 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePO-VLA: Recovery-Driven Policy Optimization for Vision-Language-Action Models
May 10, 2026Vision-Language-Action (VLA) models remain brittle in long-horizon, contact-rich manipulation because success-only imitation provides little supervision for execution drift, while failed rollouts are often discarded. We introduce RePO-VLA, a recovery-driven policy optimization framework that assigns distinct roles to success, recovery, and failure trajectories. RePO-VLA first applies Recovery-Aware Initialization (RAI), slicing recovery segments and resetting history so corrective actions depend on the current adverse state rather than the preceding failure. It then learns a Progress-Aware Semantic Value Function (PAS-VF), aligning spatiotemporal trajectory features with instructions and successful references. The resulting labels salvage useful failure prefixes via reliability decay, while low-value labels mark drift and terminal breakdowns, teaching differences among nominal, failed, and corrective actions. The data engine turns adverse states into planner-generated or human-collected corrective rollouts, teaching recovery to the success manifold. Value-Conditioned Refinement (VCR) trains the policy to prefer high-progress actions. At deployment, a fixed high value ($v=1.0$) biases actions toward the learned success manifold without online failure detectors or heuristic retries. We introduce FRBench, with standardized error injection and recovery-focused evaluation. Across simulated and real-world bimanual tasks, RePO-VLA improves robustness, raising adversarial success from 20% to 75% on average and up to 80% in scaled real-world trials.
RADAR: Revealing Asymmetric Development of Abilities in MLLM Pre-training
Feb 13, 2026Pre-trained Multi-modal Large Language Models (MLLMs) provide a knowledge-rich foundation for post-training by leveraging their inherent perception and reasoning capabilities to solve complex tasks. However, the lack of an efficient evaluation framework impedes the diagnosis of their performance bottlenecks. Current evaluation primarily relies on testing after supervised fine-tuning, which introduces laborious additional training and autoregressive decoding costs. Meanwhile, common pre-training metrics cannot quantify a model's perception and reasoning abilities in a disentangled manner. Furthermore, existing evaluation benchmarks are typically limited in scale or misaligned with pre-training objectives. Thus, we propose RADAR, an efficient ability-centric evaluation framework for Revealing Asymmetric Development of Abilities in MLLM pRe-training. RADAR involves two key components: (1) Soft Discrimination Score, a novel metric for robustly tracking ability development without fine-tuning, based on quantifying nuanced gradations of the model preference for the correct answer over distractors; and (2) Multi-Modal Mixture Benchmark, a new 15K+ sample benchmark for comprehensively evaluating pre-trained MLLMs' perception and reasoning abilities in a 0-shot manner, where we unify authoritative benchmark datasets and carefully collect new datasets, extending the evaluation scope and addressing the critical gaps in current benchmarks. With RADAR, we comprehensively reveal the asymmetric development of perceptual and reasoning capabilities in pretrained MLLMs across diverse factors, including data volume, model size, and pretraining strategy. Our RADAR underscores the need for a decomposed perspective on pre-training ability bottlenecks, informing targeted interventions to advance MLLMs efficiently. Our code is publicly available at https://github.com/Nieysh/RADAR.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025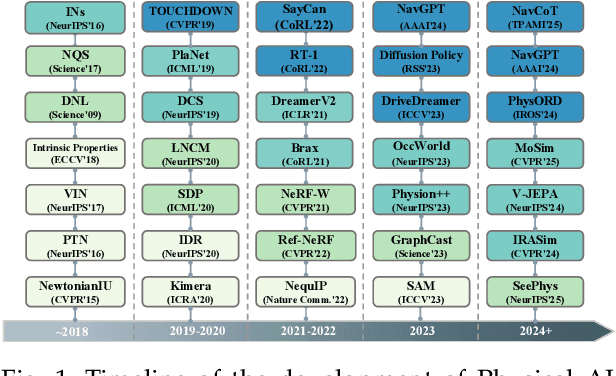
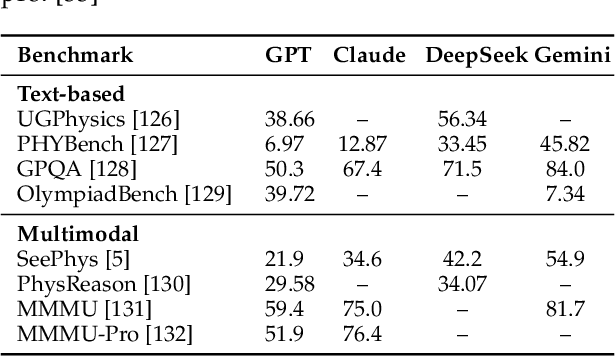
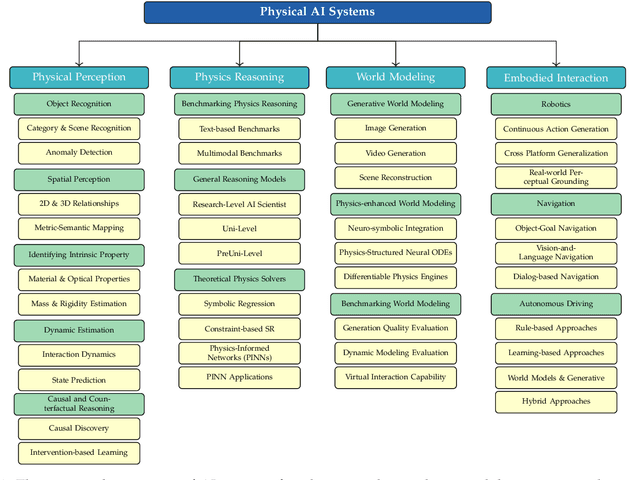
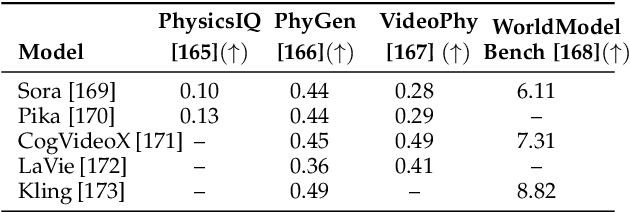
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
PhyBlock: A Progressive Benchmark for Physical Understanding and Planning via 3D Block Assembly
Jun 10, 2025While vision-language models (VLMs) have demonstrated promising capabilities in reasoning and planning for embodied agents, their ability to comprehend physical phenomena, particularly within structured 3D environments, remains severely limited. To close this gap, we introduce PhyBlock, a progressive benchmark designed to assess VLMs on physical understanding and planning through robotic 3D block assembly tasks. PhyBlock integrates a novel four-level cognitive hierarchy assembly task alongside targeted Visual Question Answering (VQA) samples, collectively aimed at evaluating progressive spatial reasoning and fundamental physical comprehension, including object properties, spatial relationships, and holistic scene understanding. PhyBlock includes 2600 block tasks (400 assembly tasks, 2200 VQA tasks) and evaluates models across three key dimensions: partial completion, failure diagnosis, and planning robustness. We benchmark 21 state-of-the-art VLMs, highlighting their strengths and limitations in physically grounded, multi-step planning. Our empirical findings indicate that the performance of VLMs exhibits pronounced limitations in high-level planning and reasoning capabilities, leading to a notable decline in performance for the growing complexity of the tasks. Error analysis reveals persistent difficulties in spatial orientation and dependency reasoning. Surprisingly, chain-of-thought prompting offers minimal improvements, suggesting spatial tasks heavily rely on intuitive model comprehension. We position PhyBlock as a unified testbed to advance embodied reasoning, bridging vision-language understanding and real-world physical problem-solving.
MineAnyBuild: Benchmarking Spatial Planning for Open-world AI Agents
May 26, 2025Spatial Planning is a crucial part in the field of spatial intelligence, which requires the understanding and planning about object arrangements in space perspective. AI agents with the spatial planning ability can better adapt to various real-world applications, including robotic manipulation, automatic assembly, urban planning etc. Recent works have attempted to construct benchmarks for evaluating the spatial intelligence of Multimodal Large Language Models (MLLMs). Nevertheless, these benchmarks primarily focus on spatial reasoning based on typical Visual Question-Answering (VQA) forms, which suffers from the gap between abstract spatial understanding and concrete task execution. In this work, we take a step further to build a comprehensive benchmark called MineAnyBuild, aiming to evaluate the spatial planning ability of open-world AI agents in the Minecraft game. Specifically, MineAnyBuild requires an agent to generate executable architecture building plans based on the given multi-modal human instructions. It involves 4,000 curated spatial planning tasks and also provides a paradigm for infinitely expandable data collection by utilizing rich player-generated content. MineAnyBuild evaluates spatial planning through four core supporting dimensions: spatial understanding, spatial reasoning, creativity, and spatial commonsense. Based on MineAnyBuild, we perform a comprehensive evaluation for existing MLLM-based agents, revealing the severe limitations but enormous potential in their spatial planning abilities. We believe our MineAnyBuild will open new avenues for the evaluation of spatial intelligence and help promote further development for open-world AI agents capable of spatial planning.
Structured Preference Optimization for Vision-Language Long-Horizon Task Planning
Feb 28, 2025Existing methods for vision-language task planning excel in short-horizon tasks but often fall short in complex, long-horizon planning within dynamic environments. These challenges primarily arise from the difficulty of effectively training models to produce high-quality reasoning processes for long-horizon tasks. To address this, we propose Structured Preference Optimization (SPO), which aims to enhance reasoning and action selection in long-horizon task planning through structured preference evaluation and optimized training strategies. Specifically, SPO introduces: 1) Preference-Based Scoring and Optimization, which systematically evaluates reasoning chains based on task relevance, visual grounding, and historical consistency; and 2) Curriculum-Guided Training, where the model progressively adapts from simple to complex tasks, improving its generalization ability in long-horizon scenarios and enhancing reasoning robustness. To advance research in vision-language long-horizon task planning, we introduce ExtendaBench, a comprehensive benchmark covering 1,509 tasks across VirtualHome and Habitat 2.0, categorized into ultra-short, short, medium, and long tasks. Experimental results demonstrate that SPO significantly improves reasoning quality and final decision accuracy, outperforming prior methods on long-horizon tasks and underscoring the effectiveness of preference-driven optimization in vision-language task planning. Specifically, SPO achieves a +5.98% GCR and +4.68% SR improvement in VirtualHome and a +3.30% GCR and +2.11% SR improvement in Habitat over the best-performing baselines.
PIVOT-R: Primitive-Driven Waypoint-Aware World Model for Robotic Manipulation
Oct 14, 2024



Language-guided robotic manipulation is a challenging task that requires an embodied agent to follow abstract user instructions to accomplish various complex manipulation tasks. Previous work trivially fitting the data without revealing the relation between instruction and low-level executable actions, these models are prone to memorizing the surficial pattern of the data instead of acquiring the transferable knowledge, and thus are fragile to dynamic environment changes. To address this issue, we propose a PrIrmitive-driVen waypOinT-aware world model for Robotic manipulation (PIVOT-R) that focuses solely on the prediction of task-relevant waypoints. Specifically, PIVOT-R consists of a Waypoint-aware World Model (WAWM) and a lightweight action prediction module. The former performs primitive action parsing and primitive-driven waypoint prediction, while the latter focuses on decoding low-level actions. Additionally, we also design an asynchronous hierarchical executor (AHE), which can use different execution frequencies for different modules of the model, thereby helping the model reduce computational redundancy and improve model execution efficiency. Our PIVOT-R outperforms state-of-the-art (SoTA) open-source models on the SeaWave benchmark, achieving an average relative improvement of 19.45% across four levels of instruction tasks. Moreover, compared to the synchronously executed PIVOT-R, the execution efficiency of PIVOT-R with AHE is increased by 28-fold, with only a 2.9% drop in performance. These results provide compelling evidence that our PIVOT-R can significantly improve both the performance and efficiency of robotic manipulation.
Affordances-Oriented Planning using Foundation Models for Continuous Vision-Language Navigation
Jul 08, 2024



LLM-based agents have demonstrated impressive zero-shot performance in the vision-language navigation (VLN) task. However, these zero-shot methods focus only on solving high-level task planning by selecting nodes in predefined navigation graphs for movements, overlooking low-level control in realistic navigation scenarios. To bridge this gap, we propose AO-Planner, a novel affordances-oriented planning framework for continuous VLN task. Our AO-Planner integrates various foundation models to achieve affordances-oriented motion planning and action decision-making, both performed in a zero-shot manner. Specifically, we employ a visual affordances prompting (VAP) approach, where visible ground is segmented utilizing SAM to provide navigational affordances, based on which the LLM selects potential next waypoints and generates low-level path planning towards selected waypoints. We further introduce a high-level agent, PathAgent, to identify the most probable pixel-based path and convert it into 3D coordinates to fulfill low-level motion. Experimental results on the challenging R2R-CE benchmark demonstrate that AO-Planner achieves state-of-the-art zero-shot performance (5.5% improvement in SPL). Our method establishes an effective connection between LLM and 3D world to circumvent the difficulty of directly predicting world coordinates, presenting novel prospects for employing foundation models in low-level motion control.
Correctable Landmark Discovery via Large Models for Vision-Language Navigation
May 29, 2024



Vision-Language Navigation (VLN) requires the agent to follow language instructions to reach a target position. A key factor for successful navigation is to align the landmarks implied in the instruction with diverse visual observations. However, previous VLN agents fail to perform accurate modality alignment especially in unexplored scenes, since they learn from limited navigation data and lack sufficient open-world alignment knowledge. In this work, we propose a new VLN paradigm, called COrrectable LaNdmark DiScOvery via Large ModEls (CONSOLE). In CONSOLE, we cast VLN as an open-world sequential landmark discovery problem, by introducing a novel correctable landmark discovery scheme based on two large models ChatGPT and CLIP. Specifically, we use ChatGPT to provide rich open-world landmark cooccurrence commonsense, and conduct CLIP-driven landmark discovery based on these commonsense priors. To mitigate the noise in the priors due to the lack of visual constraints, we introduce a learnable cooccurrence scoring module, which corrects the importance of each cooccurrence according to actual observations for accurate landmark discovery. We further design an observation enhancement strategy for an elegant combination of our framework with different VLN agents, where we utilize the corrected landmark features to obtain enhanced observation features for action decision. Extensive experimental results on multiple popular VLN benchmarks (R2R, REVERIE, R4R, RxR) show the significant superiority of CONSOLE over strong baselines. Especially, our CONSOLE establishes the new state-of-the-art results on R2R and R4R in unseen scenarios. Code is available at https://github.com/expectorlin/CONSOLE.
NavCoT: Boosting LLM-Based Vision-and-Language Navigation via Learning Disentangled Reasoning
Mar 12, 2024



Vision-and-Language Navigation (VLN), as a crucial research problem of Embodied AI, requires an embodied agent to navigate through complex 3D environments following natural language instructions. Recent research has highlighted the promising capacity of large language models (LLMs) in VLN by improving navigational reasoning accuracy and interpretability. However, their predominant use in an offline manner usually suffers from substantial domain gap between the VLN task and the LLM training corpus. This paper introduces a novel strategy called Navigational Chain-of-Thought (NavCoT), where we fulfill parameter-efficient in-domain training to enable self-guided navigational decision, leading to a significant mitigation of the domain gap in a cost-effective manner. Specifically, at each timestep, the LLM is prompted to forecast the navigational chain-of-thought by: 1) acting as a world model to imagine the next observation according to the instruction, 2) selecting the candidate observation that best aligns with the imagination, and 3) determining the action based on the reasoning from the prior steps. Through constructing formalized labels for training, the LLM can learn to generate desired and reasonable chain-of-thought outputs for improving the action decision. Experimental results across various training settings and popular VLN benchmarks (e.g., Room-to-Room (R2R), Room-across-Room (RxR), Room-for-Room (R4R)) show the significant superiority of NavCoT over the direct action prediction variants. Through simple parameter-efficient finetuning, our NavCoT outperforms a recent GPT4-based approach with ~7% relative improvement on the R2R dataset. We believe that NavCoT will help unlock more task-adaptive and scalable LLM-based embodied agents, which are helpful for developing real-world robotics applications. Code is available at https://github.com/expectorlin/NavCoT.