 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Revealing Asymmetric Development of Abilities in MLLM Pre-training
Feb 13, 2026Pre-trained Multi-modal Large Language Models (MLLMs) provide a knowledge-rich foundation for post-training by leveraging their inherent perception and reasoning capabilities to solve complex tasks. However, the lack of an efficient evaluation framework impedes the diagnosis of their performance bottlenecks. Current evaluation primarily relies on testing after supervised fine-tuning, which introduces laborious additional training and autoregressive decoding costs. Meanwhile, common pre-training metrics cannot quantify a model's perception and reasoning abilities in a disentangled manner. Furthermore, existing evaluation benchmarks are typically limited in scale or misaligned with pre-training objectives. Thus, we propose RADAR, an efficient ability-centric evaluation framework for Revealing Asymmetric Development of Abilities in MLLM pRe-training. RADAR involves two key components: (1) Soft Discrimination Score, a novel metric for robustly tracking ability development without fine-tuning, based on quantifying nuanced gradations of the model preference for the correct answer over distractors; and (2) Multi-Modal Mixture Benchmark, a new 15K+ sample benchmark for comprehensively evaluating pre-trained MLLMs' perception and reasoning abilities in a 0-shot manner, where we unify authoritative benchmark datasets and carefully collect new datasets, extending the evaluation scope and addressing the critical gaps in current benchmarks. With RADAR, we comprehensively reveal the asymmetric development of perceptual and reasoning capabilities in pretrained MLLMs across diverse factors, including data volume, model size, and pretraining strategy. Our RADAR underscores the need for a decomposed perspective on pre-training ability bottlenecks, informing targeted interventions to advance MLLMs efficiently. Our code is publicly available at https://github.com/Nieysh/RADAR.
PanGu-Draw: Advancing Resource-Efficient Text-to-Image Synthesis with Time-Decoupled Training and Reusable Coop-Diffusion
Dec 29, 2023



Current large-scale diffusion models represent a giant leap forward in conditional image synthesis, capable of interpreting diverse cues like text, human poses, and edges. However, their reliance on substantial computational resources and extensive data collection remains a bottleneck. On the other hand, the integration of existing diffusion models, each specialized for different controls and operating in unique latent spaces, poses a challenge due to incompatible image resolutions and latent space embedding structures, hindering their joint use. Addressing these constraints, we present "PanGu-Draw", a novel latent diffusion model designed for resource-efficient text-to-image synthesis that adeptly accommodates multiple control signals. We first propose a resource-efficient Time-Decoupling Training Strategy, which splits the monolithic text-to-image model into structure and texture generators. Each generator is trained using a regimen that maximizes data utilization and computational efficiency, cutting data preparation by 48% and reducing training resources by 51%. Secondly, we introduce "Coop-Diffusion", an algorithm that enables the cooperative use of various pre-trained diffusion models with different latent spaces and predefined resolutions within a unified denoising process. This allows for multi-control image synthesis at arbitrary resolutions without the necessity for additional data or retraining. Empirical validations of Pangu-Draw show its exceptional prowess in text-to-image and multi-control image generation, suggesting a promising direction for future model training efficiencies and generation versatility. The largest 5B T2I PanGu-Draw model is released on the Ascend platform. Project page: $\href{https://pangu-draw.github.io}{this~https~URL}$
Visual Exemplar Driven Task-Prompting for Unified Perception in Autonomous Driving
Mar 03, 2023Multi-task learning has emerged as a powerful paradigm to solve a range of tasks simultaneously with good efficiency in both computation resources and inference time. However, these algorithms are designed for different tasks mostly not within the scope of autonomous driving, thus making it hard to compare multi-task methods in autonomous driving. Aiming to enable the comprehensive evaluation of present multi-task learning methods in autonomous driving, we extensively investigate the performance of popular multi-task methods on the large-scale driving dataset, which covers four common perception tasks, i.e., object detection, semantic segmentation, drivable area segmentation, and lane detection. We provide an in-depth analysis of current multi-task learning methods under different common settings and find out that the existing methods make progress but there is still a large performance gap compared with single-task baselines. To alleviate this dilemma in autonomous driving, we present an effective multi-task framework, VE-Prompt, which introduces visual exemplars via task-specific prompting to guide the model toward learning high-quality task-specific representations. Specifically, we generate visual exemplars based on bounding boxes and color-based markers, which provide accurate visual appearances of target categories and further mitigate the performance gap. Furthermore, we bridge transformer-based encoders and convolutional layers for efficient and accurate unified perception in autonomous driving. Comprehensive experimental results on the diverse self-driving dataset BDD100K show that the VE-Prompt improves the multi-task baseline and further surpasses single-task models.
Point2Seq: Detecting 3D Objects as Sequences
Mar 25, 2022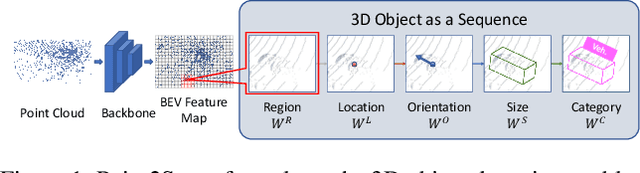
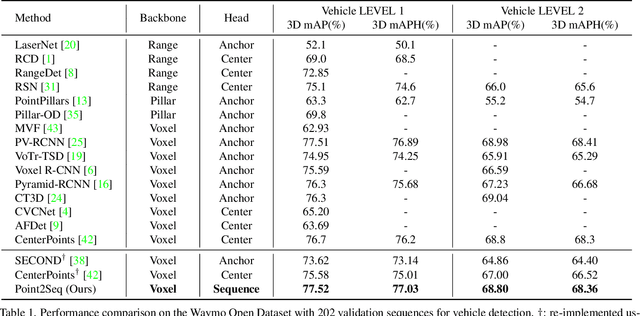
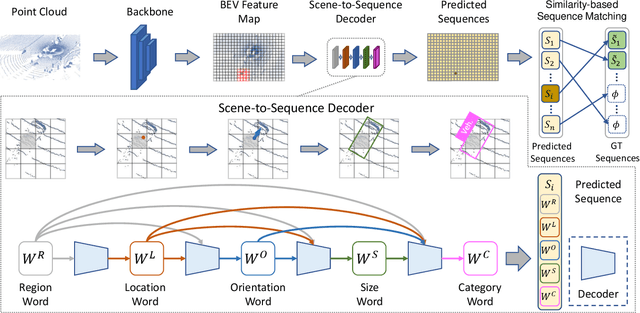
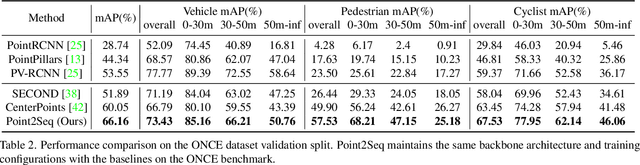
We present a simple and effective framework, named Point2Seq, for 3D object detection from point clouds. In contrast to previous methods that normally {predict attributes of 3D objects all at once}, we expressively model the interdependencies between attributes of 3D objects, which in turn enables a better detection accuracy. Specifically, we view each 3D object as a sequence of words and reformulate the 3D object detection task as decoding words from 3D scenes in an auto-regressive manner. We further propose a lightweight scene-to-sequence decoder that can auto-regressively generate words conditioned on features from a 3D scene as well as cues from the preceding words. The predicted words eventually constitute a set of sequences that completely describe the 3D objects in the scene, and all the predicted sequences are then automatically assigned to the respective ground truths through similarity-based sequence matching. Our approach is conceptually intuitive and can be readily plugged upon most existing 3D-detection backbones without adding too much computational overhead; the sequential decoding paradigm we proposed, on the other hand, can better exploit information from complex 3D scenes with the aid of preceding predicted words. Without bells and whistles, our method significantly outperforms previous anchor- and center-based 3D object detection frameworks, yielding the new state of the art on the challenging ONCE dataset as well as the Waymo Open Dataset. Code is available at \url{https://github.com/ocNflag/point2seq}.
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
Mar 10, 2022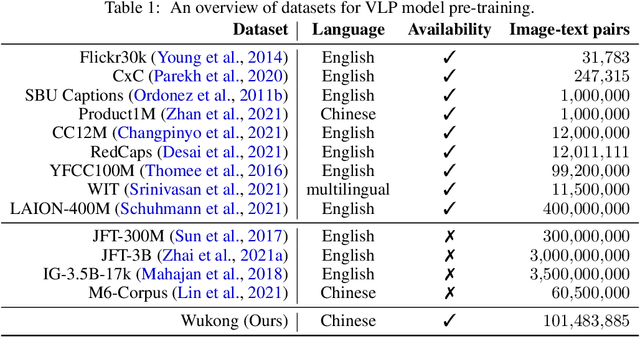


Vision-Language Pre-training (VLP) models have shown remarkable performance on various downstream tasks. Their success heavily relies on the scale of pre-trained cross-modal datasets. However, the lack of large-scale datasets and benchmarks in Chinese hinders the development of Chinese VLP models and broader multilingual applications. In this work, we release a large-scale Chinese cross-modal dataset named Wukong, containing 100 million Chinese image-text pairs from the web. Wukong aims to benchmark different multi-modal pre-training methods to facilitate the VLP research and community development. Furthermore, we release a group of models pre-trained with various image encoders (ViT-B/ViT-L/SwinT) and also apply advanced pre-training techniques into VLP such as locked-image text tuning, token-wise similarity in contrastive learning, and reduced-token interaction. Extensive experiments and a deep benchmarking of different downstream tasks are also provided. Experiments show that Wukong can serve as a promising Chinese pre-training dataset and benchmark for different cross-modal learning methods. For the zero-shot image classification task on 10 datasets, our model achieves an average accuracy of 73.03%. For the image-text retrieval task,our model achieves a mean recall of 71.6% on AIC-ICC which is 12.9% higher than the result of WenLan 2.0. More information can refer to https://wukong-dataset.github.io/wukong-dataset/.
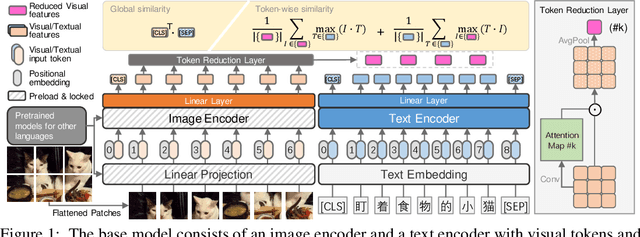
FILIP: Fine-grained Interactive Language-Image Pre-Training
Nov 09, 2021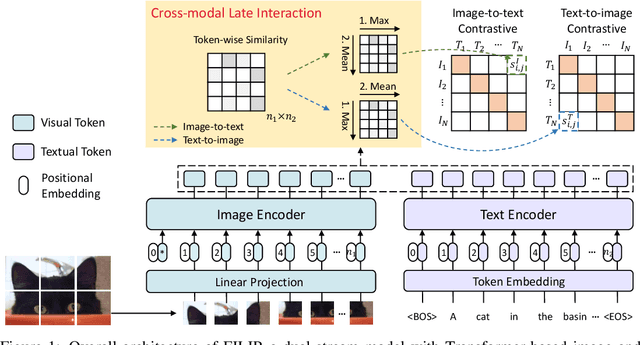
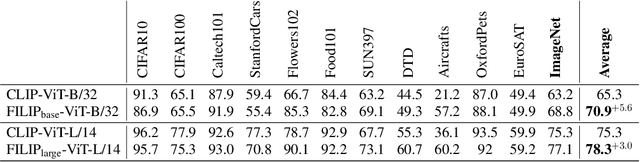
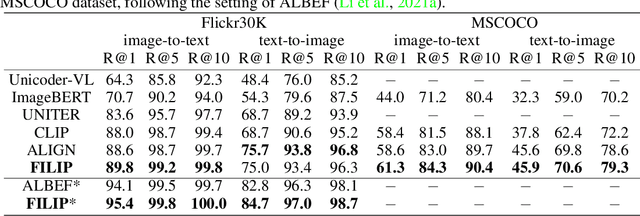

Unsupervised large-scale vision-language pre-training has shown promising advances on various downstream tasks. Existing methods often model the cross-modal interaction either via the similarity of the global feature of each modality which misses sufficient information, or finer-grained interactions using cross/self-attention upon visual and textual tokens. However, cross/self-attention suffers from inferior efficiency in both training and inference. In this paper, we introduce a large-scale Fine-grained Interactive Language-Image Pre-training (FILIP) to achieve finer-level alignment through a cross-modal late interaction mechanism, which uses a token-wise maximum similarity between visual and textual tokens to guide the contrastive objective. FILIP successfully leverages the finer-grained expressiveness between image patches and textual words by modifying only contrastive loss, while simultaneously gaining the ability to pre-compute image and text representations offline at inference, keeping both large-scale training and inference efficient. Furthermore, we construct a new large-scale image-text pair dataset called FILIP300M for pre-training. Experiments show that FILIP achieves state-of-the-art performance on multiple downstream vision-language tasks including zero-shot image classification and image-text retrieval. The visualization on word-patch alignment further shows that FILIP can learn meaningful fine-grained features with promising localization ability.
Voxel Transformer for 3D Object Detection
Sep 13, 2021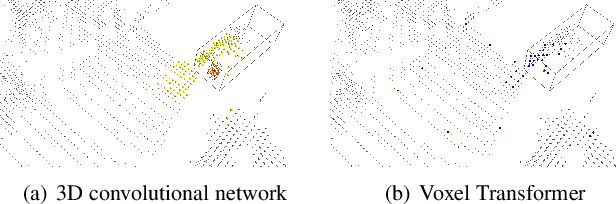
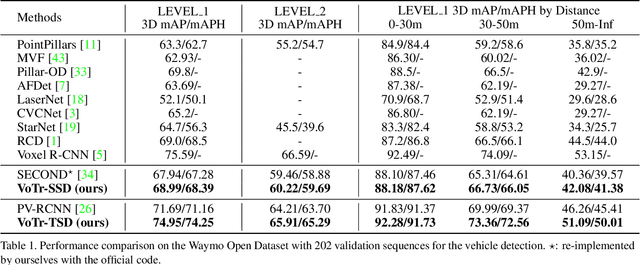
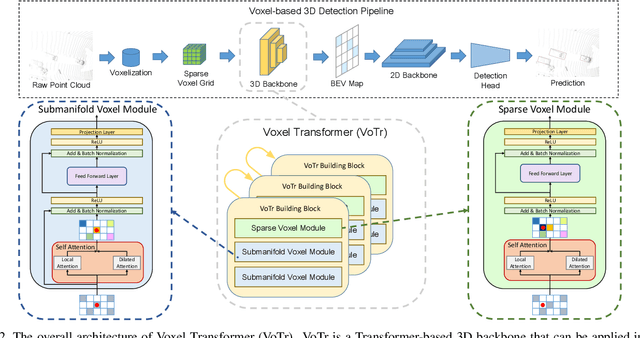
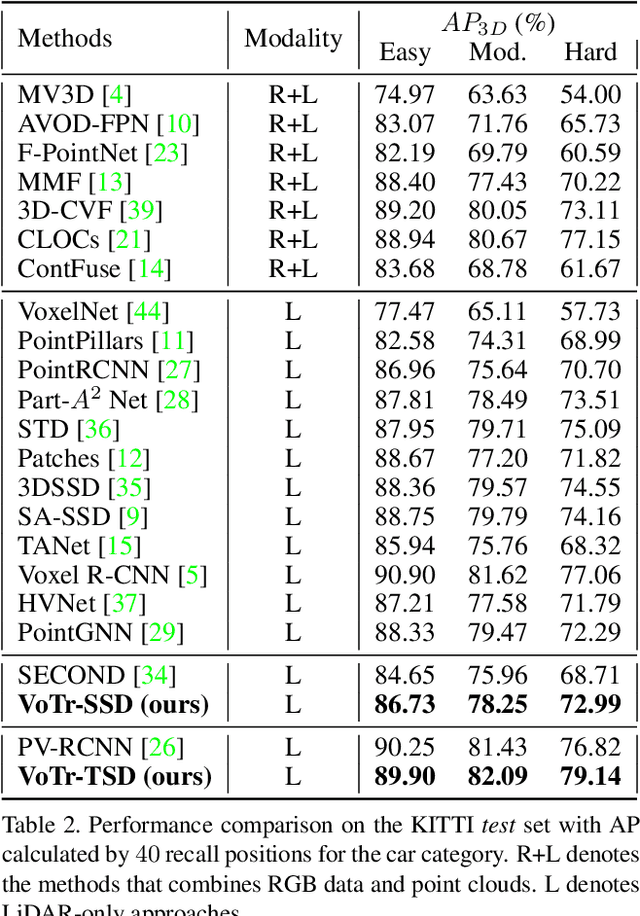
We present Voxel Transformer (VoTr), a novel and effective voxel-based Transformer backbone for 3D object detection from point clouds. Conventional 3D convolutional backbones in voxel-based 3D detectors cannot efficiently capture large context information, which is crucial for object recognition and localization, owing to the limited receptive fields. In this paper, we resolve the problem by introducing a Transformer-based architecture that enables long-range relationships between voxels by self-attention. Given the fact that non-empty voxels are naturally sparse but numerous, directly applying standard Transformer on voxels is non-trivial. To this end, we propose the sparse voxel module and the submanifold voxel module, which can operate on the empty and non-empty voxel positions effectively. To further enlarge the attention range while maintaining comparable computational overhead to the convolutional counterparts, we propose two attention mechanisms for multi-head attention in those two modules: Local Attention and Dilated Attention, and we further propose Fast Voxel Query to accelerate the querying process in multi-head attention. VoTr contains a series of sparse and submanifold voxel modules and can be applied in most voxel-based detectors. Our proposed VoTr shows consistent improvement over the convolutional baselines while maintaining computational efficiency on the KITTI dataset and the Waymo Open dataset.
Pyramid R-CNN: Towards Better Performance and Adaptability for 3D Object Detection
Sep 06, 2021
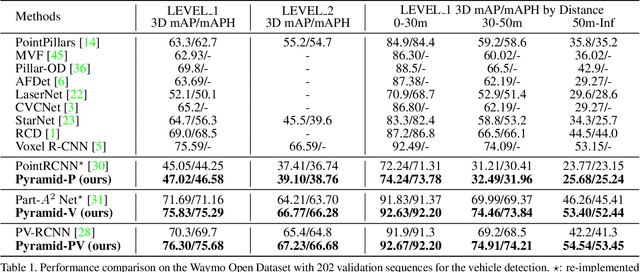
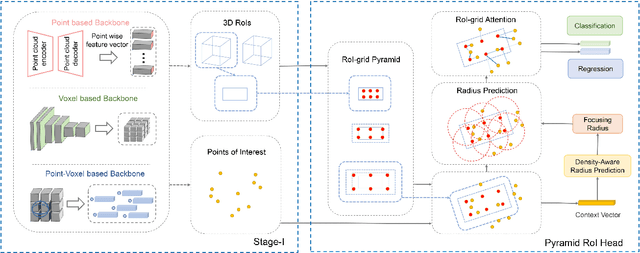

We present a flexible and high-performance framework, named Pyramid R-CNN, for two-stage 3D object detection from point clouds. Current approaches generally rely on the points or voxels of interest for RoI feature extraction on the second stage, but cannot effectively handle the sparsity and non-uniform distribution of those points, and this may result in failures in detecting objects that are far away. To resolve the problems, we propose a novel second-stage module, named pyramid RoI head, to adaptively learn the features from the sparse points of interest. The pyramid RoI head consists of three key components. Firstly, we propose the RoI-grid Pyramid, which mitigates the sparsity problem by extensively collecting points of interest for each RoI in a pyramid manner. Secondly, we propose RoI-grid Attention, a new operation that can encode richer information from sparse points by incorporating conventional attention-based and graph-based point operators into a unified formulation. Thirdly, we propose the Density-Aware Radius Prediction (DARP) module, which can adapt to different point density levels by dynamically adjusting the focusing range of RoIs. Combining the three components, our pyramid RoI head is robust to the sparse and imbalanced circumstances, and can be applied upon various 3D backbones to consistently boost the detection performance. Extensive experiments show that Pyramid R-CNN outperforms the state-of-the-art 3D detection models by a large margin on both the KITTI dataset and the Waymo Open dataset.
One Million Scenes for Autonomous Driving: ONCE Dataset
Jun 21, 2021
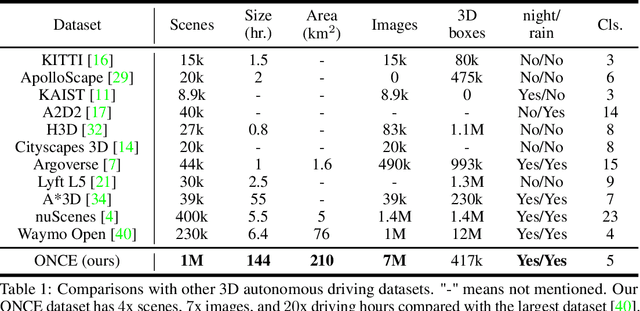
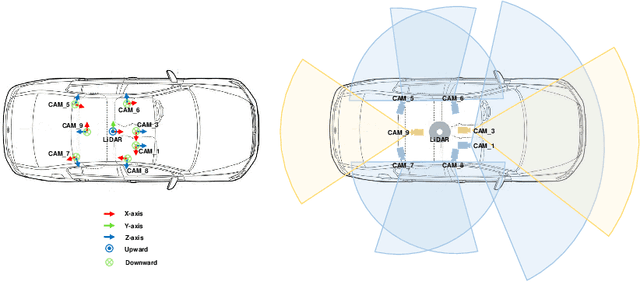

Current perception models in autonomous driving have become notorious for greatly relying on a mass of annotated data to cover unseen cases and address the long-tail problem. On the other hand, learning from unlabeled large-scale collected data and incrementally self-training powerful recognition models have received increasing attention and may become the solutions of next-generation industry-level powerful and robust perception models in autonomous driving. However, the research community generally suffered from data inadequacy of those essential real-world scene data, which hampers the future exploration of fully/semi/self-supervised methods for 3D perception. In this paper, we introduce the ONCE (One millioN sCenEs) dataset for 3D object detection in the autonomous driving scenario. The ONCE dataset consists of 1 million LiDAR scenes and 7 million corresponding camera images. The data is selected from 144 driving hours, which is 20x longer than the largest 3D autonomous driving dataset available (e.g. nuScenes and Waymo), and it is collected across a range of different areas, periods and weather conditions. To facilitate future research on exploiting unlabeled data for 3D detection, we additionally provide a benchmark in which we reproduce and evaluate a variety of self-supervised and semi-supervised methods on the ONCE dataset. We conduct extensive analyses on those methods and provide valuable observations on their performance related to the scale of used data. Data, code, and more information are available at https://once-for-auto-driving.github.io/index.html.
Product-based Neural Networks for User Response Prediction over Multi-field Categorical Data
Jul 01, 2018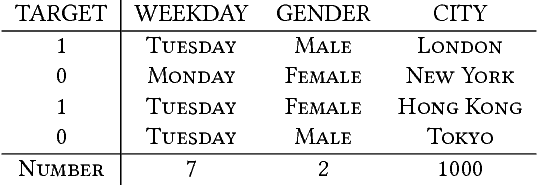

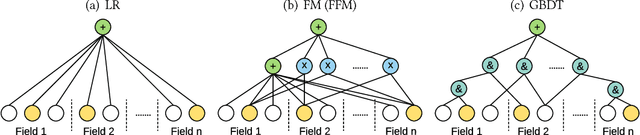
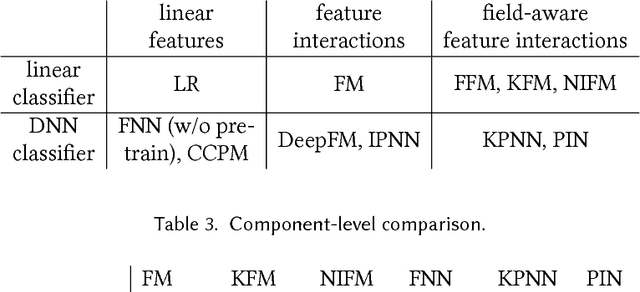
User response prediction is a crucial component for personalized information retrieval and filtering scenarios, such as recommender system and web search. The data in user response prediction is mostly in a multi-field categorical format and transformed into sparse representations via one-hot encoding. Due to the sparsity problems in representation and optimization, most research focuses on feature engineering and shallow modeling. Recently, deep neural networks have attracted research attention on such a problem for their high capacity and end-to-end training scheme. In this paper, we study user response prediction in the scenario of click prediction. We first analyze a coupled gradient issue in latent vector-based models and propose kernel product to learn field-aware feature interactions. Then we discuss an insensitive gradient issue in DNN-based models and propose Product-based Neural Network (PNN) which adopts a feature extractor to explore feature interactions. Generalizing the kernel product to a net-in-net architecture, we further propose Product-network In Network (PIN) which can generalize previous models. Extensive experiments on 4 industrial datasets and 1 contest dataset demonstrate that our models consistently outperform 8 baselines on both AUC and log loss. Besides, PIN makes great CTR improvement (relatively 34.67%) in online A/B test.