 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Fast-Slow Vision-Language-Action Policies for Whole-Body Robotic Manipulation
Dec 23, 2025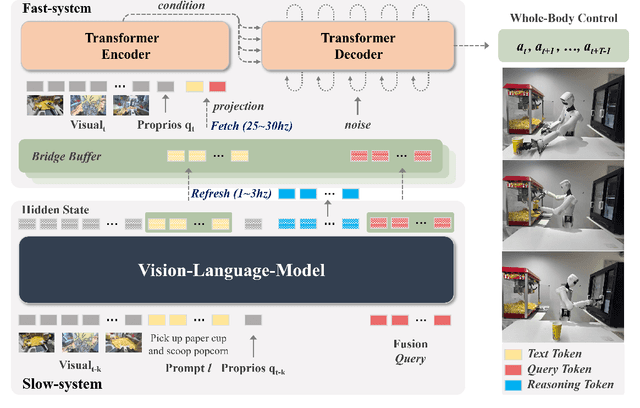

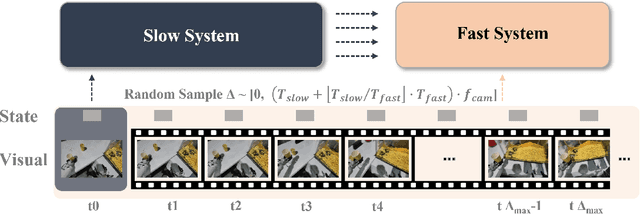

Most Vision-Language-Action (VLA) systems integrate a Vision-Language Model (VLM) for semantic reasoning with an action expert generating continuous action signals, yet both typically run at a single unified frequency. As a result, policy performance is constrained by the low inference speed of large VLMs. This mandatory synchronous execution severely limits control stability and real-time performance in whole-body robotic manipulation, which involves more joints, larger motion spaces, and dynamically changing views. We introduce a truly asynchronous Fast-Slow VLA framework (DuoCore-FS), organizing the system into a fast pathway for high-frequency action generation and a slow pathway for rich VLM reasoning. The system is characterized by two key features. First, a latent representation buffer bridges the slow and fast systems. It stores instruction semantics and action-reasoning representation aligned with the scene-instruction context, providing high-level guidance to the fast pathway. Second, a whole-body action tokenizer provides a compact, unified representation of whole-body actions. Importantly, the VLM and action expert are still jointly trained end-to-end, preserving unified policy learning while enabling asynchronous execution. DuoCore-FS supports a 3B-parameter VLM while achieving 30 Hz whole-body action-chunk generation, approximately three times as fast as prior VLA models with comparable model sizes. Real-world whole-body manipulation experiments demonstrate improved task success rates and significantly enhanced responsiveness compared to synchronous Fast-Slow VLA baselines. The implementation of DuoCore-FS, including training, inference, and deployment, is provided to commercial users by Astribot as part of the Astribot robotic platform.
AutoM3L: An Automated Multimodal Machine Learning Framework with Large Language Models
Aug 01, 2024Automated Machine Learning (AutoML) offers a promising approach to streamline the training of machine learning models. However, existing AutoML frameworks are often limited to unimodal scenarios and require extensive manual configuration. Recent advancements in Large Language Models (LLMs) have showcased their exceptional abilities in reasoning, interaction, and code generation, presenting an opportunity to develop a more automated and user-friendly framework. To this end, we introduce AutoM3L, an innovative Automated Multimodal Machine Learning framework that leverages LLMs as controllers to automatically construct multimodal training pipelines. AutoM3L comprehends data modalities and selects appropriate models based on user requirements, providing automation and interactivity. By eliminating the need for manual feature engineering and hyperparameter optimization, our framework simplifies user engagement and enables customization through directives, addressing the limitations of previous rule-based AutoML approaches. We evaluate the performance of AutoM3L on six diverse multimodal datasets spanning classification, regression, and retrieval tasks, as well as a comprehensive set of unimodal datasets. The results demonstrate that AutoM3L achieves competitive or superior performance compared to traditional rule-based AutoML methods. Furthermore, a user study highlights the user-friendliness and usability of our framework, compared to the rule-based AutoML methods.