 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation via the Target-aware Transformer
May 22, 2022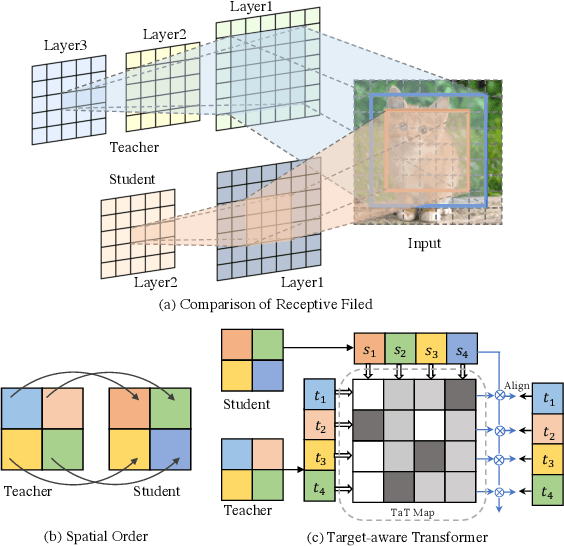
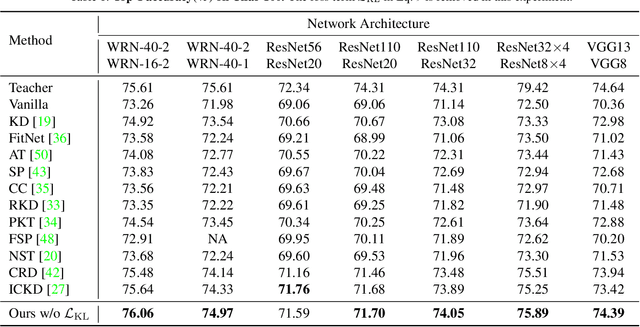
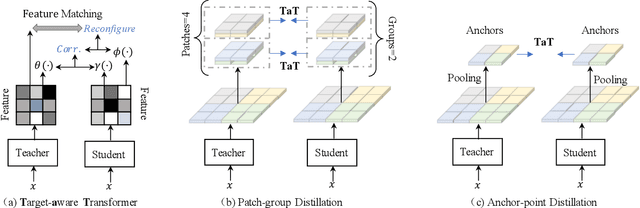

Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code will be released soon.
LogicSolver: Towards Interpretable Math Word Problem Solving with Logical Prompt-enhanced Learning
May 17, 2022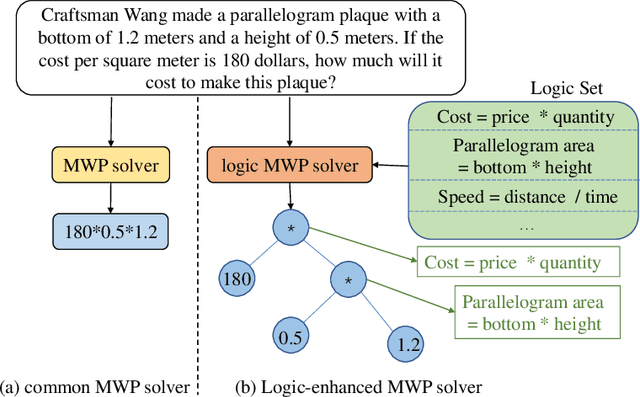
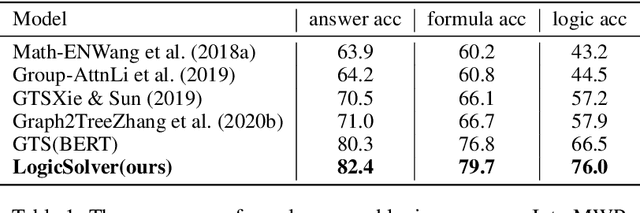

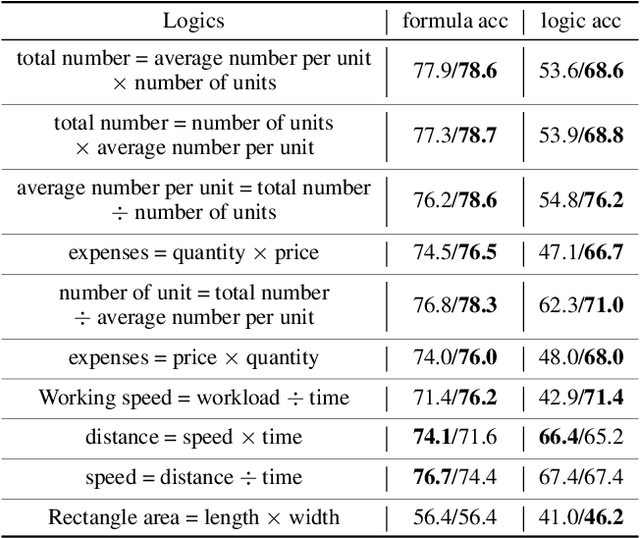
Recently, deep learning models have made great progress in MWP solving on answer accuracy. However, they are uninterpretable since they mainly rely on shallow heuristics to achieve high performance without understanding and reasoning the grounded math logic. To address this issue and make a step towards interpretable MWP solving, we first construct a high-quality MWP dataset named InterMWP which consists of 11,495 MWPs and annotates interpretable logical formulas based on algebraic knowledge as the grounded linguistic logic of each solution equation. Different from existing MWP datasets, our InterMWP benchmark asks for a solver to not only output the solution expressions but also predict the corresponding logical formulas. We further propose a novel approach with logical prompt and interpretation generation, called LogicSolver. For each MWP, our LogicSolver first retrieves some highly-correlated algebraic knowledge and then passes them to the backbone model as prompts to improve the semantic representations of MWPs. With these improved semantic representations, our LogicSolver generates corresponding solution expressions and interpretable knowledge formulas in accord with the generated solution expressions, simultaneously. Experimental results show that our LogicSolver has stronger logical formula-based interpretability than baselines while achieving higher answer accuracy with the help of logical prompts, simultaneously.
Unbiased Math Word Problems Benchmark for Mitigating Solving Bias
May 17, 2022
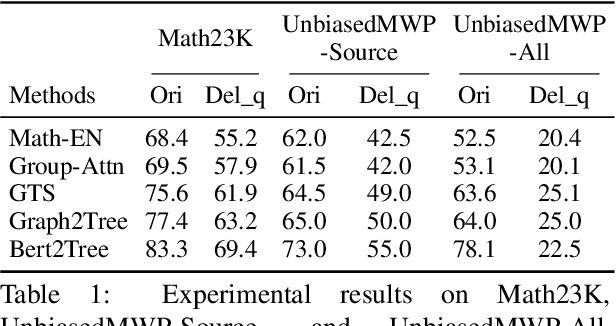
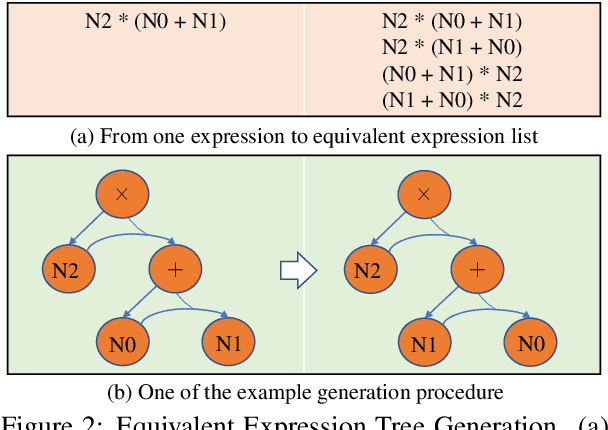

In this paper, we revisit the solving bias when evaluating models on current Math Word Problem (MWP) benchmarks. However, current solvers exist solving bias which consists of data bias and learning bias due to biased dataset and improper training strategy. Our experiments verify MWP solvers are easy to be biased by the biased training datasets which do not cover diverse questions for each problem narrative of all MWPs, thus a solver can only learn shallow heuristics rather than deep semantics for understanding problems. Besides, an MWP can be naturally solved by multiple equivalent equations while current datasets take only one of the equivalent equations as ground truth, forcing the model to match the labeled ground truth and ignoring other equivalent equations. Here, we first introduce a novel MWP dataset named UnbiasedMWP which is constructed by varying the grounded expressions in our collected data and annotating them with corresponding multiple new questions manually. Then, to further mitigate learning bias, we propose a Dynamic Target Selection (DTS) Strategy to dynamically select more suitable target expressions according to the longest prefix match between the current model output and candidate equivalent equations which are obtained by applying commutative law during training. The results show that our UnbiasedMWP has significantly fewer biases than its original data and other datasets, posing a promising benchmark for fairly evaluating the solvers' reasoning skills rather than matching nearest neighbors. And the solvers trained with our DTS achieve higher accuracies on multiple MWP benchmarks. The source code is available at https://github.com/yangzhch6/UnbiasedMWP.
Continual Object Detection via Prototypical Task Correlation Guided Gating Mechanism
May 06, 2022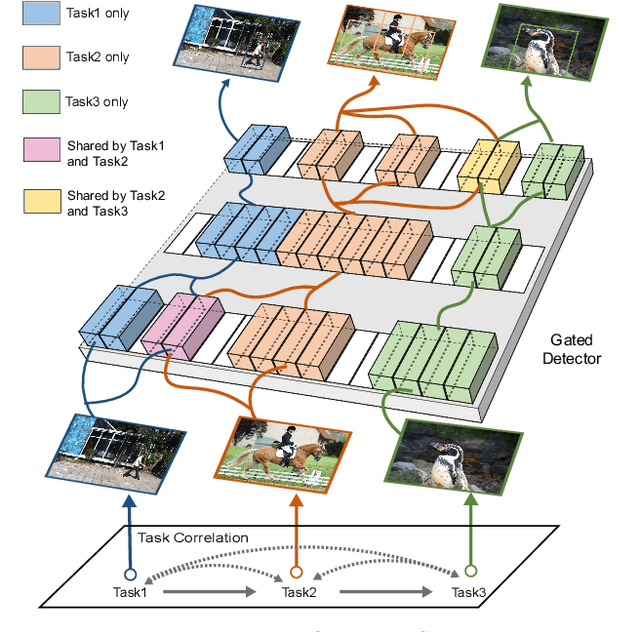
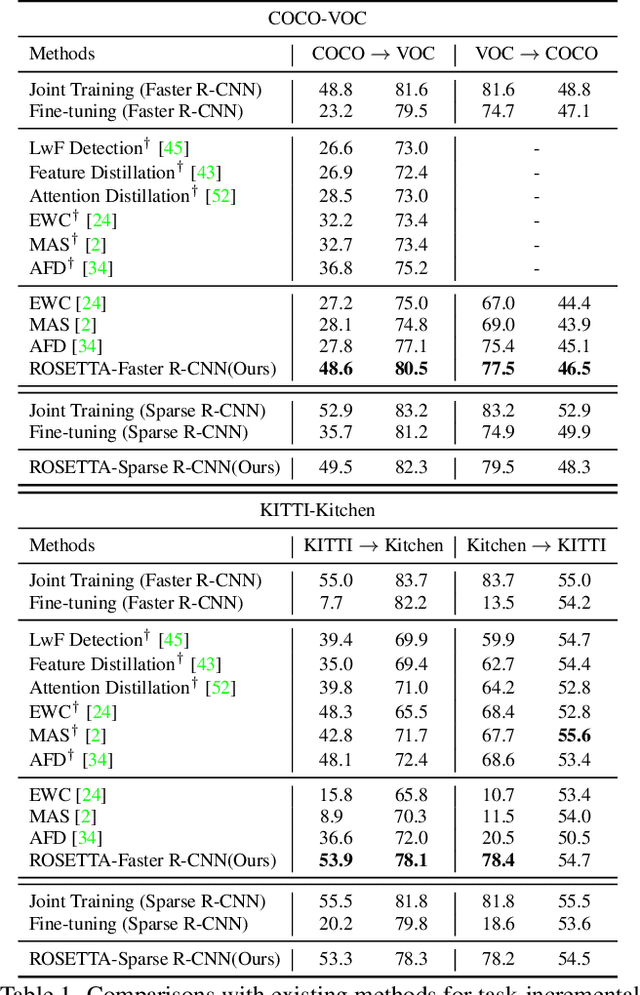
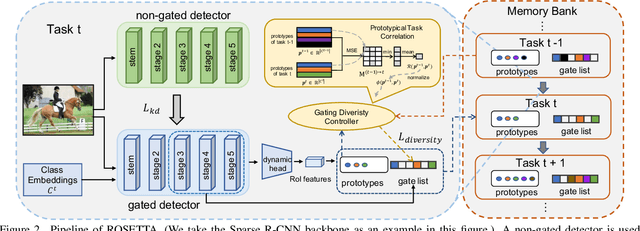
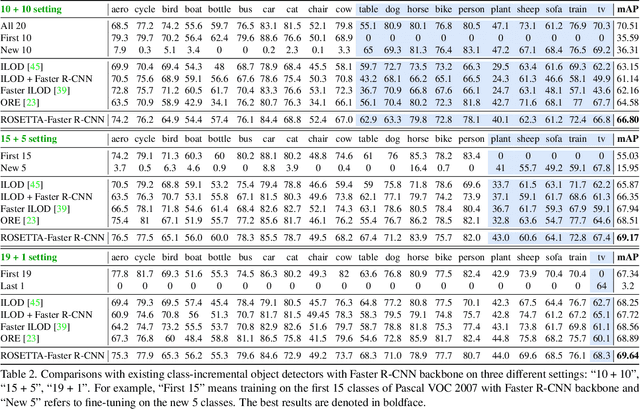
Continual learning is a challenging real-world problem for constructing a mature AI system when data are provided in a streaming fashion. Despite recent progress in continual classification, the researches of continual object detection are impeded by the diverse sizes and numbers of objects in each image. Different from previous works that tune the whole network for all tasks, in this work, we present a simple and flexible framework for continual object detection via pRotOtypical taSk corrElaTion guided gaTing mechAnism (ROSETTA). Concretely, a unified framework is shared by all tasks while task-aware gates are introduced to automatically select sub-models for specific tasks. In this way, various knowledge can be successively memorized by storing their corresponding sub-model weights in this system. To make ROSETTA automatically determine which experience is available and useful, a prototypical task correlation guided Gating Diversity Controller(GDC) is introduced to adaptively adjust the diversity of gates for the new task based on class-specific prototypes. GDC module computes class-to-class correlation matrix to depict the cross-task correlation, and hereby activates more exclusive gates for the new task if a significant domain gap is observed. Comprehensive experiments on COCO-VOC, KITTI-Kitchen, class-incremental detection on VOC and sequential learning of four tasks show that ROSETTA yields state-of-the-art performance on both task-based and class-based continual object detection.
"My nose is running.""Are you also coughing?": Building A Medical Diagnosis Agent with Interpretable Inquiry Logics
May 02, 2022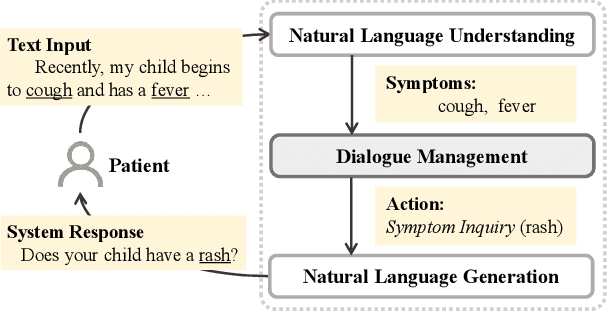
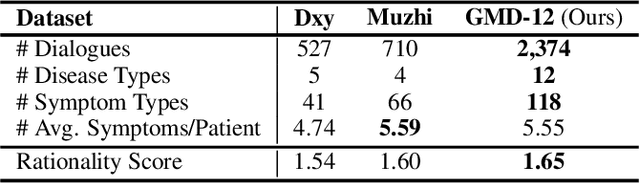
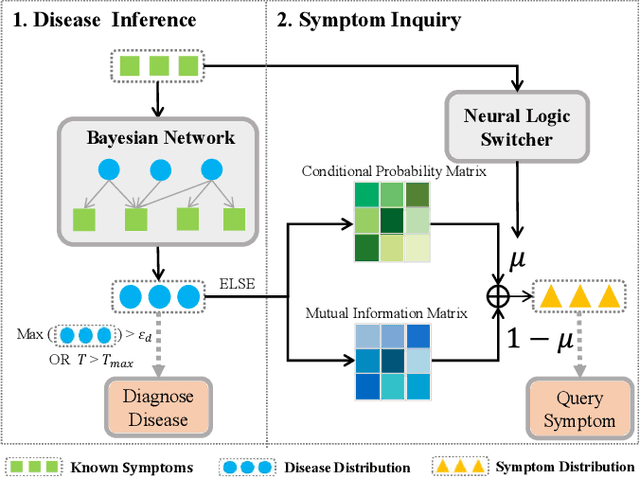
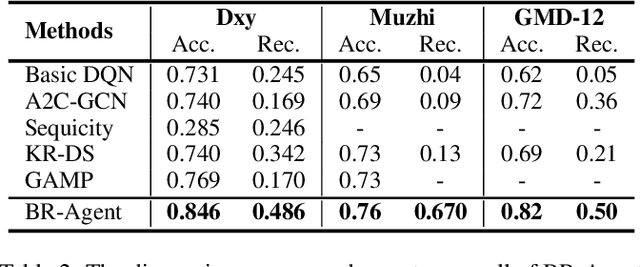
With the rise of telemedicine, the task of developing Dialogue Systems for Medical Diagnosis (DSMD) has received much attention in recent years. Different from early researches that needed to rely on extra human resources and expertise to help construct the system, recent researches focused on how to build DSMD in a purely data-driven manner. However, the previous data-driven DSMD methods largely overlooked the system interpretability, which is critical for a medical application, and they also suffered from the data sparsity issue at the same time. In this paper, we explore how to bring interpretability to data-driven DSMD. Specifically, we propose a more interpretable decision process to implement the dialogue manager of DSMD by reasonably mimicking real doctors' inquiry logics, and we devise a model with highly transparent components to conduct the inference. Moreover, we collect a new DSMD dataset, which has a much larger scale, more diverse patterns and is of higher quality than the existing ones. The experiments show that our method obtains 7.7%, 10.0%, 3.0% absolute improvement in diagnosis accuracy respectively on three datasets, demonstrating the effectiveness of its rational decision process and model design. Our codes and the GMD-12 dataset are available at https://github.com/lwgkzl/BR-Agent.
Arch-Graph: Acyclic Architecture Relation Predictor for Task-Transferable Neural Architecture Search
Apr 12, 2022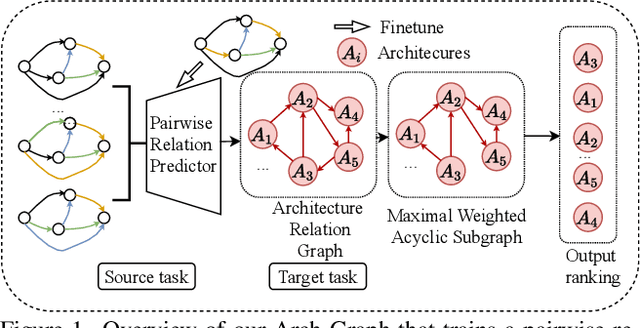
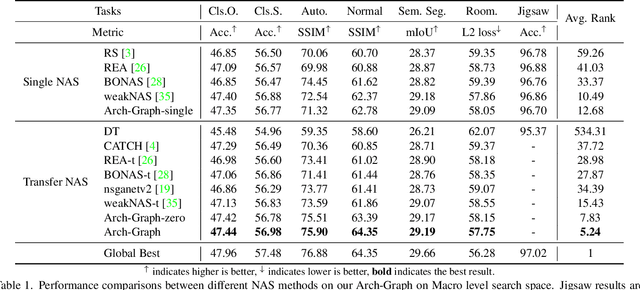
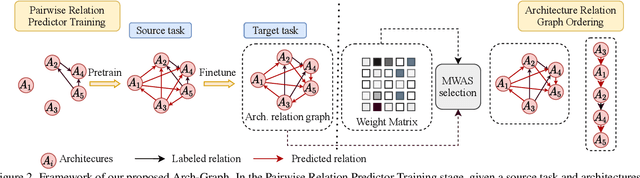
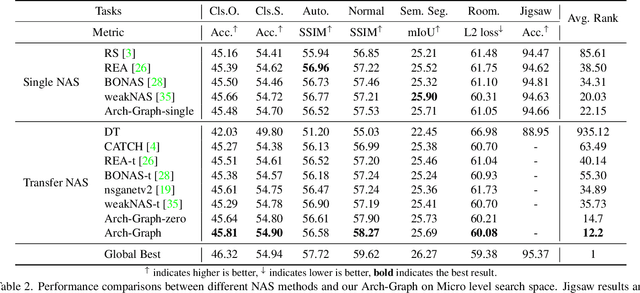
Neural Architecture Search (NAS) aims to find efficient models for multiple tasks. Beyond seeking solutions for a single task, there are surging interests in transferring network design knowledge across multiple tasks. In this line of research, effectively modeling task correlations is vital yet highly neglected. Therefore, we propose \textbf{Arch-Graph}, a transferable NAS method that predicts task-specific optimal architectures with respect to given task embeddings. It leverages correlations across multiple tasks by using their embeddings as a part of the predictor's input for fast adaptation. We also formulate NAS as an architecture relation graph prediction problem, with the relational graph constructed by treating candidate architectures as nodes and their pairwise relations as edges. To enforce some basic properties such as acyclicity in the relational graph, we add additional constraints to the optimization process, converting NAS into the problem of finding a Maximal Weighted Acyclic Subgraph (MWAS). Our algorithm then strives to eliminate cycles and only establish edges in the graph if the rank results can be trusted. Through MWAS, Arch-Graph can effectively rank candidate models for each task with only a small budget to finetune the predictor. With extensive experiments on TransNAS-Bench-101, we show Arch-Graph's transferability and high sample efficiency across numerous tasks, beating many NAS methods designed for both single-task and multi-task search. It is able to find top 0.16\% and 0.29\% architectures on average on two search spaces under the budget of only 50 models.
Beyond Fixation: Dynamic Window Visual Transformer
Apr 08, 2022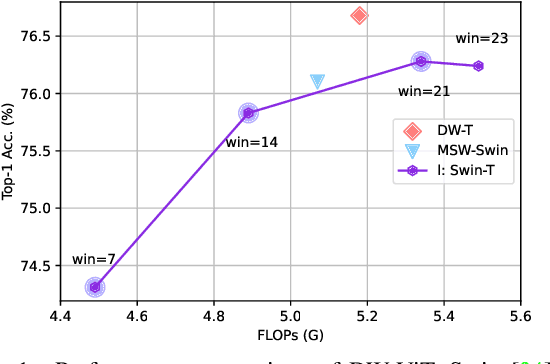
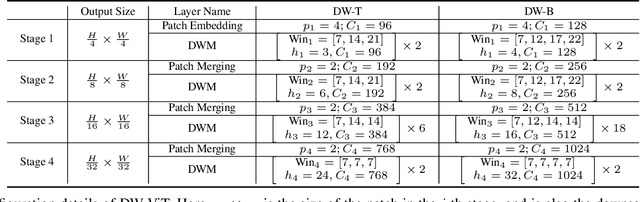
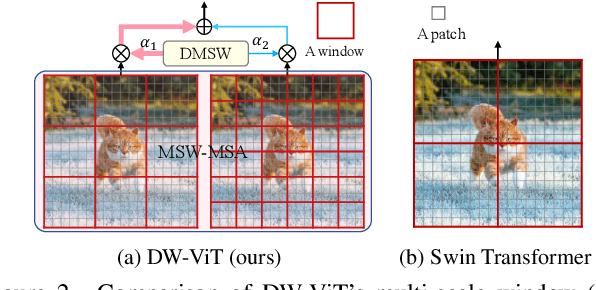
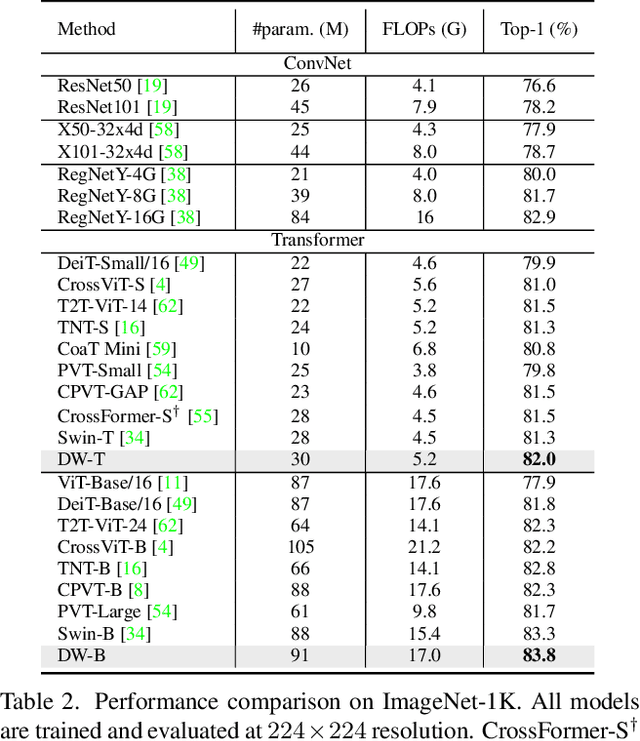
Recently, a surge of interest in visual transformers is to reduce the computational cost by limiting the calculation of self-attention to a local window. Most current work uses a fixed single-scale window for modeling by default, ignoring the impact of window size on model performance. However, this may limit the modeling potential of these window-based models for multi-scale information. In this paper, we propose a novel method, named Dynamic Window Vision Transformer (DW-ViT). The dynamic window strategy proposed by DW-ViT goes beyond the model that employs a fixed single window setting. To the best of our knowledge, we are the first to use dynamic multi-scale windows to explore the upper limit of the effect of window settings on model performance. In DW-ViT, multi-scale information is obtained by assigning windows of different sizes to different head groups of window multi-head self-attention. Then, the information is dynamically fused by assigning different weights to the multi-scale window branches. We conducted a detailed performance evaluation on three datasets, ImageNet-1K, ADE20K, and COCO. Compared with related state-of-the-art (SoTA) methods, DW-ViT obtains the best performance. Specifically, compared with the current SoTA Swin Transformers \cite{liu2021swin}, DW-ViT has achieved consistent and substantial improvements on all three datasets with similar parameters and computational costs. In addition, DW-ViT exhibits good scalability and can be easily inserted into any window-based visual transformers.
Dressing in the Wild by Watching Dance Videos
Mar 29, 2022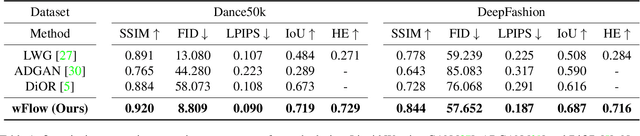
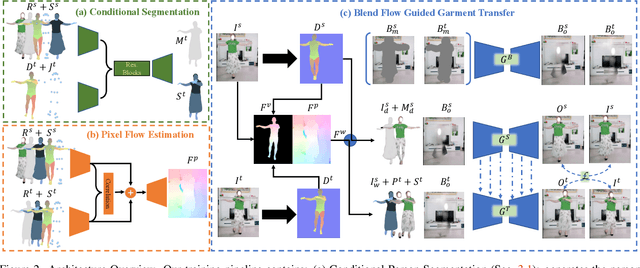
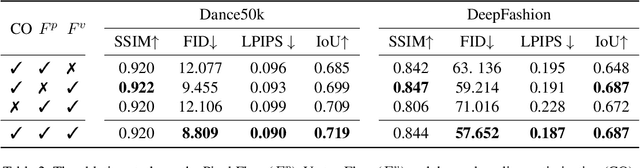
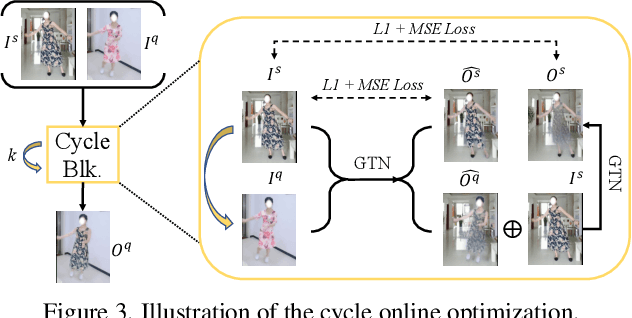
While significant progress has been made in garment transfer, one of the most applicable directions of human-centric image generation, existing works overlook the in-the-wild imagery, presenting severe garment-person misalignment as well as noticeable degradation in fine texture details. This paper, therefore, attends to virtual try-on in real-world scenes and brings essential improvements in authenticity and naturalness especially for loose garment (e.g., skirts, formal dresses), challenging poses (e.g., cross arms, bent legs), and cluttered backgrounds. Specifically, we find that the pixel flow excels at handling loose garments whereas the vertex flow is preferred for hard poses, and by combining their advantages we propose a novel generative network called wFlow that can effectively push up garment transfer to in-the-wild context. Moreover, former approaches require paired images for training. Instead, we cut down the laboriousness by working on a newly constructed large-scale video dataset named Dance50k with self-supervised cross-frame training and an online cycle optimization. The proposed Dance50k can boost real-world virtual dressing by covering a wide variety of garments under dancing poses. Extensive experiments demonstrate the superiority of our wFlow in generating realistic garment transfer results for in-the-wild images without resorting to expensive paired datasets.
Automated Progressive Learning for Efficient Training of Vision Transformers
Mar 28, 2022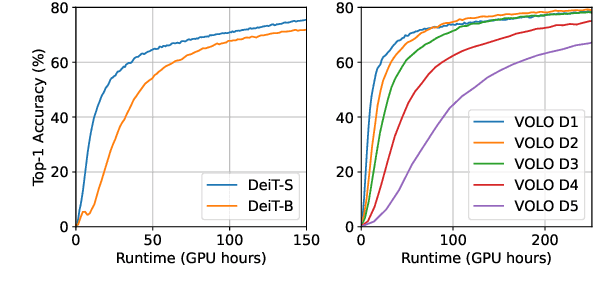
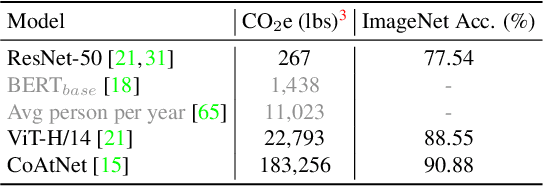
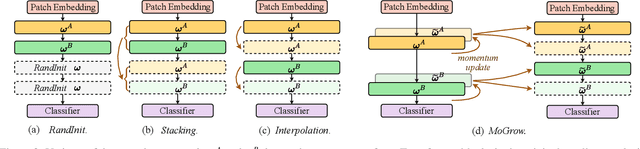
Recent advances in vision Transformers (ViTs) have come with a voracious appetite for computing power, high-lighting the urgent need to develop efficient training methods for ViTs. Progressive learning, a training scheme where the model capacity grows progressively during training, has started showing its ability in efficient training. In this paper, we take a practical step towards efficient training of ViTs by customizing and automating progressive learning. First, we develop a strong manual baseline for progressive learning of ViTs, by introducing momentum growth (MoGrow) to bridge the gap brought by model growth. Then, we propose automated progressive learning (AutoProg), an efficient training scheme that aims to achieve lossless acceleration by automatically increasing the training overload on-the-fly; this is achieved by adaptively deciding whether, where and how much should the model grow during progressive learning. Specifically, we first relax the optimization of the growth schedule to sub-network architecture optimization problem, then propose one-shot estimation of the sub-network performance via an elastic supernet. The searching overhead is reduced to minimal by recycling the parameters of the supernet. Extensive experiments of efficient training on ImageNet with two representative ViT models, DeiT and VOLO, demonstrate that AutoProg can accelerate ViTs training by up to 85.1% with no performance drop. Code: https://github.com/changlin31/AutoProg
Laneformer: Object-aware Row-Column Transformers for Lane Detection
Mar 18, 2022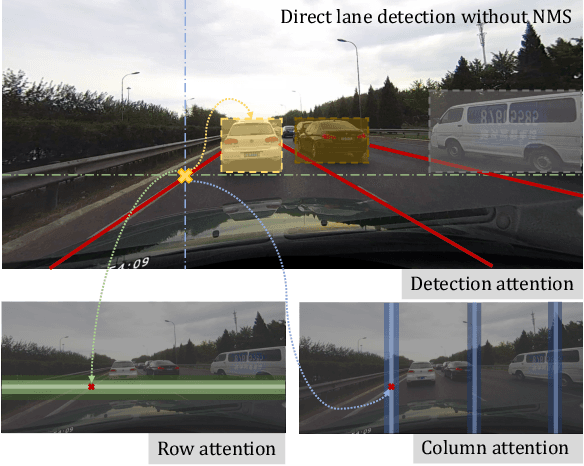
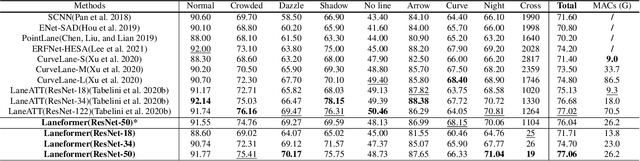
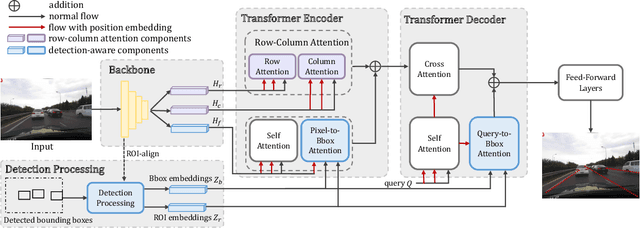
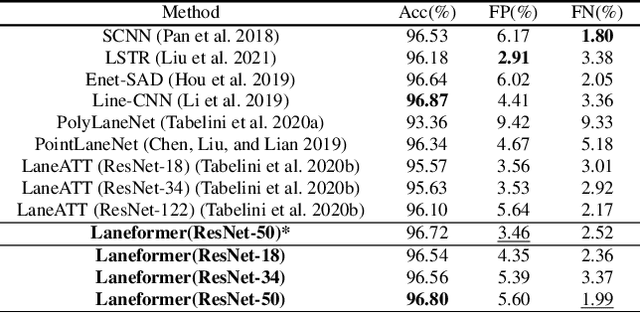
We present Laneformer, a conceptually simple yet powerful transformer-based architecture tailored for lane detection that is a long-standing research topic for visual perception in autonomous driving. The dominant paradigms rely on purely CNN-based architectures which often fail in incorporating relations of long-range lane points and global contexts induced by surrounding objects (e.g., pedestrians, vehicles). Inspired by recent advances of the transformer encoder-decoder architecture in various vision tasks, we move forwards to design a new end-to-end Laneformer architecture that revolutionizes the conventional transformers into better capturing the shape and semantic characteristics of lanes, with minimal overhead in latency. First, coupling with deformable pixel-wise self-attention in the encoder, Laneformer presents two new row and column self-attention operations to efficiently mine point context along with the lane shapes. Second, motivated by the appearing objects would affect the decision of predicting lane segments, Laneformer further includes the detected object instances as extra inputs of multi-head attention blocks in the encoder and decoder to facilitate the lane point detection by sensing semantic contexts. Specifically, the bounding box locations of objects are added into Key module to provide interaction with each pixel and query while the ROI-aligned features are inserted into Value module. Extensive experiments demonstrate our Laneformer achieves state-of-the-art performances on CULane benchmark, in terms of 77.1% F1 score. We hope our simple and effective Laneformer will serve as a strong baseline for future research in self-attention models for lane detection.