turn safety benchmarks, while preserving their general abilities.
PROF: An LLM-based Reward Code Preference Optimization Framework for Offline Imitation Learning
Nov 14, 2025



Offline imitation learning (offline IL) enables training effective policies without requiring explicit reward annotations. Recent approaches attempt to estimate rewards for unlabeled datasets using a small set of expert demonstrations. However, these methods often assume that the similarity between a trajectory and an expert demonstration is positively correlated with the reward, which oversimplifies the underlying reward structure. We propose PROF, a novel framework that leverages large language models (LLMs) to generate and improve executable reward function codes from natural language descriptions and a single expert trajectory. We propose Reward Preference Ranking (RPR), a novel reward function quality assessment and ranking strategy without requiring environment interactions or RL training. RPR calculates the dominance scores of the reward functions, where higher scores indicate better alignment with expert preferences. By alternating between RPR and text-based gradient optimization, PROF fully automates the selection and refinement of optimal reward functions for downstream policy learning. Empirical results on D4RL demonstrate that PROF surpasses or matches recent strong baselines across numerous datasets and domains, highlighting the effectiveness of our approach.
Delta Decompression for MoE-based LLMs Compression
Feb 24, 2025



Mixture-of-Experts (MoE) architectures in large language models (LLMs) achieve exceptional performance, but face prohibitive storage and memory requirements. To address these challenges, we present $D^2$-MoE, a new delta decompression compressor for reducing the parameters of MoE LLMs. Based on observations of expert diversity, we decompose their weights into a shared base weight and unique delta weights. Specifically, our method first merges each expert's weight into the base weight using the Fisher information matrix to capture shared components. Then, we compress delta weights through Singular Value Decomposition (SVD) by exploiting their low-rank properties. Finally, we introduce a semi-dynamical structured pruning strategy for the base weights, combining static and dynamic redundancy analysis to achieve further parameter reduction while maintaining input adaptivity. In this way, our $D^2$-MoE successfully compact MoE LLMs to high compression ratios without additional training. Extensive experiments highlight the superiority of our approach, with over 13% performance gains than other compressors on Mixtral|Phi-3.5|DeepSeek|Qwen2 MoE LLMs at 40$\sim$60% compression rates. Codes are available in https://github.com/lliai/D2MoE.
VLP: Vision-Language Preference Learning for Embodied Manipulation
Feb 17, 2025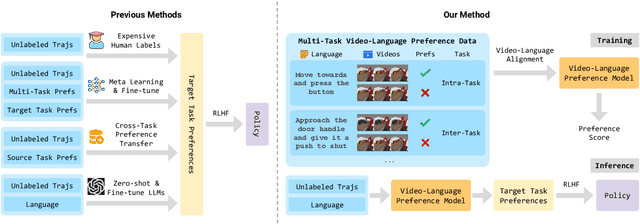

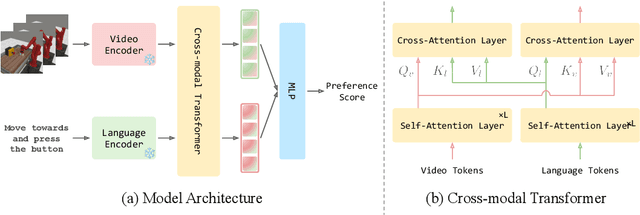
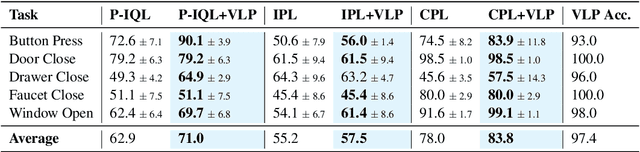
Reward engineering is one of the key challenges in Reinforcement Learning (RL). Preference-based RL effectively addresses this issue by learning from human feedback. However, it is both time-consuming and expensive to collect human preference labels. In this paper, we propose a novel \textbf{V}ision-\textbf{L}anguage \textbf{P}reference learning framework, named \textbf{VLP}, which learns a vision-language preference model to provide preference feedback for embodied manipulation tasks. To achieve this, we define three types of language-conditioned preferences and construct a vision-language preference dataset, which contains versatile implicit preference orders without human annotations. The preference model learns to extract language-related features, and then serves as a preference annotator in various downstream tasks. The policy can be learned according to the annotated preferences via reward learning or direct policy optimization. Extensive empirical results on simulated embodied manipulation tasks demonstrate that our method provides accurate preferences and generalizes to unseen tasks and unseen language instructions, outperforming the baselines by a large margin.
A Large Language Model-Driven Reward Design Framework via Dynamic Feedback for Reinforcement Learning
Oct 18, 2024



Large Language Models (LLMs) have shown significant potential in designing reward functions for Reinforcement Learning (RL) tasks. However, obtaining high-quality reward code often involves human intervention, numerous LLM queries, or repetitive RL training. To address these issues, we propose CARD, a LLM-driven Reward Design framework that iteratively generates and improves reward function code. Specifically, CARD includes a Coder that generates and verifies the code, while a Evaluator provides dynamic feedback to guide the Coder in improving the code, eliminating the need for human feedback. In addition to process feedback and trajectory feedback, we introduce Trajectory Preference Evaluation (TPE), which evaluates the current reward function based on trajectory preferences. If the code fails the TPE, the Evaluator provides preference feedback, avoiding RL training at every iteration and making the reward function better aligned with the task objective. Empirical results on Meta-World and ManiSkill2 demonstrate that our method achieves an effective balance between task performance and token efficiency, outperforming or matching the baselines across all tasks. On 10 out of 12 tasks, CARD shows better or comparable performance to policies trained with expert-designed rewards, and our method even surpasses the oracle on 3 tasks.
EdgeNet : Encoder-decoder generative Network for Auction Design in E-commerce Online Advertising
May 09, 2023


We present a new encoder-decoder generative network dubbed EdgeNet, which introduces a novel encoder-decoder framework for data-driven auction design in online e-commerce advertising. We break the neural auction paradigm of Generalized-Second-Price(GSP), and improve the utilization efficiency of data while ensuring the economic characteristics of the auction mechanism. Specifically, EdgeNet introduces a transformer-based encoder to better capture the mutual influence among different candidate advertisements. In contrast to GSP based neural auction model, we design an autoregressive decoder to better utilize the rich context information in online advertising auctions. EdgeNet is conceptually simple and easy to extend to the existing end-to-end neural auction framework. We validate the efficiency of EdgeNet on a wide range of e-commercial advertising auction, demonstrating its potential in improving user experience and platform revenue.
Time-aware Graph Embedding: A temporal smoothness and task-oriented approach
Jul 22, 2020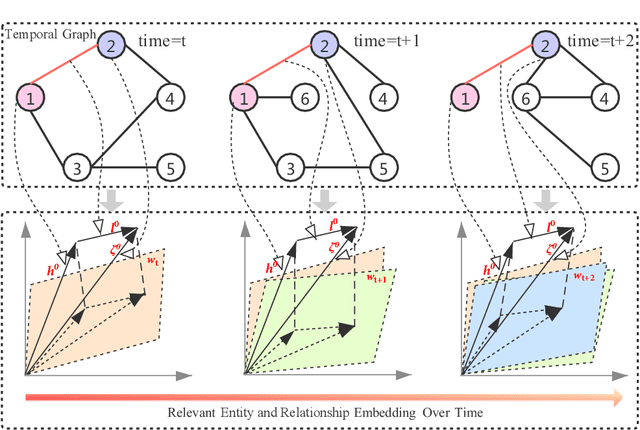

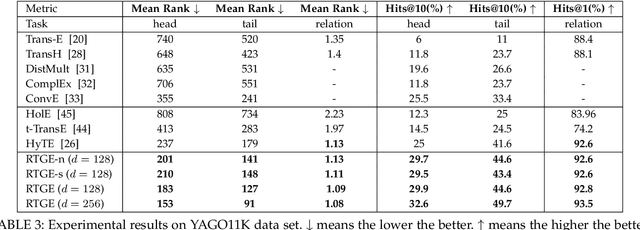
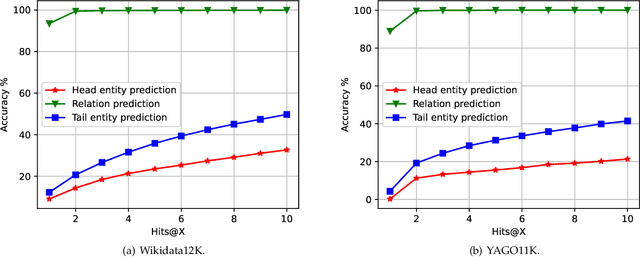
Knowledge graph embedding, which aims to learn the low-dimensional representations of entities and relationships, has attracted considerable research efforts recently. However, most knowledge graph embedding methods focus on the structural relationships in fixed triples while ignoring the temporal information. Currently, existing time-aware graph embedding methods only focus on the factual plausibility, while ignoring the temporal smoothness which models the interactions between a fact and its contexts, and thus can capture fine-granularity temporal relationships. This leads to the limited performance of embedding related applications. To solve this problem, this paper presents a Robustly Time-aware Graph Embedding (RTGE) method by incorporating temporal smoothness. Two major innovations of our paper are presented here. At first, RTGE integrates a measure of temporal smoothness in the learning process of the time-aware graph embedding. Via the proposed additional smoothing factor, RTGE can preserve both structural information and evolutionary patterns of a given graph. Secondly, RTGE provides a general task-oriented negative sampling strategy associated with temporally-aware information, which further improves the adaptive ability of the proposed algorithm and plays an essential role in obtaining superior performance in various tasks. Extensive experiments conducted on multiple benchmark tasks show that RTGE can increase performance in entity/relationship/temporal scoping prediction tasks.
Optimal Delivery with Budget Constraint in E-Commerce Advertising
Oct 08, 2019


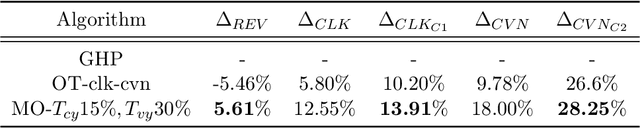
Online advertising in E-commerce platforms provides sellers an opportunity to achieve potential audiences with different target goals. Ad serving systems (like display and search advertising systems) that assign ads to pages should satisfy objectives such as plenty of audience for branding advertisers, clicks or conversions for performance-based advertisers, at the same time try to maximize overall revenue of the platform. In this paper, we propose an approach based on linear programming subjects to constraints in order to optimize the revenue and improve different performance goals simultaneously. We have validated our algorithm by implementing an offline simulation system in Alibaba E-commerce platform and running the auctions from online requests which takes system performance, ranking and pricing schemas into account. We have also compared our algorithm with related work, and the results show that our algorithm can effectively improve campaign performance and revenue of the platform.