 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniWeaving: Towards Unified Video Generation with Free-form Composition and Reasoning
Mar 25, 2026While proprietary systems such as Seedance-2.0 have achieved remarkable success in omni-capable video generation, open-source alternatives significantly lag behind. Most academic models remain heavily fragmented, and the few existing efforts toward unified video generation still struggle to seamlessly integrate diverse tasks within a single framework. To bridge this gap, we propose OmniWeaving, an omni-level video generation model featuring powerful multimodal composition and reasoning-informed capabilities. By leveraging a massive-scale pretraining dataset that encompasses diverse compositional and reasoning-augmented scenarios, OmniWeaving learns to temporally bind interleaved text, multi-image, and video inputs while acting as an intelligent agent to infer complex user intentions for sophisticated video creation. Furthermore, we introduce IntelligentVBench, the first comprehensive benchmark designed to rigorously assess next-level intelligent unified video generation. Extensive experiments demonstrate that OmniWeaving achieves SoTA performance among open-source unified models. The codes and model will be made publicly available soon. Project Page: https://omniweaving.github.io.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation
Mar 13, 2024Text-to-image (T2I) generation models have significantly advanced in recent years. However, effective interaction with these models is challenging for average users due to the need for specialized prompt engineering knowledge and the inability to perform multi-turn image generation, hindering a dynamic and iterative creation process. Recent attempts have tried to equip Multi-modal Large Language Models (MLLMs) with T2I models to bring the user's natural language instructions into reality. Hence, the output modality of MLLMs is extended, and the multi-turn generation quality of T2I models is enhanced thanks to the strong multi-modal comprehension ability of MLLMs. However, many of these works face challenges in identifying correct output modalities and generating coherent images accordingly as the number of output modalities increases and the conversations go deeper. Therefore, we propose DialogGen, an effective pipeline to align off-the-shelf MLLMs and T2I models to build a Multi-modal Interactive Dialogue System (MIDS) for multi-turn Text-to-Image generation. It is composed of drawing prompt alignment, careful training data curation, and error correction. Moreover, as the field of MIDS flourishes, comprehensive benchmarks are urgently needed to evaluate MIDS fairly in terms of output modality correctness and multi-modal output coherence. To address this issue, we introduce the Multi-modal Dialogue Benchmark (DialogBen), a comprehensive bilingual benchmark designed to assess the ability of MLLMs to generate accurate and coherent multi-modal content that supports image editing. It contains two evaluation metrics to measure the model's ability to switch modalities and the coherence of the output images. Our extensive experiments on DialogBen and user study demonstrate the effectiveness of DialogGen compared with other State-of-the-Art models.
Towards Deviation-Robust Agent Navigation via Perturbation-Aware Contrastive Learning
Mar 09, 2024Vision-and-language navigation (VLN) asks an agent to follow a given language instruction to navigate through a real 3D environment. Despite significant advances, conventional VLN agents are trained typically under disturbance-free environments and may easily fail in real-world scenarios, since they are unaware of how to deal with various possible disturbances, such as sudden obstacles or human interruptions, which widely exist and may usually cause an unexpected route deviation. In this paper, we present a model-agnostic training paradigm, called Progressive Perturbation-aware Contrastive Learning (PROPER) to enhance the generalization ability of existing VLN agents, by requiring them to learn towards deviation-robust navigation. Specifically, a simple yet effective path perturbation scheme is introduced to implement the route deviation, with which the agent is required to still navigate successfully following the original instruction. Since directly enforcing the agent to learn perturbed trajectories may lead to inefficient training, a progressively perturbed trajectory augmentation strategy is designed, where the agent can self-adaptively learn to navigate under perturbation with the improvement of its navigation performance for each specific trajectory. For encouraging the agent to well capture the difference brought by perturbation, a perturbation-aware contrastive learning mechanism is further developed by contrasting perturbation-free trajectory encodings and perturbation-based counterparts. Extensive experiments on R2R show that PROPER can benefit multiple VLN baselines in perturbation-free scenarios. We further collect the perturbed path data to construct an introspection subset based on the R2R, called Path-Perturbed R2R (PP-R2R). The results on PP-R2R show unsatisfying robustness of popular VLN agents and the capability of PROPER in improving the navigation robustness.
* Accepted by TPAMI 2023
CapDet: Unifying Dense Captioning and Open-World Detection Pretraining
Mar 15, 2023



Benefiting from large-scale vision-language pre-training on image-text pairs, open-world detection methods have shown superior generalization ability under the zero-shot or few-shot detection settings. However, a pre-defined category space is still required during the inference stage of existing methods and only the objects belonging to that space will be predicted. To introduce a "real" open-world detector, in this paper, we propose a novel method named CapDet to either predict under a given category list or directly generate the category of predicted bounding boxes. Specifically, we unify the open-world detection and dense caption tasks into a single yet effective framework by introducing an additional dense captioning head to generate the region-grounded captions. Besides, adding the captioning task will in turn benefit the generalization of detection performance since the captioning dataset covers more concepts. Experiment results show that by unifying the dense caption task, our CapDet has obtained significant performance improvements (e.g., +2.1% mAP on LVIS rare classes) over the baseline method on LVIS (1203 classes). Besides, our CapDet also achieves state-of-the-art performance on dense captioning tasks, e.g., 15.44% mAP on VG V1.2 and 13.98% on the VG-COCO dataset.
NLIP: Noise-robust Language-Image Pre-training
Jan 04, 2023



Large-scale cross-modal pre-training paradigms have recently shown ubiquitous success on a wide range of downstream tasks, e.g., zero-shot classification, retrieval and image captioning. However, their successes highly rely on the scale and quality of web-crawled data that naturally contain incomplete and noisy information (e.g., wrong or irrelevant content). Existing works either design manual rules to clean data or generate pseudo-targets as auxiliary signals for reducing noise impact, which do not explicitly tackle both the incorrect and incomplete challenges simultaneously. In this paper, to automatically mitigate the impact of noise by solely mining over existing data, we propose a principled Noise-robust Language-Image Pre-training framework (NLIP) to stabilize pre-training via two schemes: noise-harmonization and noise-completion. First, in noise-harmonization scheme, NLIP estimates the noise probability of each pair according to the memorization effect of cross-modal transformers, then adopts noise-adaptive regularization to harmonize the cross-modal alignments with varying degrees. Second, in noise-completion scheme, to enrich the missing object information of text, NLIP injects a concept-conditioned cross-modal decoder to obtain semantic-consistent synthetic captions to complete noisy ones, which uses the retrieved visual concepts (i.e., objects' names) for the corresponding image to guide captioning generation. By collaboratively optimizing noise-harmonization and noise-completion schemes, our NLIP can alleviate the common noise effects during image-text pre-training in a more efficient way. Extensive experiments show the significant performance improvements of our NLIP using only 26M data over existing pre-trained models (e.g., CLIP, FILIP and BLIP) on 12 zero-shot classification datasets, MSCOCO image captioning and zero-shot image-text retrieval tasks.
P$^3$OVD: Fine-grained Visual-Text Prompt-Driven Self-Training for Open-Vocabulary Object Detection
Nov 02, 2022Inspired by the success of visual-language methods (VLMs) in zero-shot classification, recent works attempt to extend this line of work into object detection by leveraging the localization ability of pre-trained VLMs and generating pseudo labels for unseen classes in a self-training manner. However, since the current VLMs are usually pre-trained with aligning sentence embedding with global image embedding, the direct use of them lacks fine-grained alignment for object instances, which is the core of detection. In this paper, we propose a simple but effective Pretrain-adaPt-Pseudo labeling paradigm for Open-Vocabulary Detection (P$^3$OVD) that introduces a fine-grained visual-text prompt adapting stage to enhance the current self-training paradigm with a more powerful fine-grained alignment. During the adapting stage, we enable VLM to obtain fine-grained alignment by using learnable text prompts to resolve an auxiliary dense pixel-wise prediction task. Furthermore, we propose a visual prompt module to provide the prior task information (i.e., the categories need to be predicted) for the vision branch to better adapt the pretrained VLM to the downstream tasks. Experiments show that our method achieves the state-of-the-art performance for open-vocabulary object detection, e.g., 31.5% mAP on unseen classes of COCO.
Adversarial Reinforced Instruction Attacker for Robust Vision-Language Navigation
Jul 23, 2021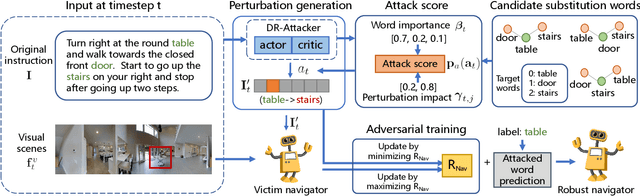
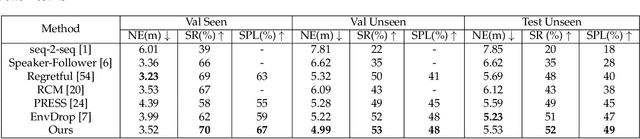
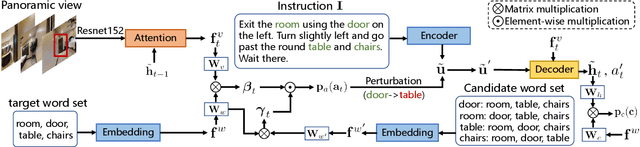

Language instruction plays an essential role in the natural language grounded navigation tasks. However, navigators trained with limited human-annotated instructions may have difficulties in accurately capturing key information from the complicated instruction at different timesteps, leading to poor navigation performance. In this paper, we exploit to train a more robust navigator which is capable of dynamically extracting crucial factors from the long instruction, by using an adversarial attacking paradigm. Specifically, we propose a Dynamic Reinforced Instruction Attacker (DR-Attacker), which learns to mislead the navigator to move to the wrong target by destroying the most instructive information in instructions at different timesteps. By formulating the perturbation generation as a Markov Decision Process, DR-Attacker is optimized by the reinforcement learning algorithm to generate perturbed instructions sequentially during the navigation, according to a learnable attack score. Then, the perturbed instructions, which serve as hard samples, are used for improving the robustness of the navigator with an effective adversarial training strategy and an auxiliary self-supervised reasoning task. Experimental results on both Vision-and-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks show the superiority of our proposed method over state-of-the-art methods. Moreover, the visualization analysis shows the effectiveness of the proposed DR-Attacker, which can successfully attack crucial information in the instructions at different timesteps. Code is available at https://github.com/expectorlin/DR-Attacker.
* Accepted by TPAMI 2021