 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamActor-M2: Universal Character Image Animation via Spatiotemporal In-Context Learning
Jan 29, 2026Character image animation aims to synthesize high-fidelity videos by transferring motion from a driving sequence to a static reference image. Despite recent advancements, existing methods suffer from two fundamental challenges: (1) suboptimal motion injection strategies that lead to a trade-off between identity preservation and motion consistency, manifesting as a "see-saw", and (2) an over-reliance on explicit pose priors (e.g., skeletons), which inadequately capture intricate dynamics and hinder generalization to arbitrary, non-humanoid characters. To address these challenges, we present DreamActor-M2, a universal animation framework that reimagines motion conditioning as an in-context learning problem. Our approach follows a two-stage paradigm. First, we bridge the input modality gap by fusing reference appearance and motion cues into a unified latent space, enabling the model to jointly reason about spatial identity and temporal dynamics by leveraging the generative prior of foundational models. Second, we introduce a self-bootstrapped data synthesis pipeline that curates pseudo cross-identity training pairs, facilitating a seamless transition from pose-dependent control to direct, end-to-end RGB-driven animation. This strategy significantly enhances generalization across diverse characters and motion scenarios. To facilitate comprehensive evaluation, we further introduce AW Bench, a versatile benchmark encompassing a wide spectrum of characters types and motion scenarios. Extensive experiments demonstrate that DreamActor-M2 achieves state-of-the-art performance, delivering superior visual fidelity and robust cross-domain generalization. Project Page: https://grisoon.github.io/DreamActor-M2/
Beyond Patches: Global-aware Autoregressive Model for Multimodal Few-Shot Font Generation
Jan 04, 2026Manual font design is an intricate process that transforms a stylistic visual concept into a coherent glyph set. This challenge persists in automated Few-shot Font Generation (FFG), where models often struggle to preserve both the structural integrity and stylistic fidelity from limited references. While autoregressive (AR) models have demonstrated impressive generative capabilities, their application to FFG is constrained by conventional patch-level tokenization, which neglects global dependencies crucial for coherent font synthesis. Moreover, existing FFG methods remain within the image-to-image paradigm, relying solely on visual references and overlooking the role of language in conveying stylistic intent during font design. To address these limitations, we propose GAR-Font, a novel AR framework for multimodal few-shot font generation. GAR-Font introduces a global-aware tokenizer that effectively captures both local structures and global stylistic patterns, a multimodal style encoder offering flexible style control through a lightweight language-style adapter without requiring intensive multimodal pretraining, and a post-refinement pipeline that further enhances structural fidelity and style coherence. Extensive experiments show that GAR-Font outperforms existing FFG methods, excelling in maintaining global style faithfulness and achieving higher-quality results with textual stylistic guidance.
UTDesign: A Unified Framework for Stylized Text Editing and Generation in Graphic Design Images
Dec 23, 2025AI-assisted graphic design has emerged as a powerful tool for automating the creation and editing of design elements such as posters, banners, and advertisements. While diffusion-based text-to-image models have demonstrated strong capabilities in visual content generation, their text rendering performance, particularly for small-scale typography and non-Latin scripts, remains limited. In this paper, we propose UTDesign, a unified framework for high-precision stylized text editing and conditional text generation in design images, supporting both English and Chinese scripts. Our framework introduces a novel DiT-based text style transfer model trained from scratch on a synthetic dataset, capable of generating transparent RGBA text foregrounds that preserve the style of reference glyphs. We further extend this model into a conditional text generation framework by training a multi-modal condition encoder on a curated dataset with detailed text annotations, enabling accurate, style-consistent text synthesis conditioned on background images, prompts, and layout specifications. Finally, we integrate our approach into a fully automated text-to-design (T2D) pipeline by incorporating pre-trained text-to-image (T2I) models and an MLLM-based layout planner. Extensive experiments demonstrate that UTDesign achieves state-of-the-art performance among open-source methods in terms of stylistic consistency and text accuracy, and also exhibits unique advantages compared to proprietary commercial approaches. Code and data for this paper are available at https://github.com/ZYM-PKU/UTDesign.
FIA-Edit: Frequency-Interactive Attention for Efficient and High-Fidelity Inversion-Free Text-Guided Image Editing
Nov 15, 2025Text-guided image editing has advanced rapidly with the rise of diffusion models. While flow-based inversion-free methods offer high efficiency by avoiding latent inversion, they often fail to effectively integrate source information, leading to poor background preservation, spatial inconsistencies, and over-editing due to the lack of effective integration of source information. In this paper, we present FIA-Edit, a novel inversion-free framework that achieves high-fidelity and semantically precise edits through a Frequency-Interactive Attention. Specifically, we design two key components: (1) a Frequency Representation Interaction (FRI) module that enhances cross-domain alignment by exchanging frequency components between source and target features within self-attention, and (2) a Feature Injection (FIJ) module that explicitly incorporates source-side queries, keys, values, and text embeddings into the target branch's cross-attention to preserve structure and semantics. Comprehensive and extensive experiments demonstrate that FIA-Edit supports high-fidelity editing at low computational cost (~6s per 512 * 512 image on an RTX 4090) and consistently outperforms existing methods across diverse tasks in visual quality, background fidelity, and controllability. Furthermore, we are the first to extend text-guided image editing to clinical applications. By synthesizing anatomically coherent hemorrhage variations in surgical images, FIA-Edit opens new opportunities for medical data augmentation and delivers significant gains in downstream bleeding classification. Our project is available at: https://github.com/kk42yy/FIA-Edit.
MMMG: A Massive, Multidisciplinary, Multi-Tier Generation Benchmark for Text-to-Image Reasoning
Jun 12, 2025In this paper, we introduce knowledge image generation as a new task, alongside the Massive Multi-Discipline Multi-Tier Knowledge-Image Generation Benchmark (MMMG) to probe the reasoning capability of image generation models. Knowledge images have been central to human civilization and to the mechanisms of human learning--a fact underscored by dual-coding theory and the picture-superiority effect. Generating such images is challenging, demanding multimodal reasoning that fuses world knowledge with pixel-level grounding into clear explanatory visuals. To enable comprehensive evaluation, MMMG offers 4,456 expert-validated (knowledge) image-prompt pairs spanning 10 disciplines, 6 educational levels, and diverse knowledge formats such as charts, diagrams, and mind maps. To eliminate confounding complexity during evaluation, we adopt a unified Knowledge Graph (KG) representation. Each KG explicitly delineates a target image's core entities and their dependencies. We further introduce MMMG-Score to evaluate generated knowledge images. This metric combines factual fidelity, measured by graph-edit distance between KGs, with visual clarity assessment. Comprehensive evaluations of 16 state-of-the-art text-to-image generation models expose serious reasoning deficits--low entity fidelity, weak relations, and clutter--with GPT-4o achieving an MMMG-Score of only 50.20, underscoring the benchmark's difficulty. To spur further progress, we release FLUX-Reason (MMMG-Score of 34.45), an effective and open baseline that combines a reasoning LLM with diffusion models and is trained on 16,000 curated knowledge image-prompt pairs.
DreamActor-M1: Holistic, Expressive and Robust Human Image Animation with Hybrid Guidance
Apr 03, 2025While recent image-based human animation methods achieve realistic body and facial motion synthesis, critical gaps remain in fine-grained holistic controllability, multi-scale adaptability, and long-term temporal coherence, which leads to their lower expressiveness and robustness. We propose a diffusion transformer (DiT) based framework, DreamActor-M1, with hybrid guidance to overcome these limitations. For motion guidance, our hybrid control signals that integrate implicit facial representations, 3D head spheres, and 3D body skeletons achieve robust control of facial expressions and body movements, while producing expressive and identity-preserving animations. For scale adaptation, to handle various body poses and image scales ranging from portraits to full-body views, we employ a progressive training strategy using data with varying resolutions and scales. For appearance guidance, we integrate motion patterns from sequential frames with complementary visual references, ensuring long-term temporal coherence for unseen regions during complex movements. Experiments demonstrate that our method outperforms the state-of-the-art works, delivering expressive results for portraits, upper-body, and full-body generation with robust long-term consistency. Project Page: https://grisoon.github.io/DreamActor-M1/.
CalliReader: Contextualizing Chinese Calligraphy via an Embedding-Aligned Vision-Language Model
Mar 09, 2025
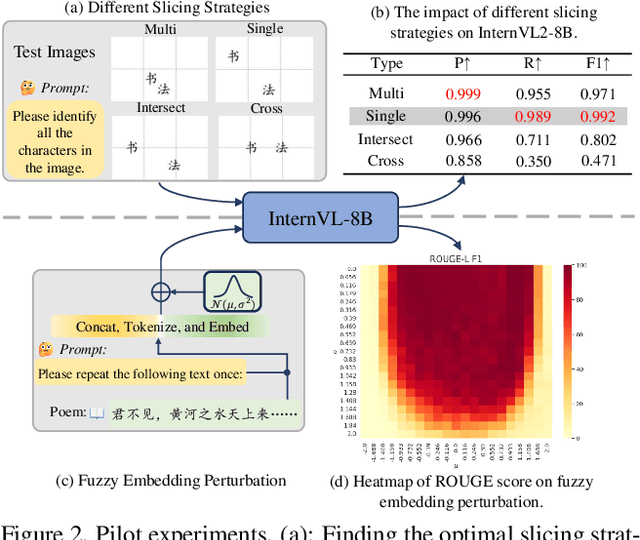
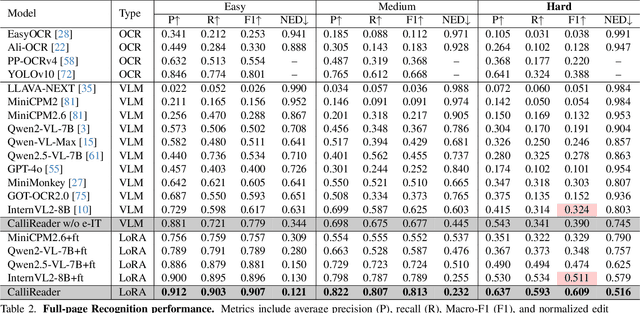
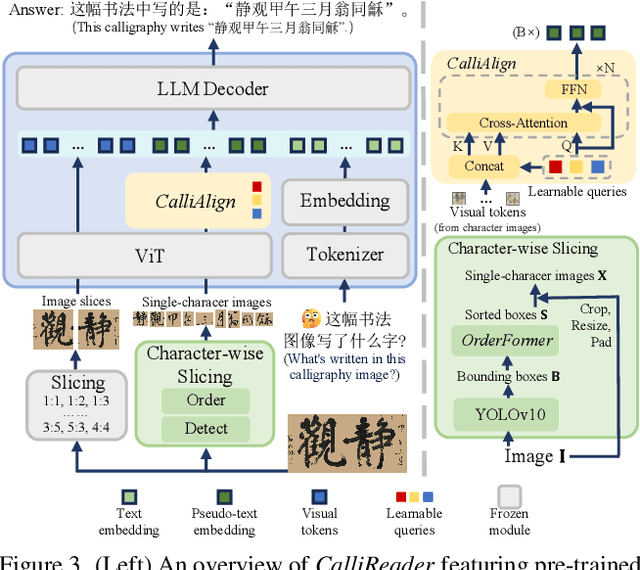
Chinese calligraphy, a UNESCO Heritage, remains computationally challenging due to visual ambiguity and cultural complexity. Existing AI systems fail to contextualize their intricate scripts, because of limited annotated data and poor visual-semantic alignment. We propose CalliReader, a vision-language model (VLM) that solves the Chinese Calligraphy Contextualization (CC$^2$) problem through three innovations: (1) character-wise slicing for precise character extraction and sorting, (2) CalliAlign for visual-text token compression and alignment, (3) embedding instruction tuning (e-IT) for improving alignment and addressing data scarcity. We also build CalliBench, the first benchmark for full-page calligraphic contextualization, addressing three critical issues in previous OCR and VQA approaches: fragmented context, shallow reasoning, and hallucination. Extensive experiments including user studies have been conducted to verify our CalliReader's \textbf{superiority to other state-of-the-art methods and even human professionals in page-level calligraphy recognition and interpretation}, achieving higher accuracy while reducing hallucination. Comparisons with reasoning models highlight the importance of accurate recognition as a prerequisite for reliable comprehension. Quantitative analyses validate CalliReader's efficiency; evaluations on document and real-world benchmarks confirm its robust generalization ability.
DreamFit: Garment-Centric Human Generation via a Lightweight Anything-Dressing Encoder
Dec 23, 2024



Diffusion models for garment-centric human generation from text or image prompts have garnered emerging attention for their great application potential. However, existing methods often face a dilemma: lightweight approaches, such as adapters, are prone to generate inconsistent textures; while finetune-based methods involve high training costs and struggle to maintain the generalization capabilities of pretrained diffusion models, limiting their performance across diverse scenarios. To address these challenges, we propose DreamFit, which incorporates a lightweight Anything-Dressing Encoder specifically tailored for the garment-centric human generation. DreamFit has three key advantages: (1) \textbf{Lightweight training}: with the proposed adaptive attention and LoRA modules, DreamFit significantly minimizes the model complexity to 83.4M trainable parameters. (2)\textbf{Anything-Dressing}: Our model generalizes surprisingly well to a wide range of (non-)garments, creative styles, and prompt instructions, consistently delivering high-quality results across diverse scenarios. (3) \textbf{Plug-and-play}: DreamFit is engineered for smooth integration with any community control plugins for diffusion models, ensuring easy compatibility and minimizing adoption barriers. To further enhance generation quality, DreamFit leverages pretrained large multi-modal models (LMMs) to enrich the prompt with fine-grained garment descriptions, thereby reducing the prompt gap between training and inference. We conduct comprehensive experiments on both $768 \times 512$ high-resolution benchmarks and in-the-wild images. DreamFit surpasses all existing methods, highlighting its state-of-the-art capabilities of garment-centric human generation.
Strike a Balance in Continual Panoptic Segmentation
Jul 23, 2024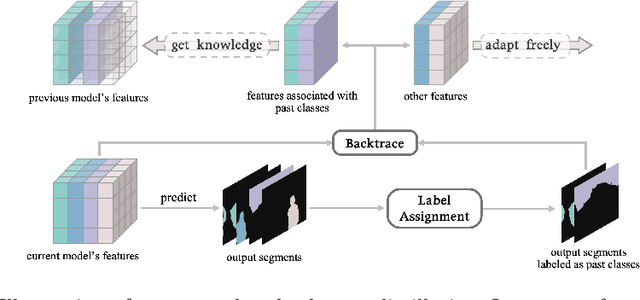
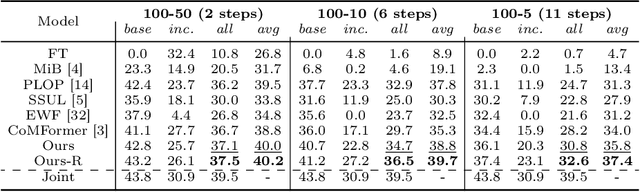
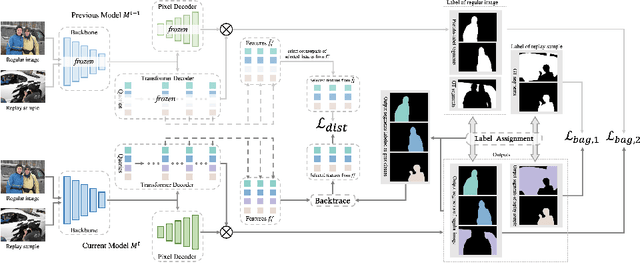
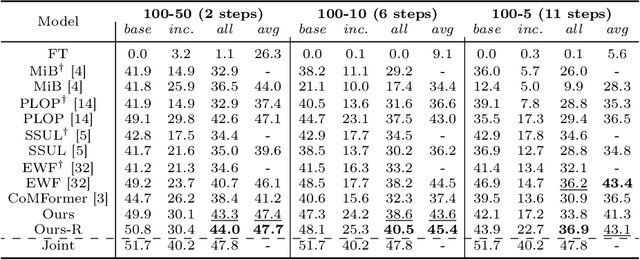
This study explores the emerging area of continual panoptic segmentation, highlighting three key balances. First, we introduce past-class backtrace distillation to balance the stability of existing knowledge with the adaptability to new information. This technique retraces the features associated with past classes based on the final label assignment results, performing knowledge distillation targeting these specific features from the previous model while allowing other features to flexibly adapt to new information. Additionally, we introduce a class-proportional memory strategy, which aligns the class distribution in the replay sample set with that of the historical training data. This strategy maintains a balanced class representation during replay, enhancing the utility of the limited-capacity replay sample set in recalling prior classes. Moreover, recognizing that replay samples are annotated only for the classes of their original step, we devise balanced anti-misguidance losses, which combat the impact of incomplete annotations without incurring classification bias. Building upon these innovations, we present a new method named Balanced Continual Panoptic Segmentation (BalConpas). Our evaluation on the challenging ADE20K dataset demonstrates its superior performance compared to existing state-of-the-art methods. The official code is available at https://github.com/jinpeng0528/BalConpas.
MMTryon: Multi-Modal Multi-Reference Control for High-Quality Fashion Generation
May 01, 2024



This paper introduces MMTryon, a multi-modal multi-reference VIrtual Try-ON (VITON) framework, which can generate high-quality compositional try-on results by taking as inputs a text instruction and multiple garment images. Our MMTryon mainly addresses two problems overlooked in prior literature: 1) Support of multiple try-on items and dressing styleExisting methods are commonly designed for single-item try-on tasks (e.g., upper/lower garments, dresses) and fall short on customizing dressing styles (e.g., zipped/unzipped, tuck-in/tuck-out, etc.) 2) Segmentation Dependency. They further heavily rely on category-specific segmentation models to identify the replacement regions, with segmentation errors directly leading to significant artifacts in the try-on results. For the first issue, our MMTryon introduces a novel multi-modality and multi-reference attention mechanism to combine the garment information from reference images and dressing-style information from text instructions. Besides, to remove the segmentation dependency, MMTryon uses a parsing-free garment encoder and leverages a novel scalable data generation pipeline to convert existing VITON datasets to a form that allows MMTryon to be trained without requiring any explicit segmentation. Extensive experiments on high-resolution benchmarks and in-the-wild test sets demonstrate MMTryon's superiority over existing SOTA methods both qualitatively and quantitatively. Besides, MMTryon's impressive performance on multi-items and style-controllable virtual try-on scenarios and its ability to try on any outfit in a large variety of scenarios from any source image, opens up a new avenue for future investigation in the fashion community.