 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAHA: Aligning Large Audio-Language Models for Reasoning Hallucinations via Counterfactual Hard Negatives
Dec 30, 2025Although Large Audio-Language Models (LALMs) deliver state-of-the-art (SOTA) performance, they frequently suffer from hallucinations, e.g. generating text not grounded in the audio input. We analyze these grounding failures and identify a distinct taxonomy: Event Omission, False Event Identity, Temporal Relation Error, and Quantitative Temporal Error. To address this, we introduce the AHA (Audio Hallucination Alignment) framework. By leveraging counterfactual hard negative mining, our pipeline constructs a high-quality preference dataset that forces models to distinguish strict acoustic evidence from linguistically plausible fabrications. Additionally, we establish AHA-Eval, a diagnostic benchmark designed to rigorously test these fine-grained temporal reasoning capabilities. We apply this data to align Qwen2.5-Omni. The resulting model, Qwen-Audio-AHA, achieves a 13.7% improvement on AHA-Eval. Crucially, this benefit generalizes beyond our diagnostic set. Our model shows substantial gains on public benchmarks, including 1.3% on MMAU-Test and 1.6% on MMAR, outperforming latest SOTA methods.
TravelBench: A Real-World Benchmark for Multi-Turn and Tool-Augmented Travel Planning
Dec 27, 2025Large language model (LLM) agents have demonstrated strong capabilities in planning and tool use. Travel planning provides a natural and high-impact testbed for these capabilities, as it requires multi-step reasoning, iterative preference elicitation through interaction, and calls to external tools under evolving constraints. Prior work has studied LLMs on travel-planning tasks, but existing settings are limited in domain coverage and multi-turn interaction. As a result, they cannot support dynamic user-agent interaction and therefore fail to comprehensively assess agent capabilities. In this paper, we introduce TravelBench, a real-world travel-planning benchmark featuring multi-turn interaction and tool use. We collect user requests from real-world scenarios and construct three subsets-multi-turn, single-turn, and unsolvable-to evaluate different aspects of agent performance. For stable and reproducible evaluation, we build a controlled sandbox environment with 10 travel-domain tools, providing deterministic tool outputs for reliable reasoning. We evaluate multiple LLMs on TravelBench and conduct an analysis of their behaviors and performance. TravelBench offers a practical and reproducible benchmark for advancing LLM agents in travel planning.
ManchuTTS: Towards High-Quality Manchu Speech Synthesis via Flow Matching and Hierarchical Text Representation
Dec 27, 2025As an endangered language, Manchu presents unique challenges for speech synthesis, including severe data scarcity and strong phonological agglutination. This paper proposes ManchuTTS(Manchu Text to Speech), a novel approach tailored to Manchu's linguistic characteristics. To handle agglutination, this method designs a three-tier text representation (phoneme, syllable, prosodic) and a cross-modal hierarchical attention mechanism for multi-granular alignment. The synthesis model integrates deep convolutional networks with a flow-matching Transformer, enabling efficient, non-autoregressive generation. This method further introduce a hierarchical contrastive loss to guide structured acoustic-linguistic correspondence. To address low-resource constraints, This method construct the first Manchu TTS dataset and employ a data augmentation strategy. Experiments demonstrate that ManchuTTS attains a MOS of 4.52 using a 5.2-hour training subset derived from our full 6.24-hour annotated corpus, outperforming all baseline models by a notable margin. Ablations confirm hierarchical guidance improves agglutinative word pronunciation accuracy (AWPA) by 31% and prosodic naturalness by 27%.
Asynchronous Fast-Slow Vision-Language-Action Policies for Whole-Body Robotic Manipulation
Dec 23, 2025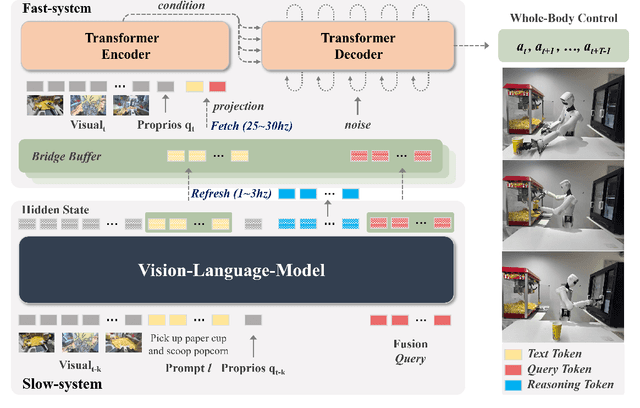

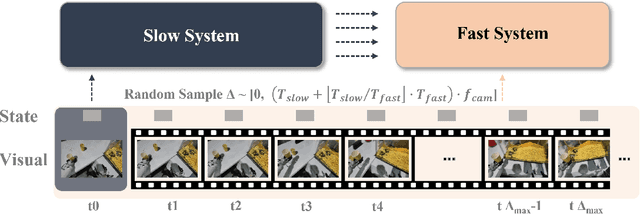

Most Vision-Language-Action (VLA) systems integrate a Vision-Language Model (VLM) for semantic reasoning with an action expert generating continuous action signals, yet both typically run at a single unified frequency. As a result, policy performance is constrained by the low inference speed of large VLMs. This mandatory synchronous execution severely limits control stability and real-time performance in whole-body robotic manipulation, which involves more joints, larger motion spaces, and dynamically changing views. We introduce a truly asynchronous Fast-Slow VLA framework (DuoCore-FS), organizing the system into a fast pathway for high-frequency action generation and a slow pathway for rich VLM reasoning. The system is characterized by two key features. First, a latent representation buffer bridges the slow and fast systems. It stores instruction semantics and action-reasoning representation aligned with the scene-instruction context, providing high-level guidance to the fast pathway. Second, a whole-body action tokenizer provides a compact, unified representation of whole-body actions. Importantly, the VLM and action expert are still jointly trained end-to-end, preserving unified policy learning while enabling asynchronous execution. DuoCore-FS supports a 3B-parameter VLM while achieving 30 Hz whole-body action-chunk generation, approximately three times as fast as prior VLA models with comparable model sizes. Real-world whole-body manipulation experiments demonstrate improved task success rates and significantly enhanced responsiveness compared to synchronous Fast-Slow VLA baselines. The implementation of DuoCore-FS, including training, inference, and deployment, is provided to commercial users by Astribot as part of the Astribot robotic platform.
The Geometry of Abstraction: Continual Learning via Recursive Quotienting
Dec 20, 2025Continual learning systems operating in fixed-dimensional spaces face a fundamental geometric barrier: the flat manifold problem. When experience is represented as a linear trajectory in Euclidean space, the geodesic distance between temporal events grows linearly with time, forcing the required covering number to diverge. In fixed-dimensional hardware, this volume expansion inevitably forces trajectory overlap, manifesting as catastrophic interference. In this work, we propose a geometric resolution to this paradox based on Recursive Metric Contraction. We formalize abstraction not as symbolic grouping, but as a topological deformation: a quotient map that collapses the metric tensor within validated temporal neighborhoods, effectively driving the diameter of local sub-manifolds to zero. We substantiate our framework with four rigorous results. First, the Bounded Capacity Theorem establishes that recursive quotient maps allow the embedding of arbitrarily long trajectories into bounded representational volumes, trading linear metric growth for logarithmic topological depth. Second, the Topological Collapse Separability Theorem, derived via Urysohn's Lemma, proves that recursive quotienting renders non-linearly separable temporal sequences linearly separable in the limit, bypassing the need for infinite-dimensional kernel projections. Third, the Parity-Partitioned Stability Theorem solves the catastrophic forgetting problem by proving that if the state space is partitioned into orthogonal flow and scaffold manifolds, the metric deformations of active learning do not disturb the stability of stored memories. Our analysis reveals that tokens in neural architectures are physically realizable as singularities or wormholes, regions of extreme positive curvature that bridge distant points in the temporal manifold.
A Semantically Enhanced Generative Foundation Model Improves Pathological Image Synthesis
Dec 16, 2025



The development of clinical-grade artificial intelligence in pathology is limited by the scarcity of diverse, high-quality annotated datasets. Generative models offer a potential solution but suffer from semantic instability and morphological hallucinations that compromise diagnostic reliability. To address this challenge, we introduce a Correlation-Regulated Alignment Framework for Tissue Synthesis (CRAFTS), the first generative foundation model for pathology-specific text-to-image synthesis. By leveraging a dual-stage training strategy on approximately 2.8 million image-caption pairs, CRAFTS incorporates a novel alignment mechanism that suppresses semantic drift to ensure biological accuracy. This model generates diverse pathological images spanning 30 cancer types, with quality rigorously validated by objective metrics and pathologist evaluations. Furthermore, CRAFTS-augmented datasets enhance the performance across various clinical tasks, including classification, cross-modal retrieval, self-supervised learning, and visual question answering. In addition, coupling CRAFTS with ControlNet enables precise control over tissue architecture from inputs such as nuclear segmentation masks and fluorescence images. By overcoming the critical barriers of data scarcity and privacy concerns, CRAFTS provides a limitless source of diverse, annotated histology data, effectively unlocking the creation of robust diagnostic tools for rare and complex cancer phenotypes.
DirectSwap: Mask-Free Cross-Identity Training and Benchmarking for Expression-Consistent Video Head Swapping
Dec 10, 2025
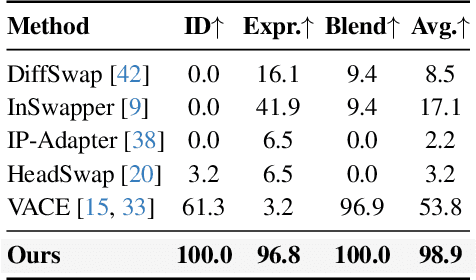
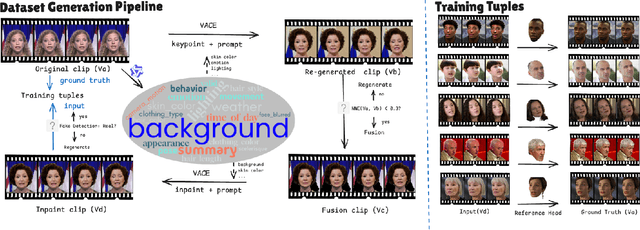
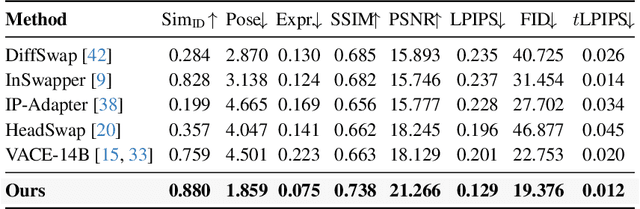
Video head swapping aims to replace the entire head of a video subject, including facial identity, head shape, and hairstyle, with that of a reference image, while preserving the target body, background, and motion dynamics. Due to the lack of ground-truth paired swapping data, prior methods typically train on cross-frame pairs of the same person within a video and rely on mask-based inpainting to mitigate identity leakage. Beyond potential boundary artifacts, this paradigm struggles to recover essential cues occluded by the mask, such as facial pose, expressions, and motion dynamics. To address these issues, we prompt a video editing model to synthesize new heads for existing videos as fake swapping inputs, while maintaining frame-synchronized facial poses and expressions. This yields HeadSwapBench, the first cross-identity paired dataset for video head swapping, which supports both training (\TrainNum{} videos) and benchmarking (\TestNum{} videos) with genuine outputs. Leveraging this paired supervision, we propose DirectSwap, a mask-free, direct video head-swapping framework that extends an image U-Net into a video diffusion model with a motion module and conditioning inputs. Furthermore, we introduce the Motion- and Expression-Aware Reconstruction (MEAR) loss, which reweights the diffusion loss per pixel using frame-difference magnitudes and facial-landmark proximity, thereby enhancing cross-frame coherence in motion and expressions. Extensive experiments demonstrate that DirectSwap achieves state-of-the-art visual quality, identity fidelity, and motion and expression consistency across diverse in-the-wild video scenes. We will release the source code and the HeadSwapBench dataset to facilitate future research.
UniSER: A Foundation Model for Unified Soft Effects Removal
Nov 18, 2025Digital images are often degraded by soft effects such as lens flare, haze, shadows, and reflections, which reduce aesthetics even though the underlying pixels remain partially visible. The prevailing works address these degradations in isolation, developing highly specialized, specialist models that lack scalability and fail to exploit the shared underlying essences of these restoration problems. While specialist models are limited, recent large-scale pretrained generalist models offer powerful, text-driven image editing capabilities. while recent general-purpose systems (e.g., GPT-4o, Flux Kontext, Nano Banana) require detailed prompts and often fail to achieve robust removal on these fine-grained tasks or preserve identity of the scene. Leveraging the common essence of soft effects, i.e., semi-transparent occlusions, we introduce a foundational versatile model UniSER, capable of addressing diverse degradations caused by soft effects within a single framework. Our methodology centers on curating a massive 3.8M-pair dataset to ensure robustness and generalization, which includes novel, physically-plausible data to fill critical gaps in public benchmarks, and a tailored training pipeline that fine-tunes a Diffusion Transformer to learn robust restoration priors from this diverse data, integrating fine-grained mask and strength controls. This synergistic approach allows UniSER to significantly outperform both specialist and generalist models, achieving robust, high-fidelity restoration in the wild.
FIA-Edit: Frequency-Interactive Attention for Efficient and High-Fidelity Inversion-Free Text-Guided Image Editing
Nov 15, 2025Text-guided image editing has advanced rapidly with the rise of diffusion models. While flow-based inversion-free methods offer high efficiency by avoiding latent inversion, they often fail to effectively integrate source information, leading to poor background preservation, spatial inconsistencies, and over-editing due to the lack of effective integration of source information. In this paper, we present FIA-Edit, a novel inversion-free framework that achieves high-fidelity and semantically precise edits through a Frequency-Interactive Attention. Specifically, we design two key components: (1) a Frequency Representation Interaction (FRI) module that enhances cross-domain alignment by exchanging frequency components between source and target features within self-attention, and (2) a Feature Injection (FIJ) module that explicitly incorporates source-side queries, keys, values, and text embeddings into the target branch's cross-attention to preserve structure and semantics. Comprehensive and extensive experiments demonstrate that FIA-Edit supports high-fidelity editing at low computational cost (~6s per 512 * 512 image on an RTX 4090) and consistently outperforms existing methods across diverse tasks in visual quality, background fidelity, and controllability. Furthermore, we are the first to extend text-guided image editing to clinical applications. By synthesizing anatomically coherent hemorrhage variations in surgical images, FIA-Edit opens new opportunities for medical data augmentation and delivers significant gains in downstream bleeding classification. Our project is available at: https://github.com/kk42yy/FIA-Edit.
Retrieval-Augmented Generation in Medicine: A Scoping Review of Technical Implementations, Clinical Applications, and Ethical Considerations
Nov 13, 2025The rapid growth of medical knowledge and increasing complexity of clinical practice pose challenges. In this context, large language models (LLMs) have demonstrated value; however, inherent limitations remain. Retrieval-augmented generation (RAG) technologies show potential to enhance their clinical applicability. This study reviewed RAG applications in medicine. We found that research primarily relied on publicly available data, with limited application in private data. For retrieval, approaches commonly relied on English-centric embedding models, while LLMs were mostly generic, with limited use of medical-specific LLMs. For evaluation, automated metrics evaluated generation quality and task performance, whereas human evaluation focused on accuracy, completeness, relevance, and fluency, with insufficient attention to bias and safety. RAG applications were concentrated on question answering, report generation, text summarization, and information extraction. Overall, medical RAG remains at an early stage, requiring advances in clinical validation, cross-linguistic adaptation, and support for low-resource settings to enable trustworthy and responsible global use.