 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmanic: Towards Step-wise Evaluation of Multi-hop Reasoning in Large Language Models
Mar 17, 2026Reasoning-focused large language models (LLMs) have advanced in many NLP tasks, yet their evaluation remains challenging: final answers alone do not expose the intermediate reasoning steps, making it difficult to determine whether a model truly reasons correctly and where failures occur, while existing multi-hop QA benchmarks lack step-level annotations for diagnosing reasoning failures. To address this gap, we propose Omanic, an open-domain multi-hop QA resource that provides decomposed sub-questions and intermediate answers as structural annotations for analyzing reasoning processes. It contains 10,296 machine-generated training examples (OmanicSynth) and 967 expert-reviewed human-annotated evaluation examples (OmanicBench). Systematic evaluations show that state-of-the-art LLMs achieve only 73.11% multiple-choice accuracy on OmanicBench, confirming its high difficulty. Stepwise analysis reveals that CoT's performance hinges on factual completeness, with its gains diminishing under knowledge gaps and errors amplifying in later hops. Additionally, supervised fine-tuning on OmanicSynth brings substantial transfer gains (7.41 average points) across six reasoning and math benchmarks, validating the dataset's quality and further supporting the effectiveness of OmanicSynth as supervision for reasoning-capability transfer. We release the data at https://huggingface.co/datasets/li-lab/Omanic and the code at https://github.com/XiaojieGu/Omanic.
From Chains to Graphs: Self-Structured Reasoning for General-Domain LLMs
Jan 07, 2026Large Language Models (LLMs) show strong reasoning ability in open-domain question answering, yet their reasoning processes are typically linear and often logically inconsistent. In contrast, real-world reasoning requires integrating multiple premises and solving subproblems in parallel. Existing methods, such as Chain-of-Thought (CoT), express reasoning in a linear textual form, which may appear coherent but frequently leads to inconsistent conclusions. Recent approaches rely on externally provided graphs and do not explore how LLMs can construct and use their own graph-structured reasoning, particularly in open-domain QA. To fill this gap, we novelly explore graph-structured reasoning of LLMs in general-domain question answering. We propose Self-Graph Reasoning (SGR), a framework that enables LLMs to explicitly represent their reasoning process as a structured graph before producing the final answer. We further construct a graph-structured reasoning dataset that merges multiple candidate reasoning graphs into refined graph structures for model training. Experiments on five QA benchmarks across both general and specialized domains show that SGR consistently improves reasoning consistency and yields a 17.74% gain over the base model. The LLaMA-3.3-70B model fine-tuned with SGR performs comparably to GPT-4o and surpasses Claude-3.5-Haiku, demonstrating the effectiveness of graph-structured reasoning.
Detecting AI-Generated Images via Distributional Deviations from Real Images
Jan 07, 2026The rapid advancement of generative models has significantly enhanced the quality of AI-generated images, raising concerns about misinformation and the erosion of public trust. Detecting AI-generated images has thus become a critical challenge, particularly in terms of generalizing to unseen generative models. Existing methods using frozen pre-trained CLIP models show promise in generalization but treat the image encoder as a basic feature extractor, failing to fully exploit its potential. In this paper, we perform an in-depth analysis of the frozen CLIP image encoder (CLIP-ViT), revealing that it effectively clusters real images in a high-level, abstract feature space. However, it does not truly possess the ability to distinguish between real and AI-generated images. Based on this analysis, we propose a Masking-based Pre-trained model Fine-Tuning (MPFT) strategy, which introduces a Texture-Aware Masking (TAM) mechanism to mask textured areas containing generative model-specific patterns during fine-tuning. This approach compels CLIP-ViT to attend to the "distributional deviations"from authentic images for AI-generated image detection, thereby achieving enhanced generalization performance. Extensive experiments on the GenImage and UniversalFakeDetect datasets demonstrate that our method, fine-tuned with only a minimal number of images, significantly outperforms existing approaches, achieving up to 98.2% and 94.6% average accuracy on the two datasets, respectively.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Retrieval-Augmented Generation in Medicine: A Scoping Review of Technical Implementations, Clinical Applications, and Ethical Considerations
Nov 13, 2025The rapid growth of medical knowledge and increasing complexity of clinical practice pose challenges. In this context, large language models (LLMs) have demonstrated value; however, inherent limitations remain. Retrieval-augmented generation (RAG) technologies show potential to enhance their clinical applicability. This study reviewed RAG applications in medicine. We found that research primarily relied on publicly available data, with limited application in private data. For retrieval, approaches commonly relied on English-centric embedding models, while LLMs were mostly generic, with limited use of medical-specific LLMs. For evaluation, automated metrics evaluated generation quality and task performance, whereas human evaluation focused on accuracy, completeness, relevance, and fluency, with insufficient attention to bias and safety. RAG applications were concentrated on question answering, report generation, text summarization, and information extraction. Overall, medical RAG remains at an early stage, requiring advances in clinical validation, cross-linguistic adaptation, and support for low-resource settings to enable trustworthy and responsible global use.
Exploring the Role of Knowledge Graph-Based RAG in Japanese Medical Question Answering with Small-Scale LLMs
Apr 16, 2025Large language models (LLMs) perform well in medical QA, but their effectiveness in Japanese contexts is limited due to privacy constraints that prevent the use of commercial models like GPT-4 in clinical settings. As a result, recent efforts focus on instruction-tuning open-source LLMs, though the potential of combining them with retrieval-augmented generation (RAG) remains underexplored. To bridge this gap, we are the first to explore a knowledge graph-based (KG) RAG framework for Japanese medical QA small-scale open-source LLMs. Experimental results show that KG-based RAG has only a limited impact on Japanese medical QA using small-scale open-source LLMs. Further case studies reveal that the effectiveness of the RAG is sensitive to the quality and relevance of the external retrieved content. These findings offer valuable insights into the challenges and potential of applying RAG in Japanese medical QA, while also serving as a reference for other low-resource languages.
MKG-Rank: Enhancing Large Language Models with Knowledge Graph for Multilingual Medical Question Answering
Mar 21, 2025Large Language Models (LLMs) have shown remarkable progress in medical question answering (QA), yet their effectiveness remains predominantly limited to English due to imbalanced multilingual training data and scarce medical resources for low-resource languages. To address this critical language gap in medical QA, we propose Multilingual Knowledge Graph-based Retrieval Ranking (MKG-Rank), a knowledge graph-enhanced framework that enables English-centric LLMs to perform multilingual medical QA. Through a word-level translation mechanism, our framework efficiently integrates comprehensive English-centric medical knowledge graphs into LLM reasoning at a low cost, mitigating cross-lingual semantic distortion and achieving precise medical QA across language barriers. To enhance efficiency, we introduce caching and multi-angle ranking strategies to optimize the retrieval process, significantly reducing response times and prioritizing relevant medical knowledge. Extensive evaluations on multilingual medical QA benchmarks across Chinese, Japanese, Korean, and Swahili demonstrate that MKG-Rank consistently outperforms zero-shot LLMs, achieving maximum 35.03% increase in accuracy, while maintaining an average retrieval time of only 0.0009 seconds.
ReAgent: Reversible Multi-Agent Reasoning for Knowledge-Enhanced Multi-Hop QA
Mar 10, 2025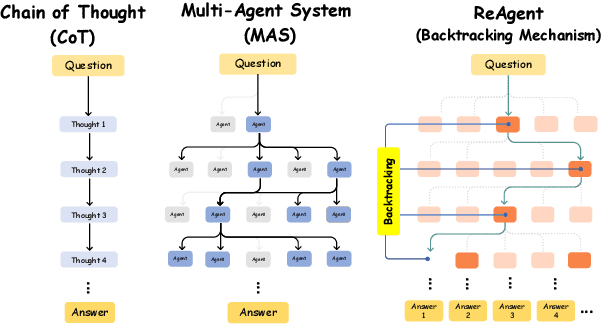
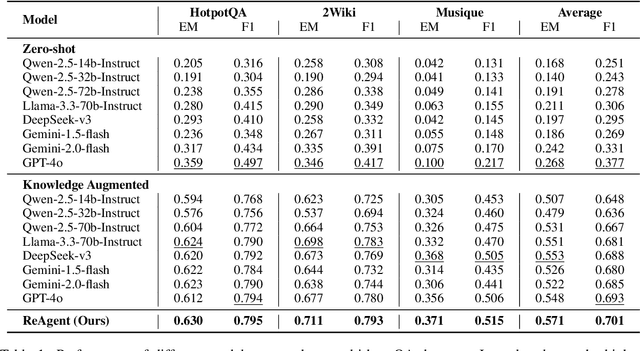
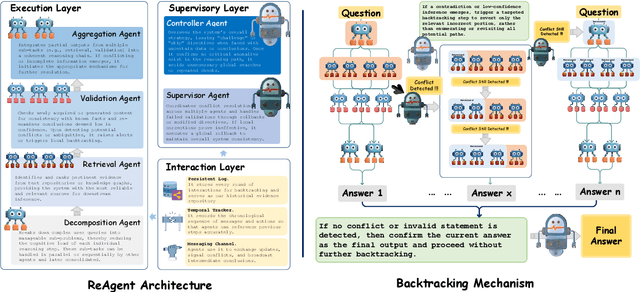
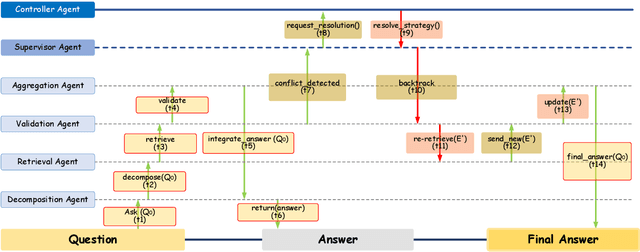
Recent advances in large language models (LLMs) have significantly improved multi-hop question answering (QA) through direct Chain-of-Thought (CoT) reasoning. However, the irreversible nature of CoT leads to error accumulation, making it challenging to correct mistakes in multi-hop reasoning. This paper introduces ReAgent: a Reversible multi-Agent collaborative framework augmented with explicit backtracking mechanisms, enabling reversible multi-hop reasoning. By incorporating text-based retrieval, information aggregation and validation, our system can detect and correct errors mid-reasoning, leading to more robust and interpretable QA outcomes. The framework and experiments serve as a foundation for future work on error-tolerant QA systems. Empirical evaluations across three benchmarks indicate ReAgent's efficacy, yielding average about 6\% improvements against baseline models.
GraphCheck: Breaking Long-Term Text Barriers with Extracted Knowledge Graph-Powered Fact-Checking
Feb 23, 2025Large language models (LLMs) are widely used, but they often generate subtle factual errors, especially in long-form text. These errors are fatal in some specialized domains such as medicine. Existing fact-checking with grounding documents methods face two main challenges: (1) they struggle to understand complex multihop relations in long documents, often overlooking subtle factual errors; (2) most specialized methods rely on pairwise comparisons, requiring multiple model calls, leading to high resource and computational costs. To address these challenges, we propose \textbf{\textit{GraphCheck}}, a fact-checking framework that uses extracted knowledge graphs to enhance text representation. Graph Neural Networks further process these graphs as a soft prompt, enabling LLMs to incorporate structured knowledge more effectively. Enhanced with graph-based reasoning, GraphCheck captures multihop reasoning chains which are often overlooked by existing methods, enabling precise and efficient fact-checking in a single inference call. Experimental results on seven benchmarks spanning both general and medical domains demonstrate a 6.1\% overall improvement over baseline models. Notably, GraphCheck outperforms existing specialized fact-checkers and achieves comparable performance with state-of-the-art LLMs, such as DeepSeek-V3 and OpenAI-o1, with significantly fewer parameters.
Learning on Less: Constraining Pre-trained Model Learning for Generalizable Diffusion-Generated Image Detection
Dec 01, 2024



Diffusion Models enable realistic image generation, raising the risk of misinformation and eroding public trust. Currently, detecting images generated by unseen diffusion models remains challenging due to the limited generalization capabilities of existing methods. To address this issue, we rethink the effectiveness of pre-trained models trained on large-scale, real-world images. Our findings indicate that: 1) Pre-trained models can cluster the features of real images effectively. 2) Models with pre-trained weights can approximate an optimal generalization solution at a specific training step, but it is extremely unstable. Based on these facts, we propose a simple yet effective training method called Learning on Less (LoL). LoL utilizes a random masking mechanism to constrain the model's learning of the unique patterns specific to a certain type of diffusion model, allowing it to focus on less image content. This leverages the inherent strengths of pre-trained weights while enabling a more stable approach to optimal generalization, which results in the extraction of a universal feature that differentiates various diffusion-generated images from real images. Extensive experiments on the GenImage benchmark demonstrate the remarkable generalization capability of our proposed LoL. With just 1% training data, LoL significantly outperforms the current state-of-the-art, achieving a 13.6% improvement in average ACC across images generated by eight different models.