 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeScale: Scaling 3D Scenes via Certainty-Aware Free-View Generation
Apr 12, 2026The development of generalizable Novel View Synthesis (NVS) models is critically limited by the scarcity of large-scale training data featuring diverse and precise camera trajectories. While real-world captures are photorealistic, they are typically sparse and discrete. Conversely, synthetic data scales but suffers from a domain gap and often lacks realistic semantics. We introduce FreeScale, a novel framework that leverages the power of scene reconstruction to transform limited real-world image sequences into a scalable source of high-quality training data. Our key insight is that an imperfect reconstructed scene serves as a rich geometric proxy, but naively sampling from it amplifies artifacts. To this end, we propose a certainty-aware free-view sampling strategy identifying novel viewpoints that are both semantically meaningful and minimally affected by reconstruction errors. We demonstrate FreeScale's effectiveness by scaling up the training of feedforward NVS models, achieving a notable gain of 2.7 dB in PSNR on challenging out-of-distribution benchmarks. Furthermore, we show that the generated data can actively enhance per-scene 3D Gaussian Splatting optimization, leading to consistent improvements across multiple datasets. Our work provides a practical and powerful data generation engine to overcome a fundamental bottleneck in 3D vision. Project page: https://mvp-ai-lab.github.io/FreeScale.
SynFlow: Scaling Up LiDAR Scene Flow Estimation with Synthetic Data
Apr 10, 2026Reliable 3D dynamic perception requires models that can anticipate motion beyond predefined categories, yet progress is hindered by the scarcity of dense, high-quality motion annotations. While self-supervision on unlabeled real data offers a path forward, empirical evidence suggests that scaling unlabeled data fails to close the performance gap due to noisy proxy signals. In this paper, we propose a shift in paradigm: learning robust real-world motion priors entirely from scalable simulation. We introduce SynFlow, a data generation pipeline that generates large-scale synthetic dataset specifically designed for LiDAR scene flow. Unlike prior works that prioritize sensor-specific realism, SynFlow employs a motion-oriented strategy to synthesize diverse kinematic patterns across 4,000 sequences ($\sim$940k frames), termed SynFlow-4k. This represents a 34x scale-up in annotated volume over existing real-world benchmarks. Our experiments demonstrate that SynFlow-4k provides a highly domain-invariant motion prior. In a zero-shot regime, models trained exclusively on our synthetic data generalize across multiple real-world benchmarks, rivaling in-domain supervised baselines on nuScenes and outperforming state-of-the-art methods on TruckScenes by 31.8%. Furthermore, SynFlow-4k serves as a label-efficient foundation: fine-tuning with only 5% of real-world labels surpasses models trained from scratch on the full available budget. We open-source the pipeline and dataset to facilitate research in generalizable 3D motion estimation. More detail can be found at https://kin-zhang.github.io/SynFlow.
TeFlow: Enabling Multi-frame Supervision for Self-Supervised Feed-forward Scene Flow Estimation
Feb 22, 2026Self-supervised feed-forward methods for scene flow estimation offer real-time efficiency, but their supervision from two-frame point correspondences is unreliable and often breaks down under occlusions. Multi-frame supervision has the potential to provide more stable guidance by incorporating motion cues from past frames, yet naive extensions of two-frame objectives are ineffective because point correspondences vary abruptly across frames, producing inconsistent signals. In the paper, we present TeFlow, enabling multi-frame supervision for feed-forward models by mining temporally consistent supervision. TeFlow introduces a temporal ensembling strategy that forms reliable supervisory signals by aggregating the most temporally consistent motion cues from a candidate pool built across multiple frames. Extensive evaluations demonstrate that TeFlow establishes a new state-of-the-art for self-supervised feed-forward methods, achieving performance gains of up to 33\% on the challenging Argoverse 2 and nuScenes datasets. Our method performs on par with leading optimization-based methods, yet speeds up 150 times. The code is open-sourced at https://github.com/KTH-RPL/OpenSceneFlow along with trained model weights.
CoherenDream: Boosting Holistic Text Coherence in 3D Generation via Multimodal Large Language Models Feedback
Apr 28, 2025



Score Distillation Sampling (SDS) has achieved remarkable success in text-to-3D content generation. However, SDS-based methods struggle to maintain semantic fidelity for user prompts, particularly when involving multiple objects with intricate interactions. While existing approaches often address 3D consistency through multiview diffusion model fine-tuning on 3D datasets, this strategy inadvertently exacerbates text-3D alignment degradation. The limitation stems from SDS's inherent accumulation of view-independent biases during optimization, which progressively diverges from the ideal text alignment direction. To alleviate this limitation, we propose a novel SDS objective, dubbed as Textual Coherent Score Distillation (TCSD), which integrates alignment feedback from multimodal large language models (MLLMs). Our TCSD leverages cross-modal understanding capabilities of MLLMs to assess and guide the text-3D correspondence during the optimization. We further develop 3DLLaVA-CRITIC - a fine-tuned MLLM specialized for evaluating multiview text alignment in 3D generations. Additionally, we introduce an LLM-layout initialization that significantly accelerates optimization convergence through semantic-aware spatial configuration. Comprehensive evaluations demonstrate that our framework, CoherenDream, establishes state-of-the-art performance in text-aligned 3D generation across multiple benchmarks, including T$^3$Bench and TIFA subset. Qualitative results showcase the superior performance of CoherenDream in preserving textual consistency and semantic interactions. As the first study to incorporate MLLMs into SDS optimization, we also conduct extensive ablation studies to explore optimal MLLM adaptations for 3D generation tasks.
JointDreamer: Ensuring Geometry Consistency and Text Congruence in Text-to-3D Generation via Joint Score Distillation
Jul 17, 2024



Score Distillation Sampling (SDS) by well-trained 2D diffusion models has shown great promise in text-to-3D generation. However, this paradigm distills view-agnostic 2D image distributions into the rendering distribution of 3D representation for each view independently, overlooking the coherence across views and yielding 3D inconsistency in generations. In this work, we propose \textbf{J}oint \textbf{S}core \textbf{D}istillation (JSD), a new paradigm that ensures coherent 3D generations. Specifically, we model the joint image distribution, which introduces an energy function to capture the coherence among denoised images from the diffusion model. We then derive the joint score distillation on multiple rendered views of the 3D representation, as opposed to a single view in SDS. In addition, we instantiate three universal view-aware models as energy functions, demonstrating compatibility with JSD. Empirically, JSD significantly mitigates the 3D inconsistency problem in SDS, while maintaining text congruence. Moreover, we introduce the Geometry Fading scheme and Classifier-Free Guidance (CFG) Switching strategy to enhance generative details. Our framework, JointDreamer, establishes a new benchmark in text-to-3D generation, achieving outstanding results with an 88.5\% CLIP R-Precision and 27.7\% CLIP Score. These metrics demonstrate exceptional text congruence, as well as remarkable geometric consistency and texture fidelity.
A Survey On Text-to-3D Contents Generation In The Wild
May 15, 2024



3D content creation plays a vital role in various applications, such as gaming, robotics simulation, and virtual reality. However, the process is labor-intensive and time-consuming, requiring skilled designers to invest considerable effort in creating a single 3D asset. To address this challenge, text-to-3D generation technologies have emerged as a promising solution for automating 3D creation. Leveraging the success of large vision language models, these techniques aim to generate 3D content based on textual descriptions. Despite recent advancements in this area, existing solutions still face significant limitations in terms of generation quality and efficiency. In this survey, we conduct an in-depth investigation of the latest text-to-3D creation methods. We provide a comprehensive background on text-to-3D creation, including discussions on datasets employed in training and evaluation metrics used to assess the quality of generated 3D models. Then, we delve into the various 3D representations that serve as the foundation for the 3D generation process. Furthermore, we present a thorough comparison of the rapidly growing literature on generative pipelines, categorizing them into feedforward generators, optimization-based generation, and view reconstruction approaches. By examining the strengths and weaknesses of these methods, we aim to shed light on their respective capabilities and limitations. Lastly, we point out several promising avenues for future research. With this survey, we hope to inspire researchers further to explore the potential of open-vocabulary text-conditioned 3D content creation.
CLIP$^2$: Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data
Mar 26, 2023



Contrastive Language-Image Pre-training, benefiting from large-scale unlabeled text-image pairs, has demonstrated great performance in open-world vision understanding tasks. However, due to the limited Text-3D data pairs, adapting the success of 2D Vision-Language Models (VLM) to the 3D space remains an open problem. Existing works that leverage VLM for 3D understanding generally resort to constructing intermediate 2D representations for the 3D data, but at the cost of losing 3D geometry information. To take a step toward open-world 3D vision understanding, we propose Contrastive Language-Image-Point Cloud Pretraining (CLIP$^2$) to directly learn the transferable 3D point cloud representation in realistic scenarios with a novel proxy alignment mechanism. Specifically, we exploit naturally-existed correspondences in 2D and 3D scenarios, and build well-aligned and instance-based text-image-point proxies from those complex scenarios. On top of that, we propose a cross-modal contrastive objective to learn semantic and instance-level aligned point cloud representation. Experimental results on both indoor and outdoor scenarios show that our learned 3D representation has great transfer ability in downstream tasks, including zero-shot and few-shot 3D recognition, which boosts the state-of-the-art methods by large margins. Furthermore, we provide analyses of the capability of different representations in real scenarios and present the optional ensemble scheme.
CO^3: Cooperative Unsupervised 3D Representation Learning for Autonomous Driving
Jun 08, 2022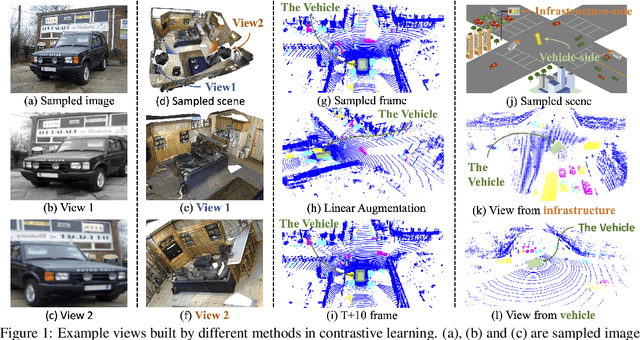
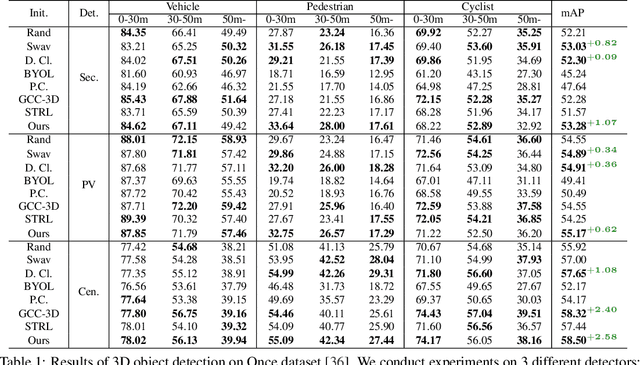
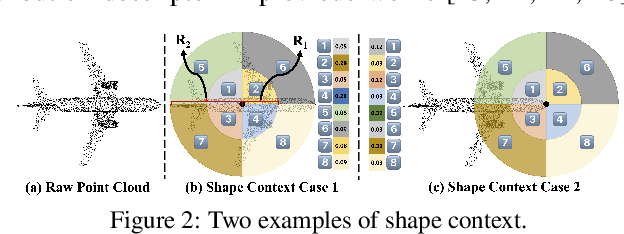
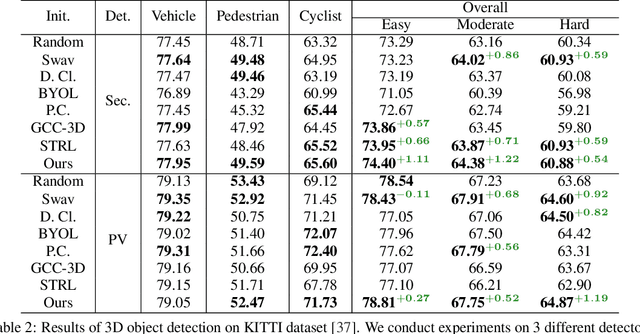
Unsupervised contrastive learning for indoor-scene point clouds has achieved great successes. However, unsupervised learning point clouds in outdoor scenes remains challenging because previous methods need to reconstruct the whole scene and capture partial views for the contrastive objective. This is infeasible in outdoor scenes with moving objects, obstacles, and sensors. In this paper, we propose CO^3, namely Cooperative Contrastive Learning and Contextual Shape Prediction, to learn 3D representation for outdoor-scene point clouds in an unsupervised manner. CO^3 has several merits compared to existing methods. (1) It utilizes LiDAR point clouds from vehicle-side and infrastructure-side to build views that differ enough but meanwhile maintain common semantic information for contrastive learning, which are more appropriate than views built by previous methods. (2) Alongside the contrastive objective, shape context prediction is proposed as pre-training goal and brings more task-relevant information for unsupervised 3D point cloud representation learning, which are beneficial when transferring the learned representation to downstream detection tasks. (3) As compared to previous methods, representation learned by CO^3 is able to be transferred to different outdoor scene dataset collected by different type of LiDAR sensors. (4) CO^3 improves current state-of-the-art methods on both Once and KITTI datasets by up to 2.58 mAP. Codes and models will be released. We believe CO^3 will facilitate understanding LiDAR point clouds in outdoor scene.
One Million Scenes for Autonomous Driving: ONCE Dataset
Jun 21, 2021
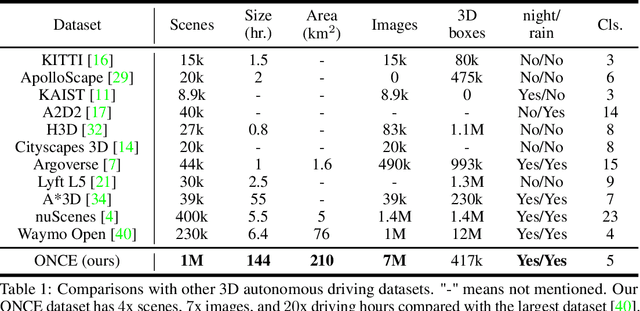

Current perception models in autonomous driving have become notorious for greatly relying on a mass of annotated data to cover unseen cases and address the long-tail problem. On the other hand, learning from unlabeled large-scale collected data and incrementally self-training powerful recognition models have received increasing attention and may become the solutions of next-generation industry-level powerful and robust perception models in autonomous driving. However, the research community generally suffered from data inadequacy of those essential real-world scene data, which hampers the future exploration of fully/semi/self-supervised methods for 3D perception. In this paper, we introduce the ONCE (One millioN sCenEs) dataset for 3D object detection in the autonomous driving scenario. The ONCE dataset consists of 1 million LiDAR scenes and 7 million corresponding camera images. The data is selected from 144 driving hours, which is 20x longer than the largest 3D autonomous driving dataset available (e.g. nuScenes and Waymo), and it is collected across a range of different areas, periods and weather conditions. To facilitate future research on exploiting unlabeled data for 3D detection, we additionally provide a benchmark in which we reproduce and evaluate a variety of self-supervised and semi-supervised methods on the ONCE dataset. We conduct extensive analyses on those methods and provide valuable observations on their performance related to the scale of used data. Data, code, and more information are available at https://once-for-auto-driving.github.io/index.html.
Unsupervised Pretraining for Object Detection by Patch Reidentification
Mar 08, 2021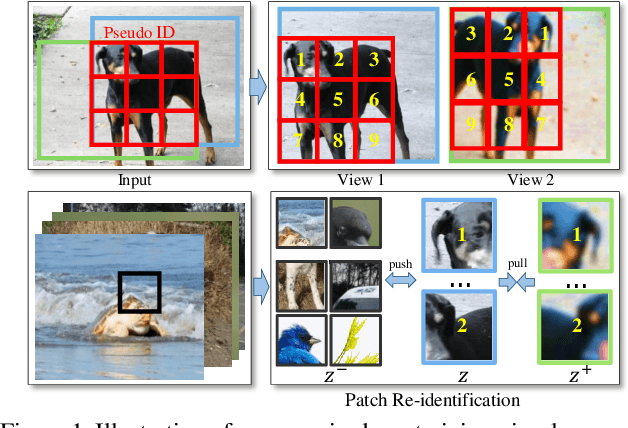
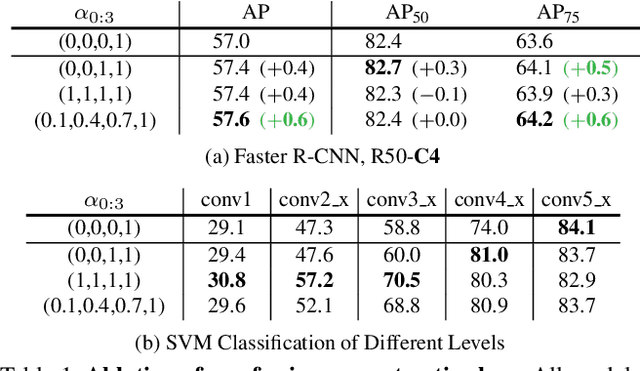
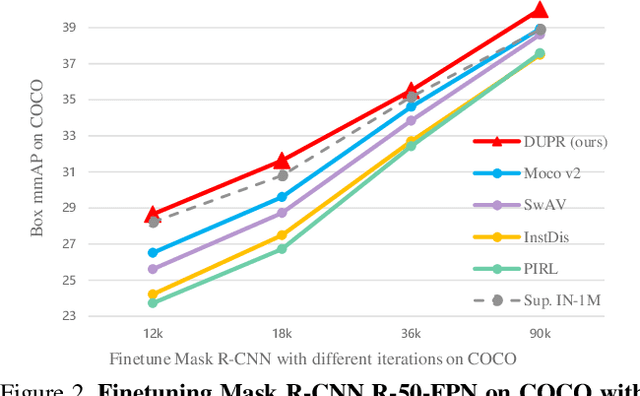
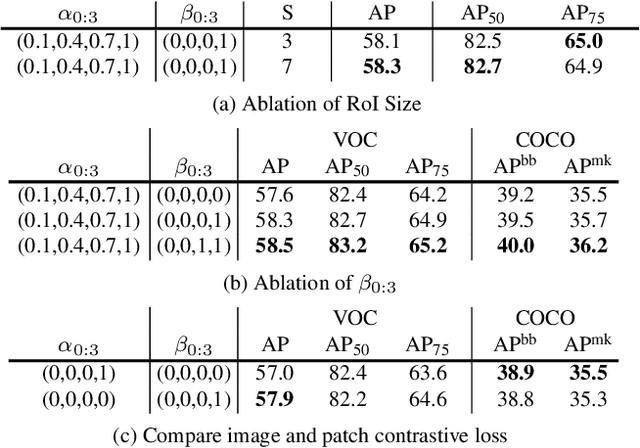
Unsupervised representation learning achieves promising performances in pre-training representations for object detectors. However, previous approaches are mainly designed for image-level classification, leading to suboptimal detection performance. To bridge the performance gap, this work proposes a simple yet effective representation learning method for object detection, named patch re-identification (Re-ID), which can be treated as a contrastive pretext task to learn location-discriminative representation unsupervisedly, possessing appealing advantages compared to its counterparts. Firstly, unlike fully-supervised person Re-ID that matches a human identity in different camera views, patch Re-ID treats an important patch as a pseudo identity and contrastively learns its correspondence in two different image views, where the pseudo identity has different translations and transformations, enabling to learn discriminative features for object detection. Secondly, patch Re-ID is performed in Deeply Unsupervised manner to learn multi-level representations, appealing to object detection. Thirdly, extensive experiments show that our method significantly outperforms its counterparts on COCO in all settings, such as different training iterations and data percentages. For example, Mask R-CNN initialized with our representation surpasses MoCo v2 and even its fully-supervised counterparts in all setups of training iterations (e.g. 2.1 and 1.1 mAP improvement compared to MoCo v2 in 12k and 90k iterations respectively). Code will be released at https://github.com/dingjiansw101/DUPR.