 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHECTOR: Hybrid Editable Compositional Object References for Video Generation
Mar 09, 2026Real-world videos naturally portray complex interactions among distinct physical objects, effectively forming dynamic compositions of visual elements. However, most current video generation models synthesize scenes holistically and therefore lack mechanisms for explicit compositional manipulation. To address this limitation, we propose HECTOR, a generative pipeline that enables fine-grained compositional control. In contrast to prior methods,HECTOR supports hybrid reference conditioning, allowing generation to be simultaneously guided by static images and/or dynamic videos. Moreover, users can explicitly specify the trajectory of each referenced element, precisely controlling its location, scale, and speed (see Figure1). This design allows the model to synthesize coherent videos that satisfy complex spatiotemporal constraints while preserving high-fidelity adherence to references. Extensive experiments demonstrate that HECTOR achieves superior visual quality, stronger reference preservation, and improved motion controllability compared with existing approaches.
Asynchronous Fast-Slow Vision-Language-Action Policies for Whole-Body Robotic Manipulation
Dec 23, 2025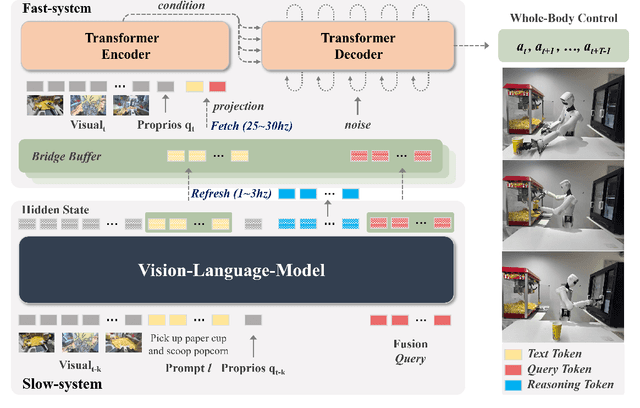

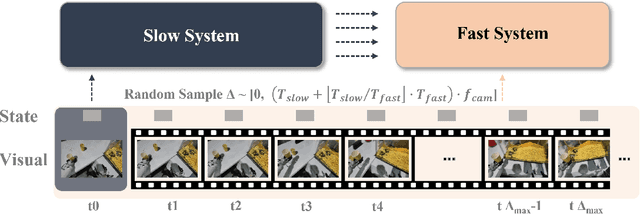

Most Vision-Language-Action (VLA) systems integrate a Vision-Language Model (VLM) for semantic reasoning with an action expert generating continuous action signals, yet both typically run at a single unified frequency. As a result, policy performance is constrained by the low inference speed of large VLMs. This mandatory synchronous execution severely limits control stability and real-time performance in whole-body robotic manipulation, which involves more joints, larger motion spaces, and dynamically changing views. We introduce a truly asynchronous Fast-Slow VLA framework (DuoCore-FS), organizing the system into a fast pathway for high-frequency action generation and a slow pathway for rich VLM reasoning. The system is characterized by two key features. First, a latent representation buffer bridges the slow and fast systems. It stores instruction semantics and action-reasoning representation aligned with the scene-instruction context, providing high-level guidance to the fast pathway. Second, a whole-body action tokenizer provides a compact, unified representation of whole-body actions. Importantly, the VLM and action expert are still jointly trained end-to-end, preserving unified policy learning while enabling asynchronous execution. DuoCore-FS supports a 3B-parameter VLM while achieving 30 Hz whole-body action-chunk generation, approximately three times as fast as prior VLA models with comparable model sizes. Real-world whole-body manipulation experiments demonstrate improved task success rates and significantly enhanced responsiveness compared to synchronous Fast-Slow VLA baselines. The implementation of DuoCore-FS, including training, inference, and deployment, is provided to commercial users by Astribot as part of the Astribot robotic platform.
VIVA: VLM-Guided Instruction-Based Video Editing with Reward Optimization
Dec 18, 2025



Instruction-based video editing aims to modify an input video according to a natural-language instruction while preserving content fidelity and temporal coherence. However, existing diffusion-based approaches are often trained on paired data of simple editing operations, which fundamentally limits their ability to generalize to diverse and complex, real-world instructions. To address this generalization gap, we propose VIVA, a scalable framework for instruction-based video editing that leverages VLM-guided encoding and reward optimization. First, we introduce a VLM-based instructor that encodes the textual instruction, the first frame of the source video, and an optional reference image into visually-grounded instruction representations, providing fine-grained spatial and semantic context for the diffusion transformer backbone. Second, we propose a post-training stage, Edit-GRPO, which adapts Group Relative Policy Optimization to the domain of video editing, directly optimizing the model for instruction-faithful, content-preserving, and aesthetically pleasing edits using relative rewards. Furthermore, we propose a data construction pipeline designed to synthetically generate diverse, high-fidelity paired video-instruction data of basic editing operations. Extensive experiments show that VIVA achieves superior instruction following, generalization, and editing quality over state-of-the-art methods. Website: https://viva-paper.github.io
Mind to Hand: Purposeful Robotic Control via Embodied Reasoning
Dec 10, 2025Humans act with context and intention, with reasoning playing a central role. While internet-scale data has enabled broad reasoning capabilities in AI systems, grounding these abilities in physical action remains a major challenge. We introduce Lumo-1, a generalist vision-language-action (VLA) model that unifies robot reasoning ("mind") with robot action ("hand"). Our approach builds upon the general multi-modal reasoning capabilities of pre-trained vision-language models (VLMs), progressively extending them to embodied reasoning and action prediction, and ultimately towards structured reasoning and reasoning-action alignment. This results in a three-stage pre-training pipeline: (1) Continued VLM pre-training on curated vision-language data to enhance embodied reasoning skills such as planning, spatial understanding, and trajectory prediction; (2) Co-training on cross-embodiment robot data alongside vision-language data; and (3) Action training with reasoning process on trajectories collected on Astribot S1, a bimanual mobile manipulator with human-like dexterity and agility. Finally, we integrate reinforcement learning to further refine reasoning-action consistency and close the loop between semantic inference and motor control. Extensive experiments demonstrate that Lumo-1 achieves significant performance improvements in embodied vision-language reasoning, a critical component for generalist robotic control. Real-world evaluations further show that Lumo-1 surpasses strong baselines across a wide range of challenging robotic tasks, with strong generalization to novel objects and environments, excelling particularly in long-horizon tasks and responding to human-natural instructions that require reasoning over strategy, concepts and space.
A Hybrid Force-Position Strategy for Shape Control of Deformable Linear Objects With Graph Attention Networks
Aug 10, 2025Manipulating deformable linear objects (DLOs) such as wires and cables is crucial in various applications like electronics assembly and medical surgeries. However, it faces challenges due to DLOs' infinite degrees of freedom, complex nonlinear dynamics, and the underactuated nature of the system. To address these issues, this paper proposes a hybrid force-position strategy for DLO shape control. The framework, combining both force and position representations of DLO, integrates state trajectory planning in the force space and Model Predictive Control (MPC) in the position space. We present a dynamics model with an explicit action encoder, a property extractor and a graph processor based on Graph Attention Networks. The model is used in the MPC to enhance prediction accuracy. Results from both simulations and real-world experiments demonstrate the effectiveness of our approach in achieving efficient and stable shape control of DLOs. Codes and videos are available at https://sites.google.com/view/dlom.
Imbalance in Balance: Online Concept Balancing in Generation Models
Jul 17, 2025In visual generation tasks, the responses and combinations of complex concepts often lack stability and are error-prone, which remains an under-explored area. In this paper, we attempt to explore the causal factors for poor concept responses through elaborately designed experiments. We also design a concept-wise equalization loss function (IMBA loss) to address this issue. Our proposed method is online, eliminating the need for offline dataset processing, and requires minimal code changes. In our newly proposed complex concept benchmark Inert-CompBench and two other public test sets, our method significantly enhances the concept response capability of baseline models and yields highly competitive results with only a few codes.
An Empirical Study of the Impact of Federated Learning on Machine Learning Model Accuracy
Mar 27, 2025



Federated Learning (FL) enables distributed ML model training on private user data at the global scale. Despite the potential of FL demonstrated in many domains, an in-depth view of its impact on model accuracy remains unclear. In this paper, we investigate, systematically, how this learning paradigm can affect the accuracy of state-of-the-art ML models for a variety of ML tasks. We present an empirical study that involves various data types: text, image, audio, and video, and FL configuration knobs: data distribution, FL scale, client sampling, and local and global computations. Our experiments are conducted in a unified FL framework to achieve high fidelity, with substantial human efforts and resource investments. Based on the results, we perform a quantitative analysis of the impact of FL, and highlight challenging scenarios where applying FL degrades the accuracy of the model drastically and identify cases where the impact is negligible. The detailed and extensive findings can benefit practical deployments and future development of FL.
DiffMoE: Dynamic Token Selection for Scalable Diffusion Transformers
Mar 18, 2025Diffusion models have demonstrated remarkable success in various image generation tasks, but their performance is often limited by the uniform processing of inputs across varying conditions and noise levels. To address this limitation, we propose a novel approach that leverages the inherent heterogeneity of the diffusion process. Our method, DiffMoE, introduces a batch-level global token pool that enables experts to access global token distributions during training, promoting specialized expert behavior. To unleash the full potential of the diffusion process, DiffMoE incorporates a capacity predictor that dynamically allocates computational resources based on noise levels and sample complexity. Through comprehensive evaluation, DiffMoE achieves state-of-the-art performance among diffusion models on ImageNet benchmark, substantially outperforming both dense architectures with 3x activated parameters and existing MoE approaches while maintaining 1x activated parameters. The effectiveness of our approach extends beyond class-conditional generation to more challenging tasks such as text-to-image generation, demonstrating its broad applicability across different diffusion model applications. Project Page: https://shiml20.github.io/DiffMoE/
Koala-36M: A Large-scale Video Dataset Improving Consistency between Fine-grained Conditions and Video Content
Oct 10, 2024As visual generation technologies continue to advance, the scale of video datasets has expanded rapidly, and the quality of these datasets is critical to the performance of video generation models. We argue that temporal splitting, detailed captions, and video quality filtering are three key factors that determine dataset quality. However, existing datasets exhibit various limitations in these areas. To address these challenges, we introduce Koala-36M, a large-scale, high-quality video dataset featuring accurate temporal splitting, detailed captions, and superior video quality. The core of our approach lies in improving the consistency between fine-grained conditions and video content. Specifically, we employ a linear classifier on probability distributions to enhance the accuracy of transition detection, ensuring better temporal consistency. We then provide structured captions for the splitted videos, with an average length of 200 words, to improve text-video alignment. Additionally, we develop a Video Training Suitability Score (VTSS) that integrates multiple sub-metrics, allowing us to filter high-quality videos from the original corpus. Finally, we incorporate several metrics into the training process of the generation model, further refining the fine-grained conditions. Our experiments demonstrate the effectiveness of our data processing pipeline and the quality of the proposed Koala-36M dataset. Our dataset and code will be released at https://koala36m.github.io/.
VideoTetris: Towards Compositional Text-to-Video Generation
Jun 06, 2024



Diffusion models have demonstrated great success in text-to-video (T2V) generation. However, existing methods may face challenges when handling complex (long) video generation scenarios that involve multiple objects or dynamic changes in object numbers. To address these limitations, we propose VideoTetris, a novel framework that enables compositional T2V generation. Specifically, we propose spatio-temporal compositional diffusion to precisely follow complex textual semantics by manipulating and composing the attention maps of denoising networks spatially and temporally. Moreover, we propose an enhanced video data preprocessing to enhance the training data regarding motion dynamics and prompt understanding, equipped with a new reference frame attention mechanism to improve the consistency of auto-regressive video generation. Extensive experiments demonstrate that our VideoTetris achieves impressive qualitative and quantitative results in compositional T2V generation. Code is available at: https://github.com/YangLing0818/VideoTetris