 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicSeg: Open-World Segmentation Pretraining via Counterfactural Diffusion-Based Auto-Generation
Mar 20, 2026Open-world semantic segmentation presently relies significantly on extensive image-text pair datasets, which often suffer from a lack of fine-grained pixel annotations on sufficient categories. The acquisition of such data is rendered economically prohibitive due to the substantial investments of both human labor and time. In light of the formidable image generation capabilities of diffusion models, we introduce a novel diffusion model-driven pipeline for automatically generating datasets tailored to the needs of open-world semantic segmentation, named "MagicSeg". Our MagicSeg initiates from class labels and proceeds to generate high-fidelity textual descriptions, which in turn serve as guidance for the diffusion model to generate images. Rather than only generating positive samples for each label, our process encompasses the simultaneous generation of corresponding negative images, designed to serve as paired counterfactual samples for contrastive training. Then, to provide a self-supervised signal for open-world segmentation pretraining, our MagicSeg integrates an open-vocabulary detection model and an interactive segmentation model to extract object masks as precise segmentation labels from images based on the provided category labels. By applying our dataset to the contrastive language-image pretraining model with the pseudo mask supervision and the auxiliary counterfactual contrastive training, the downstream model obtains strong performance on open-world semantic segmentation. We evaluate our model on PASCAL VOC, PASCAL Context, and COCO, achieving SOTA with performance of 62.9%, 26.7%, and 40.2%, respectively, demonstrating our dataset's effectiveness in enhancing open-world semantic segmentation capabilities. Project website: https://github.com/ckxhp/magicseg.
Towards Unified Multimodal Interleaved Generation via Group Relative Policy Optimization
Mar 10, 2026Unified vision-language models have made significant progress in multimodal understanding and generation, yet they largely fall short in producing multimodal interleaved outputs, which is a crucial capability for tasks like visual storytelling and step-by-step visual reasoning. In this work, we propose a reinforcement learning-based post-training strategy to unlock this capability in existing unified models, without relying on large-scale multimodal interleaved datasets. We begin with a warm-up stage using a hybrid dataset comprising curated interleaved sequences and limited data for multimodal understanding and text-to-image generation, which exposes the model to interleaved generation patterns while preserving its pretrained capabilities. To further refine interleaved generation, we propose a unified policy optimization framework that extends Group Relative Policy Optimization (GRPO) to the multimodal setting. Our approach jointly models text and image generation within a single decoding trajectory and optimizes it with our novel hybrid rewards covering textual relevance, visual-text alignment, and structural fidelity. Additionally, we incorporate process-level rewards to provide step-wise guidance, enhancing training efficiency in complex multimodal tasks. Experiments on MMIE and InterleavedBench demonstrate that our approach significantly enhances the quality and coherence of multimodal interleaved generation.
AtomicVLA: Unlocking the Potential of Atomic Skill Learning in Robots
Mar 08, 2026Recent advances in Visual-Language-Action (VLA) models have shown promising potential for robotic manipulation tasks. However, real-world robotic tasks often involve long-horizon, multi-step problem-solving and require generalization for continual skill acquisition, extending beyond single actions or skills. These challenges present significant barriers for existing VLA models, which use monolithic action decoders trained on aggregated data, resulting in poor scalability. To address these challenges, we propose AtomicVLA, a unified planning-and-execution framework that jointly generates task-level plans, atomic skill abstractions, and fine-grained actions. AtomicVLA constructs a scalable atomic skill library through a Skill-Guided Mixture-of-Experts (SG-MoE), where each expert specializes in mastering generic yet precise atomic skills. Furthermore, we introduce a flexible routing encoder that automatically assigns dedicated atomic experts to new skills, enabling continual learning. We validate our approach through extensive experiments. In simulation, AtomicVLA outperforms $π_{0}$ by 2.4\% on LIBERO, 10\% on LIBERO-LONG, and outperforms $π_{0}$ and $π_{0.5}$ by 0.22 and 0.25 in average task length on CALVIN. Additionally, our AtomicVLA consistently surpasses baselines by 18.3\% and 21\% in real-world long-horizon tasks and continual learning. These results highlight the effectiveness of atomic skill abstraction and dynamic expert composition for long-horizon and lifelong robotic tasks. The project page is \href{https://zhanglk9.github.io/atomicvla-web/}{here}.
CGL: Advancing Continual GUI Learning via Reinforcement Fine-Tuning
Mar 03, 2026Graphical User Interface (GUI) Agents, benefiting from recent advances in multimodal large language models (MLLM), have achieved significant development. However, due to the frequent updates of GUI applications, adapting to new tasks without forgetting old tasks in GUI continual learning remains an open problem. In this work, we reveal that while Supervised Fine-Tuning (SFT) facilitates fast adaptation, it often triggers knowledge overwriting, whereas Reinforcement Learning (RL) demonstrates an inherent resilience that shields prior interaction logic from erasure. Based on this insight, we propose a \textbf{C}ontinual \textbf{G}UI \textbf{L}earning (CGL) framework that dynamically balances adaptation efficiency and skill retention by enhancing the synergy between SFT and RL. Specifically, we introduce an SFT proportion adjustment mechanism guided by policy entropy to dynamically control the weight allocation between the SFT and RL training phases. To resolve explicit gradient interference, we further develop a specialized gradient surgery strategy. By projecting exploratory SFT gradients onto GRPO-based anchor gradients, our method explicitly clips the components of SFT gradients that conflict with GRPO. On top of that, we establish an AndroidControl-CL benchmark, which divides GUI applications into distinct task groups to effectively simulate and evaluate the performance of continual GUI learning. Experimental results demonstrate the effectiveness of our proposed CGL framework across continual learning scenarios. The benchmark, code, and model will be made publicly available.
RADAR: Revealing Asymmetric Development of Abilities in MLLM Pre-training
Feb 13, 2026Pre-trained Multi-modal Large Language Models (MLLMs) provide a knowledge-rich foundation for post-training by leveraging their inherent perception and reasoning capabilities to solve complex tasks. However, the lack of an efficient evaluation framework impedes the diagnosis of their performance bottlenecks. Current evaluation primarily relies on testing after supervised fine-tuning, which introduces laborious additional training and autoregressive decoding costs. Meanwhile, common pre-training metrics cannot quantify a model's perception and reasoning abilities in a disentangled manner. Furthermore, existing evaluation benchmarks are typically limited in scale or misaligned with pre-training objectives. Thus, we propose RADAR, an efficient ability-centric evaluation framework for Revealing Asymmetric Development of Abilities in MLLM pRe-training. RADAR involves two key components: (1) Soft Discrimination Score, a novel metric for robustly tracking ability development without fine-tuning, based on quantifying nuanced gradations of the model preference for the correct answer over distractors; and (2) Multi-Modal Mixture Benchmark, a new 15K+ sample benchmark for comprehensively evaluating pre-trained MLLMs' perception and reasoning abilities in a 0-shot manner, where we unify authoritative benchmark datasets and carefully collect new datasets, extending the evaluation scope and addressing the critical gaps in current benchmarks. With RADAR, we comprehensively reveal the asymmetric development of perceptual and reasoning capabilities in pretrained MLLMs across diverse factors, including data volume, model size, and pretraining strategy. Our RADAR underscores the need for a decomposed perspective on pre-training ability bottlenecks, informing targeted interventions to advance MLLMs efficiently. Our code is publicly available at https://github.com/Nieysh/RADAR.
Thinking with Geometry: Active Geometry Integration for Spatial Reasoning
Feb 05, 2026Recent progress in spatial reasoning with Multimodal Large Language Models (MLLMs) increasingly leverages geometric priors from 3D encoders. However, most existing integration strategies remain passive: geometry is exposed as a global stream and fused in an indiscriminate manner, which often induces semantic-geometry misalignment and redundant signals. We propose GeoThinker, a framework that shifts the paradigm from passive fusion to active perception. Instead of feature mixing, GeoThinker enables the model to selectively retrieve geometric evidence conditioned on its internal reasoning demands. GeoThinker achieves this through Spatial-Grounded Fusion applied at carefully selected VLM layers, where semantic visual priors selectively query and integrate task-relevant geometry via frame-strict cross-attention, further calibrated by Importance Gating that biases per-frame attention toward task-relevant structures. Comprehensive evaluation results show that GeoThinker sets a new state-of-the-art in spatial intelligence, achieving a peak score of 72.6 on the VSI-Bench. Furthermore, GeoThinker demonstrates robust generalization and significantly improved spatial perception across complex downstream scenarios, including embodied referring and autonomous driving. Our results indicate that the ability to actively integrate spatial structures is essential for next-generation spatial intelligence. Code can be found at https://github.com/Li-Hao-yuan/GeoThinker.
SlowFocus: Enhancing Fine-grained Temporal Understanding in Video LLM
Feb 03, 2026Large language models (LLMs) have demonstrated exceptional capabilities in text understanding, which has paved the way for their expansion into video LLMs (Vid-LLMs) to analyze video data. However, current Vid-LLMs struggle to simultaneously retain high-quality frame-level semantic information (i.e., a sufficient number of tokens per frame) and comprehensive video-level temporal information (i.e., an adequate number of sampled frames per video). This limitation hinders the advancement of Vid-LLMs towards fine-grained video understanding. To address this issue, we introduce the SlowFocus mechanism, which significantly enhances the equivalent sampling frequency without compromising the quality of frame-level visual tokens. SlowFocus begins by identifying the query-related temporal segment based on the posed question, then performs dense sampling on this segment to extract local high-frequency features. A multi-frequency mixing attention module is further leveraged to aggregate these local high-frequency details with global low-frequency contexts for enhanced temporal comprehension. Additionally, to tailor Vid-LLMs to this innovative mechanism, we introduce a set of training strategies aimed at bolstering both temporal grounding and detailed temporal reasoning capabilities. Furthermore, we establish FineAction-CGR, a benchmark specifically devised to assess the ability of Vid-LLMs to process fine-grained temporal understanding tasks. Comprehensive experiments demonstrate the superiority of our mechanism across both existing public video understanding benchmarks and our proposed FineAction-CGR.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025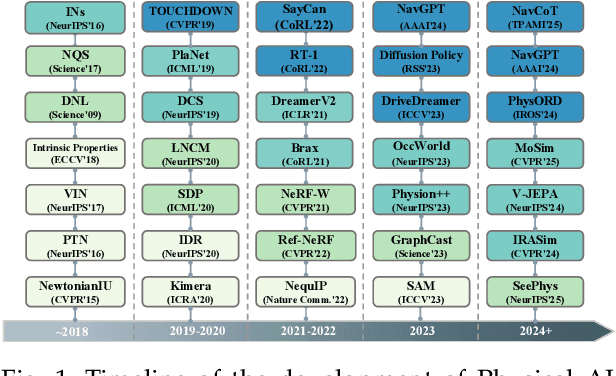
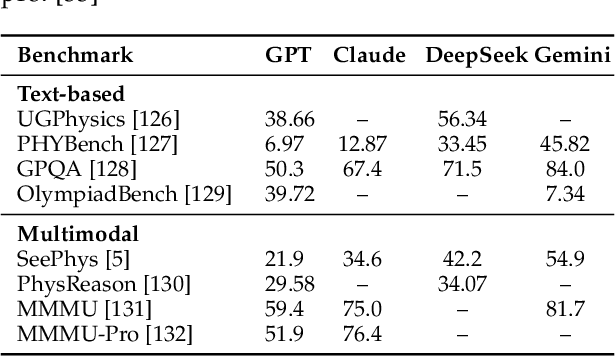
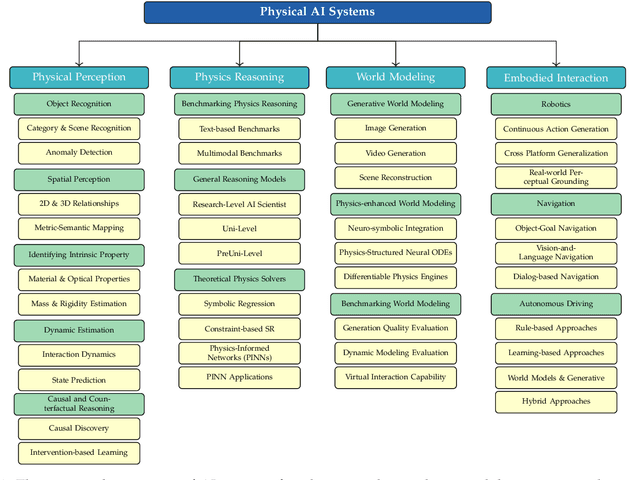
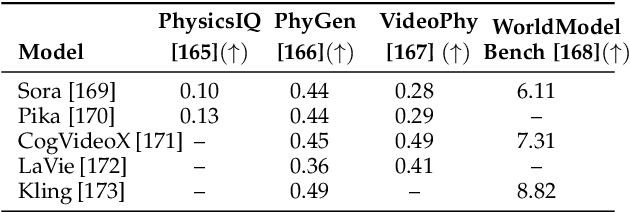
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
Jul 22, 2025



Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.
Does Your 3D Encoder Really Work? When Pretrain-SFT from 2D VLMs Meets 3D VLMs
Jun 06, 2025



Remarkable progress in 2D Vision-Language Models (VLMs) has spurred interest in extending them to 3D settings for tasks like 3D Question Answering, Dense Captioning, and Visual Grounding. Unlike 2D VLMs that typically process images through an image encoder, 3D scenes, with their intricate spatial structures, allow for diverse model architectures. Based on their encoder design, this paper categorizes recent 3D VLMs into 3D object-centric, 2D image-based, and 3D scene-centric approaches. Despite the architectural similarity of 3D scene-centric VLMs to their 2D counterparts, they have exhibited comparatively lower performance compared with the latest 3D object-centric and 2D image-based approaches. To understand this gap, we conduct an in-depth analysis, revealing that 3D scene-centric VLMs show limited reliance on the 3D scene encoder, and the pre-train stage appears less effective than in 2D VLMs. Furthermore, we observe that data scaling benefits are less pronounced on larger datasets. Our investigation suggests that while these models possess cross-modal alignment capabilities, they tend to over-rely on linguistic cues and overfit to frequent answer distributions, thereby diminishing the effective utilization of the 3D encoder. To address these limitations and encourage genuine 3D scene understanding, we introduce a novel 3D Relevance Discrimination QA dataset designed to disrupt shortcut learning and improve 3D understanding. Our findings highlight the need for advanced evaluation and improved strategies for better 3D understanding in 3D VLMs.