 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Multiplex Spatial-Temporal Transition Graph Representation Learning for Socially Enhanced POI Recommendation
Aug 11, 2025Next Point-of-Interest (POI) recommendation is a research hotspot in business intelligence, where users' spatial-temporal transitions and social relationships play key roles. However, most existing works model spatial and temporal transitions separately, leading to misaligned representations of the same spatial-temporal key nodes. This misalignment introduces redundant information during fusion, increasing model uncertainty and reducing interpretability. To address this issue, we propose DiMuST, a socially enhanced POI recommendation model based on disentangled representation learning over multiplex spatial-temporal transition graphs. The model employs a novel Disentangled variational multiplex graph Auto-Encoder (DAE), which first disentangles shared and private distributions using a multiplex spatial-temporal graph strategy. It then fuses the shared features via a Product of Experts (PoE) mechanism and denoises the private features through contrastive constraints. The model effectively captures the spatial-temporal transition representations of POIs while preserving the intrinsic correlation of their spatial-temporal relationships. Experiments on two challenging datasets demonstrate that our DiMuST significantly outperforms existing methods across multiple metrics.
DuCos: Duality Constrained Depth Super-Resolution via Foundation Model
Mar 06, 2025We introduce DuCos, a novel depth super-resolution framework grounded in Lagrangian duality theory, offering a flexible integration of multiple constraints and reconstruction objectives to enhance accuracy and robustness. Our DuCos is the first to significantly improve generalization across diverse scenarios with foundation models as prompts. The prompt design consists of two key components: Correlative Fusion (CF) and Gradient Regulation (GR). CF facilitates precise geometric alignment and effective fusion between prompt and depth features, while GR refines depth predictions by enforcing consistency with sharp-edged depth maps derived from foundation models. Crucially, these prompts are seamlessly embedded into the Lagrangian constraint term, forming a synergistic and principled framework. Extensive experiments demonstrate that DuCos outperforms existing state-of-the-art methods, achieving superior accuracy, robustness, and generalization. The source codes and pre-trained models will be publicly available.
CLIP-GS: Unifying Vision-Language Representation with 3D Gaussian Splatting
Dec 26, 2024



Recent works in 3D multimodal learning have made remarkable progress. However, typically 3D multimodal models are only capable of handling point clouds. Compared to the emerging 3D representation technique, 3D Gaussian Splatting (3DGS), the spatially sparse point cloud cannot depict the texture information of 3D objects, resulting in inferior reconstruction capabilities. This limitation constrains the potential of point cloud-based 3D multimodal representation learning. In this paper, we present CLIP-GS, a novel multimodal representation learning framework grounded in 3DGS. We introduce the GS Tokenizer to generate serialized gaussian tokens, which are then processed through transformer layers pre-initialized with weights from point cloud models, resulting in the 3DGS embeddings. CLIP-GS leverages contrastive loss between 3DGS and the visual-text embeddings of CLIP, and we introduce an image voting loss to guide the directionality and convergence of gradient optimization. Furthermore, we develop an efficient way to generate triplets of 3DGS, images, and text, facilitating CLIP-GS in learning unified multimodal representations. Leveraging the well-aligned multimodal representations, CLIP-GS demonstrates versatility and outperforms point cloud-based models on various 3D tasks, including multimodal retrieval, zero-shot, and few-shot classification.
Learnable Infinite Taylor Gaussian for Dynamic View Rendering
Dec 05, 2024



Capturing the temporal evolution of Gaussian properties such as position, rotation, and scale is a challenging task due to the vast number of time-varying parameters and the limited photometric data available, which generally results in convergence issues, making it difficult to find an optimal solution. While feeding all inputs into an end-to-end neural network can effectively model complex temporal dynamics, this approach lacks explicit supervision and struggles to generate high-quality transformation fields. On the other hand, using time-conditioned polynomial functions to model Gaussian trajectories and orientations provides a more explicit and interpretable solution, but requires significant handcrafted effort and lacks generalizability across diverse scenes. To overcome these limitations, this paper introduces a novel approach based on a learnable infinite Taylor Formula to model the temporal evolution of Gaussians. This method offers both the flexibility of an implicit network-based approach and the interpretability of explicit polynomial functions, allowing for more robust and generalizable modeling of Gaussian dynamics across various dynamic scenes. Extensive experiments on dynamic novel view rendering tasks are conducted on public datasets, demonstrating that the proposed method achieves state-of-the-art performance in this domain. More information is available on our project page(https://ellisonking.github.io/TaylorGaussian).
Human-VDM: Learning Single-Image 3D Human Gaussian Splatting from Video Diffusion Models
Sep 04, 2024


Generating lifelike 3D humans from a single RGB image remains a challenging task in computer vision, as it requires accurate modeling of geometry, high-quality texture, and plausible unseen parts. Existing methods typically use multi-view diffusion models for 3D generation, but they often face inconsistent view issues, which hinder high-quality 3D human generation. To address this, we propose Human-VDM, a novel method for generating 3D human from a single RGB image using Video Diffusion Models. Human-VDM provides temporally consistent views for 3D human generation using Gaussian Splatting. It consists of three modules: a view-consistent human video diffusion module, a video augmentation module, and a Gaussian Splatting module. First, a single image is fed into a human video diffusion module to generate a coherent human video. Next, the video augmentation module applies super-resolution and video interpolation to enhance the textures and geometric smoothness of the generated video. Finally, the 3D Human Gaussian Splatting module learns lifelike humans under the guidance of these high-resolution and view-consistent images. Experiments demonstrate that Human-VDM achieves high-quality 3D human from a single image, outperforming state-of-the-art methods in both generation quality and quantity. Project page: https://human-vdm.github.io/Human-VDM/
DreamVTON: Customizing 3D Virtual Try-on with Personalized Diffusion Models
Jul 23, 2024



Image-based 3D Virtual Try-ON (VTON) aims to sculpt the 3D human according to person and clothes images, which is data-efficient (i.e., getting rid of expensive 3D data) but challenging. Recent text-to-3D methods achieve remarkable improvement in high-fidelity 3D human generation, demonstrating its potential for 3D virtual try-on. Inspired by the impressive success of personalized diffusion models (e.g., Dreambooth and LoRA) for 2D VTON, it is straightforward to achieve 3D VTON by integrating the personalization technique into the diffusion-based text-to-3D framework. However, employing the personalized module in a pre-trained diffusion model (e.g., StableDiffusion (SD)) would degrade the model's capability for multi-view or multi-domain synthesis, which is detrimental to the geometry and texture optimization guided by Score Distillation Sampling (SDS) loss. In this work, we propose a novel customizing 3D human try-on model, named \textbf{DreamVTON}, to separately optimize the geometry and texture of the 3D human. Specifically, a personalized SD with multi-concept LoRA is proposed to provide the generative prior about the specific person and clothes, while a Densepose-guided ControlNet is exploited to guarantee consistent prior about body pose across various camera views. Besides, to avoid the inconsistent multi-view priors from the personalized SD dominating the optimization, DreamVTON introduces a template-based optimization mechanism, which employs mask templates for geometry shape learning and normal/RGB templates for geometry/texture details learning. Furthermore, for the geometry optimization phase, DreamVTON integrates a normal-style LoRA into personalized SD to enhance normal map generative prior, facilitating smooth geometry modeling.
Generalizable Human Gaussians for Sparse View Synthesis
Jul 17, 2024



Recent progress in neural rendering has brought forth pioneering methods, such as NeRF and Gaussian Splatting, which revolutionize view rendering across various domains like AR/VR, gaming, and content creation. While these methods excel at interpolating {\em within the training data}, the challenge of generalizing to new scenes and objects from very sparse views persists. Specifically, modeling 3D humans from sparse views presents formidable hurdles due to the inherent complexity of human geometry, resulting in inaccurate reconstructions of geometry and textures. To tackle this challenge, this paper leverages recent advancements in Gaussian Splatting and introduces a new method to learn generalizable human Gaussians that allows photorealistic and accurate view-rendering of a new human subject from a limited set of sparse views in a feed-forward manner. A pivotal innovation of our approach involves reformulating the learning of 3D Gaussian parameters into a regression process defined on the 2D UV space of a human template, which allows leveraging the strong geometry prior and the advantages of 2D convolutions. In addition, a multi-scaffold is proposed to effectively represent the offset details. Our method outperforms recent methods on both within-dataset generalization as well as cross-dataset generalization settings.
Hamba: Single-view 3D Hand Reconstruction with Graph-guided Bi-Scanning Mamba
Jul 12, 2024
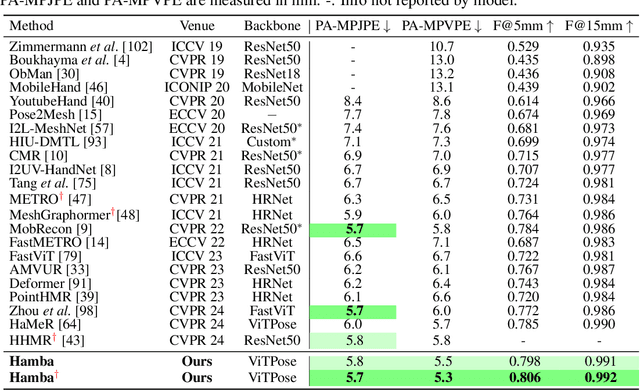
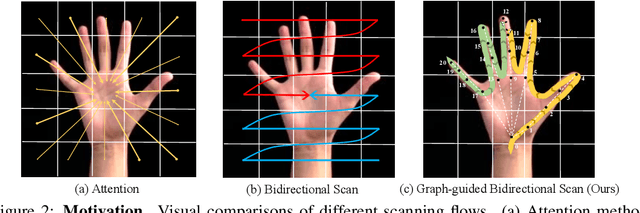
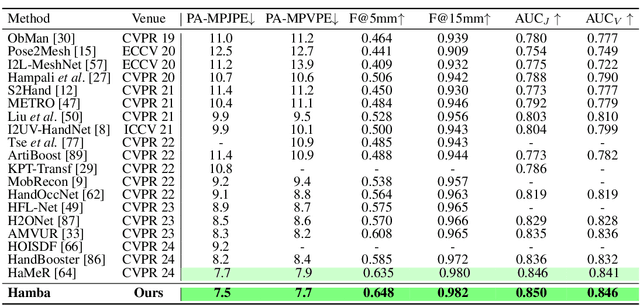
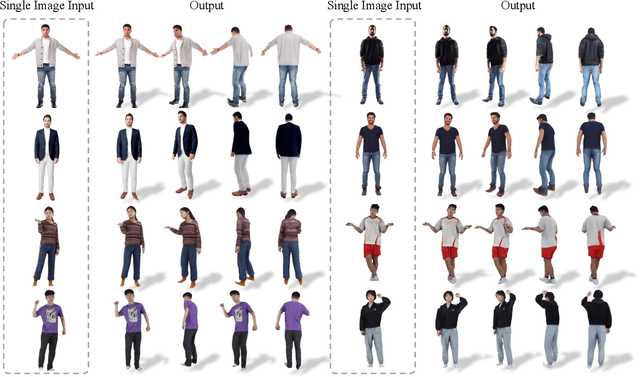
3D Hand reconstruction from a single RGB image is challenging due to the articulated motion, self-occlusion, and interaction with objects. Existing SOTA methods employ attention-based transformers to learn the 3D hand pose and shape, but they fail to achieve robust and accurate performance due to insufficient modeling of joint spatial relations. To address this problem, we propose a novel graph-guided Mamba framework, named Hamba, which bridges graph learning and state space modeling. Our core idea is to reformulate Mamba's scanning into graph-guided bidirectional scanning for 3D reconstruction using a few effective tokens. This enables us to learn the joint relations and spatial sequences for enhancing the reconstruction performance. Specifically, we design a novel Graph-guided State Space (GSS) block that learns the graph-structured relations and spatial sequences of joints and uses 88.5% fewer tokens than attention-based methods. Additionally, we integrate the state space features and the global features using a fusion module. By utilizing the GSS block and the fusion module, Hamba effectively leverages the graph-guided state space modeling features and jointly considers global and local features to improve performance. Extensive experiments on several benchmarks and in-the-wild tests demonstrate that Hamba significantly outperforms existing SOTAs, achieving the PA-MPVPE of 5.3mm and F@15mm of 0.992 on FreiHAND. Hamba is currently Rank 1 in two challenging competition leaderboards on 3D hand reconstruction. The code will be available upon acceptance. [Website](https://humansensinglab.github.io/Hamba/).
Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Mar 16, 2024Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
WarpDiffusion: Efficient Diffusion Model for High-Fidelity Virtual Try-on
Dec 06, 2023



Image-based Virtual Try-On (VITON) aims to transfer an in-shop garment image onto a target person. While existing methods focus on warping the garment to fit the body pose, they often overlook the synthesis quality around the garment-skin boundary and realistic effects like wrinkles and shadows on the warped garments. These limitations greatly reduce the realism of the generated results and hinder the practical application of VITON techniques. Leveraging the notable success of diffusion-based models in cross-modal image synthesis, some recent diffusion-based methods have ventured to tackle this issue. However, they tend to either consume a significant amount of training resources or struggle to achieve realistic try-on effects and retain garment details. For efficient and high-fidelity VITON, we propose WarpDiffusion, which bridges the warping-based and diffusion-based paradigms via a novel informative and local garment feature attention mechanism. Specifically, WarpDiffusion incorporates local texture attention to reduce resource consumption and uses a novel auto-mask module that effectively retains only the critical areas of the warped garment while disregarding unrealistic or erroneous portions. Notably, WarpDiffusion can be integrated as a plug-and-play component into existing VITON methodologies, elevating their synthesis quality. Extensive experiments on high-resolution VITON benchmarks and an in-the-wild test set demonstrate the superiority of WarpDiffusion, surpassing state-of-the-art methods both qualitatively and quantitatively.