 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSCAR: Optimization-Steered Agentic Planning for Composed Image Retrieval
Feb 09, 2026Composed image retrieval (CIR) requires complex reasoning over heterogeneous visual and textual constraints. Existing approaches largely fall into two paradigms: unified embedding retrieval, which suffers from single-model myopia, and heuristic agentic retrieval, which is limited by suboptimal, trial-and-error orchestration. To this end, we propose OSCAR, an optimization-steered agentic planning framework for composed image retrieval. We are the first to reformulate agentic CIR from a heuristic search process into a principled trajectory optimization problem. Instead of relying on heuristic trial-and-error exploration, OSCAR employs a novel offline-online paradigm. In the offline phase, we model CIR via atomic retrieval selection and composition as a two-stage mixed-integer programming problem, mathematically deriving optimal trajectories that maximize ground-truth coverage for training samples via rigorous boolean set operations. These trajectories are then stored in a golden library to serve as in-context demonstrations for online steering of VLM planner at online inference time. Extensive experiments on three public benchmarks and a private industrial benchmark show that OSCAR consistently outperforms SOTA baselines. Notably, it achieves superior performance using only 10% of training data, demonstrating strong generalization of planning logic rather than dataset-specific memorization.
Exploiting the Randomness of Large Language Models (LLM) in Text Classification Tasks: Locating Privileged Documents in Legal Matters
Dec 08, 2025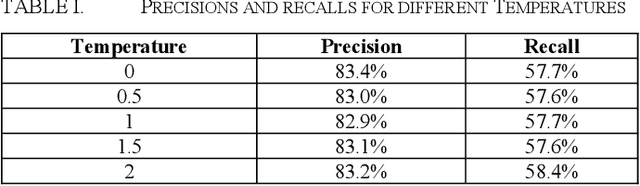
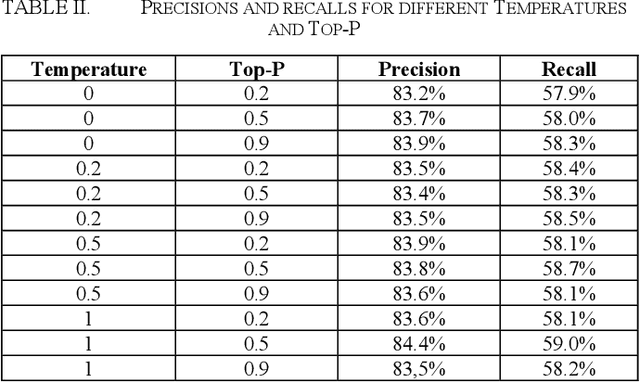
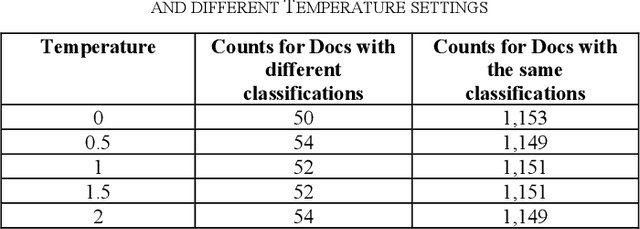
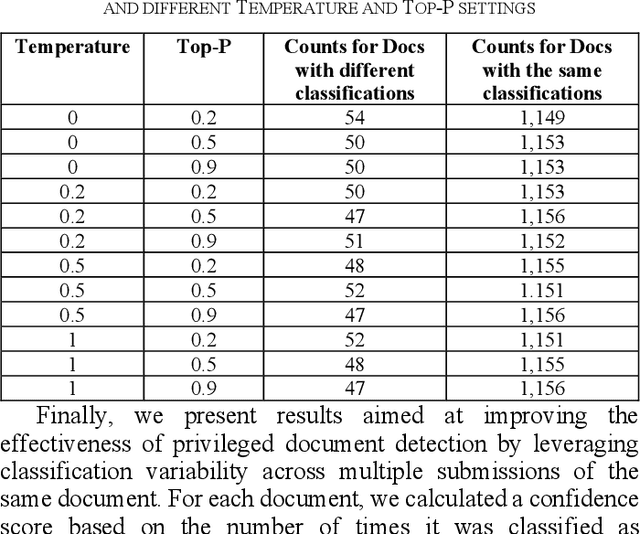
In legal matters, text classification models are most often used to filter through large datasets in search of documents that meet certain pre-selected criteria like relevance to a certain subject matter, such as legally privileged communications and attorney-directed documents. In this context, large language models have demonstrated strong performance. This paper presents an empirical study investigating the role of randomness in LLM-based classification for attorney-client privileged document detection, focusing on four key dimensions: (1) the effectiveness of LLMs in identifying legally privileged documents, (2) the influence of randomness control parameters on classification outputs, (3) their impact on overall classification performance, and (4) a methodology for leveraging randomness to enhance accuracy. Experimental results showed that LLMs can identify privileged documents effectively, randomness control parameters have minimal impact on classification performance, and importantly, our developed methodology for leveraging randomness can have a significant impact on improving accuracy. Notably, this methodology that leverages randomness could also enhance a corporation's confidence in an LLM's output when incorporated into its sanctions-compliance processes. As organizations increasingly rely on LLMs to augment compliance workflows, reducing output variability helps build internal and regulatory confidence in LLM-derived sanctions-screening decisions.
A Comparative Study of Retrieval Methods in Azure AI Search
Dec 08, 2025Increasingly, attorneys are interested in moving beyond keyword and semantic search to improve the efficiency of how they find key information during a document review task. Large language models (LLMs) are now seen as tools that attorneys can use to ask natural language questions of their data during document review to receive accurate and concise answers. This study evaluates retrieval strategies within Microsoft Azure's Retrieval-Augmented Generation (RAG) framework to identify effective approaches for Early Case Assessment (ECA) in eDiscovery. During ECA, legal teams analyze data at the outset of a matter to gain a general understanding of the data and attempt to determine key facts and risks before beginning full-scale review. In this paper, we compare the performance of Azure AI Search's keyword, semantic, vector, hybrid, and hybrid-semantic retrieval methods. We then present the accuracy, relevance, and consistency of each method's AI-generated responses. Legal practitioners can use the results of this study to enhance how they select RAG configurations in the future.
Leveraging Machine Learning and Large Language Models for Automated Image Clustering and Description in Legal Discovery
Dec 08, 2025The rapid increase in digital image creation and retention presents substantial challenges during legal discovery, digital archive, and content management. Corporations and legal teams must organize, analyze, and extract meaningful insights from large image collections under strict time pressures, making manual review impractical and costly. These demands have intensified interest in automated methods that can efficiently organize and describe large-scale image datasets. This paper presents a systematic investigation of automated cluster description generation through the integration of image clustering, image captioning, and large language models (LLMs). We apply K-means clustering to group images into 20 visually coherent clusters and generate base captions using the Azure AI Vision API. We then evaluate three critical dimensions of the cluster description process: (1) image sampling strategies, comparing random, centroid-based, stratified, hybrid, and density-based sampling against using all cluster images; (2) prompting techniques, contrasting standard prompting with chain-of-thought prompting; and (3) description generation methods, comparing LLM-based generation with traditional TF-IDF and template-based approaches. We assess description quality using semantic similarity and coverage metrics. Results show that strategic sampling with 20 images per cluster performs comparably to exhaustive inclusion while significantly reducing computational cost, with only stratified sampling showing modest degradation. LLM-based methods consistently outperform TF-IDF baselines, and standard prompts outperform chain-of-thought prompts for this task. These findings provide practical guidance for deploying scalable, accurate cluster description systems that support high-volume workflows in legal discovery and other domains requiring automated organization of large image collections.
Detecting Privileged Documents by Ranking Connected Network Entities
Dec 08, 2025



This paper presents a link analysis approach for identifying privileged documents by constructing a network of human entities derived from email header metadata. Entities are classified as either counsel or non-counsel based on a predefined list of known legal professionals. The core assumption is that individuals with frequent interactions with lawyers are more likely to participate in privileged communications. To quantify this likelihood, an algorithm assigns a score to each entity within the network. By utilizing both entity scores and the strength of their connections, the method enhances the identification of privileged documents. Experimental results demonstrate the algorithm's effectiveness in ranking legal entities for privileged document detection.
Entropy-Memorization Law: Evaluating Memorization Difficulty of Data in LLMs
Jul 08, 2025Large Language Models (LLMs) are known to memorize portions of their training data, sometimes reproducing content verbatim when prompted appropriately. In this work, we investigate a fundamental yet under-explored question in the domain of memorization: How to characterize memorization difficulty of training data in LLMs? Through empirical experiments on OLMo, a family of open models, we present the Entropy-Memorization Law. It suggests that data entropy is linearly correlated with memorization score. Moreover, in a case study of memorizing highly randomized strings, or "gibberish", we observe that such sequences, despite their apparent randomness, exhibit unexpectedly low empirical entropy compared to the broader training corpus. Adopting the same strategy to discover Entropy-Memorization Law, we derive a simple yet effective approach to distinguish training and testing data, enabling Dataset Inference (DI).
VisBias: Measuring Explicit and Implicit Social Biases in Vision Language Models
Mar 10, 2025



This research investigates both explicit and implicit social biases exhibited by Vision-Language Models (VLMs). The key distinction between these bias types lies in the level of awareness: explicit bias refers to conscious, intentional biases, while implicit bias operates subconsciously. To analyze explicit bias, we directly pose questions to VLMs related to gender and racial differences: (1) Multiple-choice questions based on a given image (e.g., "What is the education level of the person in the image?") (2) Yes-No comparisons using two images (e.g., "Is the person in the first image more educated than the person in the second image?") For implicit bias, we design tasks where VLMs assist users but reveal biases through their responses: (1) Image description tasks: Models are asked to describe individuals in images, and we analyze disparities in textual cues across demographic groups. (2) Form completion tasks: Models draft a personal information collection form with 20 attributes, and we examine correlations among selected attributes for potential biases. We evaluate Gemini-1.5, GPT-4V, GPT-4o, LLaMA-3.2-Vision and LLaVA-v1.6. Our code and data are publicly available at https://github.com/uscnlp-lime/VisBias.
DA-STGCN: 4D Trajectory Prediction Based on Spatiotemporal Feature Extraction
Mar 05, 2025The importance of four-dimensional (4D) trajectory prediction within air traffic management systems is on the rise. Key operations such as conflict detection and resolution, aircraft anomaly monitoring, and the management of congested flight paths are increasingly reliant on this foundational technology, underscoring the urgent demand for intelligent solutions. The dynamics in airport terminal zones and crowded airspaces are intricate and ever-changing; however, current methodologies do not sufficiently account for the interactions among aircraft. To tackle these challenges, we propose DA-STGCN, an innovative spatiotemporal graph convolutional network that integrates a dual attention mechanism. Our model reconstructs the adjacency matrix through a self-attention approach, enhancing the capture of node correlations, and employs graph attention to distill spatiotemporal characteristics, thereby generating a probabilistic distribution of predicted trajectories. This novel adjacency matrix, reconstructed with the self-attention mechanism, is dynamically optimized throughout the network's training process, offering a more nuanced reflection of the inter-node relationships compared to traditional algorithms. The performance of the model is validated on two ADS-B datasets, one near the airport terminal area and the other in dense airspace. Experimental results demonstrate a notable improvement over current 4D trajectory prediction methods, achieving a 20% and 30% reduction in the Average Displacement Error (ADE) and Final Displacement Error (FDE), respectively. The incorporation of a Dual-Attention module has been shown to significantly enhance the extraction of node correlations, as verified by ablation experiments.
Generative Models in Decision Making: A Survey
Feb 25, 2025In recent years, the exceptional performance of generative models in generative tasks has sparked significant interest in their integration into decision-making processes. Due to their ability to handle complex data distributions and their strong model capacity, generative models can be effectively incorporated into decision-making systems by generating trajectories that guide agents toward high-reward state-action regions or intermediate sub-goals. This paper presents a comprehensive review of the application of generative models in decision-making tasks. We classify seven fundamental types of generative models: energy-based models, generative adversarial networks, variational autoencoders, normalizing flows, diffusion models, generative flow networks, and autoregressive models. Regarding their applications, we categorize their functions into three main roles: controllers, modelers and optimizers, and discuss how each role contributes to decision-making. Furthermore, we examine the deployment of these models across five critical real-world decision-making scenarios. Finally, we summarize the strengths and limitations of current approaches and propose three key directions for advancing next-generation generative directive models: high-performance algorithms, large-scale generalized decision-making models, and self-evolving and adaptive models.
Certifying Language Model Robustness with Fuzzed Randomized Smoothing: An Efficient Defense Against Backdoor Attacks
Feb 09, 2025The widespread deployment of pre-trained language models (PLMs) has exposed them to textual backdoor attacks, particularly those planted during the pre-training stage. These attacks pose significant risks to high-reliability applications, as they can stealthily affect multiple downstream tasks. While certifying robustness against such threats is crucial, existing defenses struggle with the high-dimensional, interdependent nature of textual data and the lack of access to original poisoned pre-training data. To address these challenges, we introduce \textbf{F}uzzed \textbf{R}andomized \textbf{S}moothing (\textbf{FRS}), a novel approach for efficiently certifying language model robustness against backdoor attacks. FRS integrates software robustness certification techniques with biphased model parameter smoothing, employing Monte Carlo tree search for proactive fuzzing to identify vulnerable textual segments within the Damerau-Levenshtein space. This allows for targeted and efficient text randomization, while eliminating the need for access to poisoned training data during model smoothing. Our theoretical analysis demonstrates that FRS achieves a broader certified robustness radius compared to existing methods. Extensive experiments across various datasets, model configurations, and attack strategies validate FRS's superiority in terms of defense efficiency, accuracy, and robustness.