 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECCV 2024 W-CODA: 1st Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
Jul 02, 2025
In this paper, we present details of the 1st W-CODA workshop, held in conjunction with the ECCV 2024. W-CODA aims to explore next-generation solutions for autonomous driving corner cases, empowered by state-of-the-art multimodal perception and comprehension techniques. 5 Speakers from both academia and industry are invited to share their latest progress and opinions. We collect research papers and hold a dual-track challenge, including both corner case scene understanding and generation. As the pioneering effort, we will continuously bridge the gap between frontier autonomous driving techniques and fully intelligent, reliable self-driving agents robust towards corner cases.
BLOS-BEV: Navigation Map Enhanced Lane Segmentation Network, Beyond Line of Sight
Jul 11, 2024



Bird's-eye-view (BEV) representation is crucial for the perception function in autonomous driving tasks. It is difficult to balance the accuracy, efficiency and range of BEV representation. The existing works are restricted to a limited perception range within 50 meters. Extending the BEV representation range can greatly benefit downstream tasks such as topology reasoning, scene understanding, and planning by offering more comprehensive information and reaction time. The Standard-Definition (SD) navigation maps can provide a lightweight representation of road structure topology, characterized by ease of acquisition and low maintenance costs. An intuitive idea is to combine the close-range visual information from onboard cameras with the beyond line-of-sight (BLOS) environmental priors from SD maps to realize expanded perceptual capabilities. In this paper, we propose BLOS-BEV, a novel BEV segmentation model that incorporates SD maps for accurate beyond line-of-sight perception, up to 200m. Our approach is applicable to common BEV architectures and can achieve excellent results by incorporating information derived from SD maps. We explore various feature fusion schemes to effectively integrate the visual BEV representations and semantic features from the SD map, aiming to leverage the complementary information from both sources optimally. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in BEV segmentation on nuScenes and Argoverse benchmark. Through multi-modal inputs, BEV segmentation is significantly enhanced at close ranges below 50m, while also demonstrating superior performance in long-range scenarios, surpassing other methods by over 20% mIoU at distances ranging from 50-200m.
Open-sourced Data Ecosystem in Autonomous Driving: the Present and Future
Dec 06, 2023



With the continuous maturation and application of autonomous driving technology, a systematic examination of open-source autonomous driving datasets becomes instrumental in fostering the robust evolution of the industry ecosystem. Current autonomous driving datasets can broadly be categorized into two generations. The first-generation autonomous driving datasets are characterized by relatively simpler sensor modalities, smaller data scale, and is limited to perception-level tasks. KITTI, introduced in 2012, serves as a prominent representative of this initial wave. In contrast, the second-generation datasets exhibit heightened complexity in sensor modalities, greater data scale and diversity, and an expansion of tasks from perception to encompass prediction and control. Leading examples of the second generation include nuScenes and Waymo, introduced around 2019. This comprehensive review, conducted in collaboration with esteemed colleagues from both academia and industry, systematically assesses over seventy open-source autonomous driving datasets from domestic and international sources. It offers insights into various aspects, such as the principles underlying the creation of high-quality datasets, the pivotal role of data engine systems, and the utilization of generative foundation models to facilitate scalable data generation. Furthermore, this review undertakes an exhaustive analysis and discourse regarding the characteristics and data scales that future third-generation autonomous driving datasets should possess. It also delves into the scientific and technical challenges that warrant resolution. These endeavors are pivotal in advancing autonomous innovation and fostering technological enhancement in critical domains. For further details, please refer to https://github.com/OpenDriveLab/DriveAGI.
FlowMap: Path Generation for Automated Vehicles in Open Space Using Traffic Flow
May 11, 2023



There is extensive literature on perceiving road structures by fusing various sensor inputs such as lidar point clouds and camera images using deep neural nets. Leveraging the latest advance of neural architects (such as transformers) and bird-eye-view (BEV) representation, the road cognition accuracy keeps improving. However, how to cognize the ``road'' for automated vehicles where there is no well-defined ``roads'' remains an open problem. For example, how to find paths inside intersections without HD maps is hard since there is neither an explicit definition for ``roads'' nor explicit features such as lane markings. The idea of this paper comes from a proverb: it becomes a way when people walk on it. Although there are no ``roads'' from sensor readings, there are ``roads'' from tracks of other vehicles. In this paper, we propose FlowMap, a path generation framework for automated vehicles based on traffic flows. FlowMap is built by extending our previous work RoadMap, a light-weight semantic map, with an additional traffic flow layer. A path generation algorithm on traffic flow fields (TFFs) is proposed to generate human-like paths. The proposed framework is validated using real-world driving data and is amenable to generating paths for super complicated intersections without using HD maps.
Topology Reasoning for Driving Scenes
Apr 11, 2023Understanding the road genome is essential to realize autonomous driving. This highly intelligent problem contains two aspects - the connection relationship of lanes, and the assignment relationship between lanes and traffic elements, where a comprehensive topology reasoning method is vacant. On one hand, previous map learning techniques struggle in deriving lane connectivity with segmentation or laneline paradigms; or prior lane topology-oriented approaches focus on centerline detection and neglect the interaction modeling. On the other hand, the traffic element to lane assignment problem is limited in the image domain, leaving how to construct the correspondence from two views an unexplored challenge. To address these issues, we present TopoNet, the first end-to-end framework capable of abstracting traffic knowledge beyond conventional perception tasks. To capture the driving scene topology, we introduce three key designs: (1) an embedding module to incorporate semantic knowledge from 2D elements into a unified feature space; (2) a curated scene graph neural network to model relationships and enable feature interaction inside the network; (3) instead of transmitting messages arbitrarily, a scene knowledge graph is devised to differentiate prior knowledge from various types of the road genome. We evaluate TopoNet on the challenging scene understanding benchmark, OpenLane-V2, where our approach outperforms all previous works by a great margin on all perceptual and topological metrics. The code would be released soon.
Visual Exemplar Driven Task-Prompting for Unified Perception in Autonomous Driving
Mar 03, 2023Multi-task learning has emerged as a powerful paradigm to solve a range of tasks simultaneously with good efficiency in both computation resources and inference time. However, these algorithms are designed for different tasks mostly not within the scope of autonomous driving, thus making it hard to compare multi-task methods in autonomous driving. Aiming to enable the comprehensive evaluation of present multi-task learning methods in autonomous driving, we extensively investigate the performance of popular multi-task methods on the large-scale driving dataset, which covers four common perception tasks, i.e., object detection, semantic segmentation, drivable area segmentation, and lane detection. We provide an in-depth analysis of current multi-task learning methods under different common settings and find out that the existing methods make progress but there is still a large performance gap compared with single-task baselines. To alleviate this dilemma in autonomous driving, we present an effective multi-task framework, VE-Prompt, which introduces visual exemplars via task-specific prompting to guide the model toward learning high-quality task-specific representations. Specifically, we generate visual exemplars based on bounding boxes and color-based markers, which provide accurate visual appearances of target categories and further mitigate the performance gap. Furthermore, we bridge transformer-based encoders and convolutional layers for efficient and accurate unified perception in autonomous driving. Comprehensive experimental results on the diverse self-driving dataset BDD100K show that the VE-Prompt improves the multi-task baseline and further surpasses single-task models.
NLIP: Noise-robust Language-Image Pre-training
Jan 04, 2023



Large-scale cross-modal pre-training paradigms have recently shown ubiquitous success on a wide range of downstream tasks, e.g., zero-shot classification, retrieval and image captioning. However, their successes highly rely on the scale and quality of web-crawled data that naturally contain incomplete and noisy information (e.g., wrong or irrelevant content). Existing works either design manual rules to clean data or generate pseudo-targets as auxiliary signals for reducing noise impact, which do not explicitly tackle both the incorrect and incomplete challenges simultaneously. In this paper, to automatically mitigate the impact of noise by solely mining over existing data, we propose a principled Noise-robust Language-Image Pre-training framework (NLIP) to stabilize pre-training via two schemes: noise-harmonization and noise-completion. First, in noise-harmonization scheme, NLIP estimates the noise probability of each pair according to the memorization effect of cross-modal transformers, then adopts noise-adaptive regularization to harmonize the cross-modal alignments with varying degrees. Second, in noise-completion scheme, to enrich the missing object information of text, NLIP injects a concept-conditioned cross-modal decoder to obtain semantic-consistent synthetic captions to complete noisy ones, which uses the retrieved visual concepts (i.e., objects' names) for the corresponding image to guide captioning generation. By collaboratively optimizing noise-harmonization and noise-completion schemes, our NLIP can alleviate the common noise effects during image-text pre-training in a more efficient way. Extensive experiments show the significant performance improvements of our NLIP using only 26M data over existing pre-trained models (e.g., CLIP, FILIP and BLIP) on 12 zero-shot classification datasets, MSCOCO image captioning and zero-shot image-text retrieval tasks.
P$^3$OVD: Fine-grained Visual-Text Prompt-Driven Self-Training for Open-Vocabulary Object Detection
Nov 02, 2022Inspired by the success of visual-language methods (VLMs) in zero-shot classification, recent works attempt to extend this line of work into object detection by leveraging the localization ability of pre-trained VLMs and generating pseudo labels for unseen classes in a self-training manner. However, since the current VLMs are usually pre-trained with aligning sentence embedding with global image embedding, the direct use of them lacks fine-grained alignment for object instances, which is the core of detection. In this paper, we propose a simple but effective Pretrain-adaPt-Pseudo labeling paradigm for Open-Vocabulary Detection (P$^3$OVD) that introduces a fine-grained visual-text prompt adapting stage to enhance the current self-training paradigm with a more powerful fine-grained alignment. During the adapting stage, we enable VLM to obtain fine-grained alignment by using learnable text prompts to resolve an auxiliary dense pixel-wise prediction task. Furthermore, we propose a visual prompt module to provide the prior task information (i.e., the categories need to be predicted) for the vision branch to better adapt the pretrained VLM to the downstream tasks. Experiments show that our method achieves the state-of-the-art performance for open-vocabulary object detection, e.g., 31.5% mAP on unseen classes of COCO.
DetCLIP: Dictionary-Enriched Visual-Concept Paralleled Pre-training for Open-world Detection
Sep 20, 2022

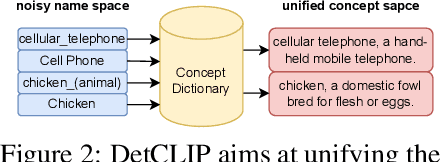

Open-world object detection, as a more general and challenging goal, aims to recognize and localize objects described by arbitrary category names. The recent work GLIP formulates this problem as a grounding problem by concatenating all category names of detection datasets into sentences, which leads to inefficient interaction between category names. This paper presents DetCLIP, a paralleled visual-concept pre-training method for open-world detection by resorting to knowledge enrichment from a designed concept dictionary. To achieve better learning efficiency, we propose a novel paralleled concept formulation that extracts concepts separately to better utilize heterogeneous datasets (i.e., detection, grounding, and image-text pairs) for training. We further design a concept dictionary~(with descriptions) from various online sources and detection datasets to provide prior knowledge for each concept. By enriching the concepts with their descriptions, we explicitly build the relationships among various concepts to facilitate the open-domain learning. The proposed concept dictionary is further used to provide sufficient negative concepts for the construction of the word-region alignment loss\, and to complete labels for objects with missing descriptions in captions of image-text pair data. The proposed framework demonstrates strong zero-shot detection performances, e.g., on the LVIS dataset, our DetCLIP-T outperforms GLIP-T by 9.9% mAP and obtains a 13.5% improvement on rare categories compared to the fully-supervised model with the same backbone as ours.
Effective Adaptation in Multi-Task Co-Training for Unified Autonomous Driving
Sep 19, 2022
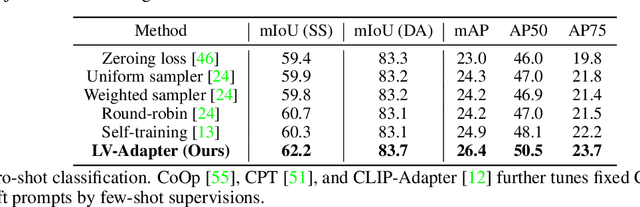
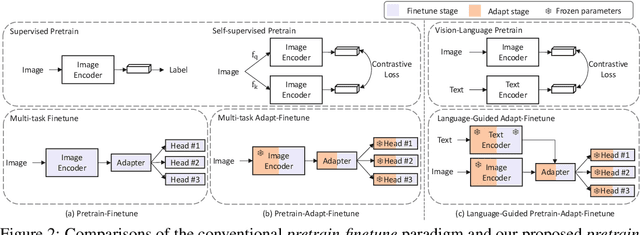
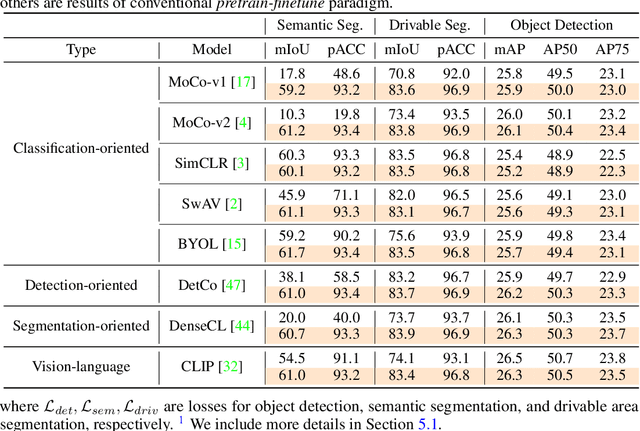
Aiming towards a holistic understanding of multiple downstream tasks simultaneously, there is a need for extracting features with better transferability. Though many latest self-supervised pre-training methods have achieved impressive performance on various vision tasks under the prevailing pretrain-finetune paradigm, their generalization capacity to multi-task learning scenarios is yet to be explored. In this paper, we extensively investigate the transfer performance of various types of self-supervised methods, e.g., MoCo and SimCLR, on three downstream tasks, including semantic segmentation, drivable area segmentation, and traffic object detection, on the large-scale driving dataset BDD100K. We surprisingly find that their performances are sub-optimal or even lag far behind the single-task baseline, which may be due to the distinctions of training objectives and architectural design lied in the pretrain-finetune paradigm. To overcome this dilemma as well as avoid redesigning the resource-intensive pre-training stage, we propose a simple yet effective pretrain-adapt-finetune paradigm for general multi-task training, where the off-the-shelf pretrained models can be effectively adapted without increasing the training overhead. During the adapt stage, we utilize learnable multi-scale adapters to dynamically adjust the pretrained model weights supervised by multi-task objectives while leaving the pretrained knowledge untouched. Furthermore, we regard the vision-language pre-training model CLIP as a strong complement to the pretrain-adapt-finetune paradigm and propose a novel adapter named LV-Adapter, which incorporates language priors in the multi-task model via task-specific prompting and alignment between visual and textual features.