 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing reasoning LLMs to extract SDOH events from clinical notes
Apr 15, 2026Social Determinants of Health (SDOH) refer to environmental, behavioral, and social conditions that influence how individuals live, work, and age. SDOH have a significant impact on personal health outcomes, and their systematic identification and management can yield substantial improvements in patient care. However, SDOH information is predominantly captured in unstructured clinical notes within electronic health records, which limits its direct use as machine-readable entities. To address this issue, researchers have employed Natural Language Processing (NLP) techniques using pre-trained BERT-based models, demonstrating promising performance but requiring sophisticated implementation and extensive computational resources. In this study, we investigated prompt engineering strategies for extracting structured SDOH events utilizing LLMs with advanced reasoning capabilities. Our method consisted of four modules: 1) developing concise and descriptive prompts integrated with established guidelines, 2) applying few-shot learning with carefully curated examples, 3) using a self-consistency mechanism to ensure robust outputs, and 4) post-processing for quality control. Our approach achieved a micro-F1 score of 0.866, demonstrating competitive performance compared to the leading models. The results demonstrated that LLMs with reasoning capabilities are effective solutions for SDOH event extraction, offering both implementation simplicity and strong performance.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Retrieval-Augmented Generation in Medicine: A Scoping Review of Technical Implementations, Clinical Applications, and Ethical Considerations
Nov 13, 2025The rapid growth of medical knowledge and increasing complexity of clinical practice pose challenges. In this context, large language models (LLMs) have demonstrated value; however, inherent limitations remain. Retrieval-augmented generation (RAG) technologies show potential to enhance their clinical applicability. This study reviewed RAG applications in medicine. We found that research primarily relied on publicly available data, with limited application in private data. For retrieval, approaches commonly relied on English-centric embedding models, while LLMs were mostly generic, with limited use of medical-specific LLMs. For evaluation, automated metrics evaluated generation quality and task performance, whereas human evaluation focused on accuracy, completeness, relevance, and fluency, with insufficient attention to bias and safety. RAG applications were concentrated on question answering, report generation, text summarization, and information extraction. Overall, medical RAG remains at an early stage, requiring advances in clinical validation, cross-linguistic adaptation, and support for low-resource settings to enable trustworthy and responsible global use.
The Evolving Landscape of Generative Large Language Models and Traditional Natural Language Processing in Medicine
May 15, 2025Natural language processing (NLP) has been traditionally applied to medicine, and generative large language models (LLMs) have become prominent recently. However, the differences between them across different medical tasks remain underexplored. We analyzed 19,123 studies, finding that generative LLMs demonstrate advantages in open-ended tasks, while traditional NLP dominates in information extraction and analysis tasks. As these technologies advance, ethical use of them is essential to ensure their potential in medical applications.
MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation
Mar 13, 2025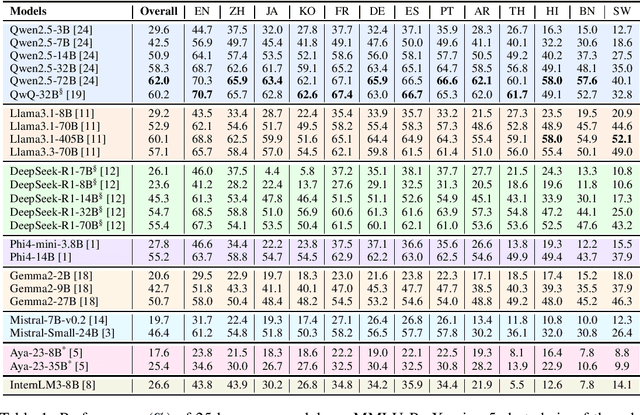
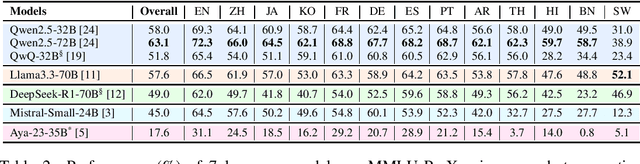
Traditional benchmarks struggle to evaluate increasingly sophisticated language models in multilingual and culturally diverse contexts. To address this gap, we introduce MMLU-ProX, a comprehensive multilingual benchmark covering 13 typologically diverse languages with approximately 11,829 questions per language. Building on the challenging reasoning-focused design of MMLU-Pro, our framework employs a semi-automatic translation process: translations generated by state-of-the-art large language models (LLMs) are rigorously evaluated by expert annotators to ensure conceptual accuracy, terminological consistency, and cultural relevance. We comprehensively evaluate 25 state-of-the-art LLMs using 5-shot chain-of-thought (CoT) and zero-shot prompting strategies, analyzing their performance across linguistic and cultural boundaries. Our experiments reveal consistent performance degradation from high-resource languages to lower-resource ones, with the best models achieving over 70% accuracy on English but dropping to around 40% for languages like Swahili, highlighting persistent gaps in multilingual capabilities despite recent advances. MMLU-ProX is an ongoing project; we are expanding our benchmark by incorporating additional languages and evaluating more language models to provide a more comprehensive assessment of multilingual capabilities.