 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Fast-Slow Vision-Language-Action Policies for Whole-Body Robotic Manipulation
Dec 23, 2025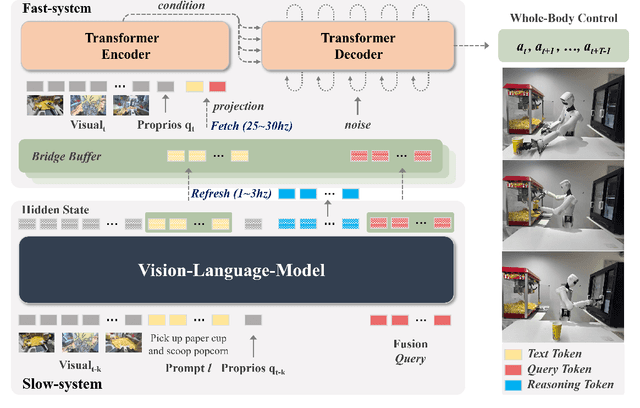

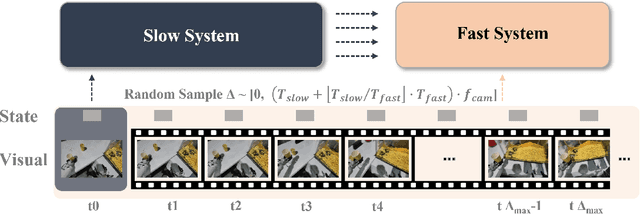

Most Vision-Language-Action (VLA) systems integrate a Vision-Language Model (VLM) for semantic reasoning with an action expert generating continuous action signals, yet both typically run at a single unified frequency. As a result, policy performance is constrained by the low inference speed of large VLMs. This mandatory synchronous execution severely limits control stability and real-time performance in whole-body robotic manipulation, which involves more joints, larger motion spaces, and dynamically changing views. We introduce a truly asynchronous Fast-Slow VLA framework (DuoCore-FS), organizing the system into a fast pathway for high-frequency action generation and a slow pathway for rich VLM reasoning. The system is characterized by two key features. First, a latent representation buffer bridges the slow and fast systems. It stores instruction semantics and action-reasoning representation aligned with the scene-instruction context, providing high-level guidance to the fast pathway. Second, a whole-body action tokenizer provides a compact, unified representation of whole-body actions. Importantly, the VLM and action expert are still jointly trained end-to-end, preserving unified policy learning while enabling asynchronous execution. DuoCore-FS supports a 3B-parameter VLM while achieving 30 Hz whole-body action-chunk generation, approximately three times as fast as prior VLA models with comparable model sizes. Real-world whole-body manipulation experiments demonstrate improved task success rates and significantly enhanced responsiveness compared to synchronous Fast-Slow VLA baselines. The implementation of DuoCore-FS, including training, inference, and deployment, is provided to commercial users by Astribot as part of the Astribot robotic platform.
FastUMI-100K: Advancing Data-driven Robotic Manipulation with a Large-scale UMI-style Dataset
Oct 09, 2025Data-driven robotic manipulation learning depends on large-scale, high-quality expert demonstration datasets. However, existing datasets, which primarily rely on human teleoperated robot collection, are limited in terms of scalability, trajectory smoothness, and applicability across different robotic embodiments in real-world environments. In this paper, we present FastUMI-100K, a large-scale UMI-style multimodal demonstration dataset, designed to overcome these limitations and meet the growing complexity of real-world manipulation tasks. Collected by FastUMI, a novel robotic system featuring a modular, hardware-decoupled mechanical design and an integrated lightweight tracking system, FastUMI-100K offers a more scalable, flexible, and adaptable solution to fulfill the diverse requirements of real-world robot demonstration data. Specifically, FastUMI-100K contains over 100K+ demonstration trajectories collected across representative household environments, covering 54 tasks and hundreds of object types. Our dataset integrates multimodal streams, including end-effector states, multi-view wrist-mounted fisheye images and textual annotations. Each trajectory has a length ranging from 120 to 500 frames. Experimental results demonstrate that FastUMI-100K enables high policy success rates across various baseline algorithms, confirming its robustness, adaptability, and real-world applicability for solving complex, dynamic manipulation challenges. The source code and dataset will be released in this link https://github.com/MrKeee/FastUMI-100K.
MoMa-Kitchen: A 100K+ Benchmark for Affordance-Grounded Last-Mile Navigation in Mobile Manipulation
Mar 14, 2025In mobile manipulation, navigation and manipulation are often treated as separate problems, resulting in a significant gap between merely approaching an object and engaging with it effectively. Many navigation approaches primarily define success by proximity to the target, often overlooking the necessity for optimal positioning that facilitates subsequent manipulation. To address this, we introduce MoMa-Kitchen, a benchmark dataset comprising over 100k samples that provide training data for models to learn optimal final navigation positions for seamless transition to manipulation. Our dataset includes affordance-grounded floor labels collected from diverse kitchen environments, in which robotic mobile manipulators of different models attempt to grasp target objects amidst clutter. Using a fully automated pipeline, we simulate diverse real-world scenarios and generate affordance labels for optimal manipulation positions. Visual data are collected from RGB-D inputs captured by a first-person view camera mounted on the robotic arm, ensuring consistency in viewpoint during data collection. We also develop a lightweight baseline model, NavAff, for navigation affordance grounding that demonstrates promising performance on the MoMa-Kitchen benchmark. Our approach enables models to learn affordance-based final positioning that accommodates different arm types and platform heights, thereby paving the way for more robust and generalizable integration of navigation and manipulation in embodied AI. Project page: \href{https://momakitchen.github.io/}{https://momakitchen.github.io/}.