 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Video Models Ready as Zero-Shot Reasoners? An Empirical Study with the MME-CoF Benchmark
Oct 30, 2025Recent video generation models can produce high-fidelity, temporally coherent videos, indicating that they may encode substantial world knowledge. Beyond realistic synthesis, they also exhibit emerging behaviors indicative of visual perception, modeling, and manipulation. Yet, an important question still remains: Are video models ready to serve as zero-shot reasoners in challenging visual reasoning scenarios? In this work, we conduct an empirical study to comprehensively investigate this question, focusing on the leading and popular Veo-3. We evaluate its reasoning behavior across 12 dimensions, including spatial, geometric, physical, temporal, and embodied logic, systematically characterizing both its strengths and failure modes. To standardize this study, we curate the evaluation data into MME-CoF, a compact benchmark that enables in-depth and thorough assessment of Chain-of-Frame (CoF) reasoning. Our findings reveal that while current video models demonstrate promising reasoning patterns on short-horizon spatial coherence, fine-grained grounding, and locally consistent dynamics, they remain limited in long-horizon causal reasoning, strict geometric constraints, and abstract logic. Overall, they are not yet reliable as standalone zero-shot reasoners, but exhibit encouraging signs as complementary visual engines alongside dedicated reasoning models. Project page: https://video-cof.github.io
Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence
Oct 23, 2025Most video reasoning models only generate textual reasoning traces without indicating when and where key evidence appears. Recent models such as OpenAI-o3 have sparked wide interest in evidence-centered reasoning for images, yet extending this ability to videos is more challenging, as it requires joint temporal tracking and spatial localization across dynamic scenes. We introduce Open-o3 Video, a non-agent framework that integrates explicit spatio-temporal evidence into video reasoning, and carefully collect training data and design training strategies to address the aforementioned challenges. The model highlights key timestamps, objects, and bounding boxes alongside its answers, allowing reasoning to be grounded in concrete visual observations. To enable this functionality, we first curate and build two high-quality datasets, STGR-CoT-30k for SFT and STGR-RL-36k for RL, with carefully constructed temporal and spatial annotations, since most existing datasets offer either temporal spans for videos or spatial boxes on images, lacking unified spatio-temporal supervision and reasoning traces. Then, we adopt a cold-start reinforcement learning strategy with multiple specially designed rewards that jointly encourage answer accuracy, temporal alignment, and spatial precision. On V-STAR benchmark, Open-o3 Video achieves state-of-the-art performance, raising mAM by 14.4% and mLGM by 24.2% on the Qwen2.5-VL baseline. Consistent improvements are also observed on a broad range of video understanding benchmarks, including VideoMME, WorldSense, VideoMMMU, and TVGBench. Beyond accuracy, the reasoning traces produced by Open-o3 Video also provide valuable signals for test-time scaling, enabling confidence-aware verification and improving answer reliability.
From Masks to Worlds: A Hitchhiker's Guide to World Models
Oct 23, 2025This is not a typical survey of world models; it is a guide for those who want to build worlds. We do not aim to catalog every paper that has ever mentioned a ``world model". Instead, we follow one clear road: from early masked models that unified representation learning across modalities, to unified architectures that share a single paradigm, then to interactive generative models that close the action-perception loop, and finally to memory-augmented systems that sustain consistent worlds over time. We bypass loosely related branches to focus on the core: the generative heart, the interactive loop, and the memory system. We show that this is the most promising path towards true world models.
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
One Flight Over the Gap: A Survey from Perspective to Panoramic Vision
Sep 04, 2025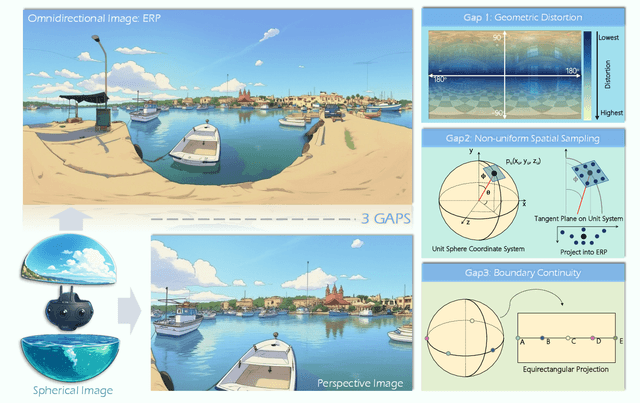
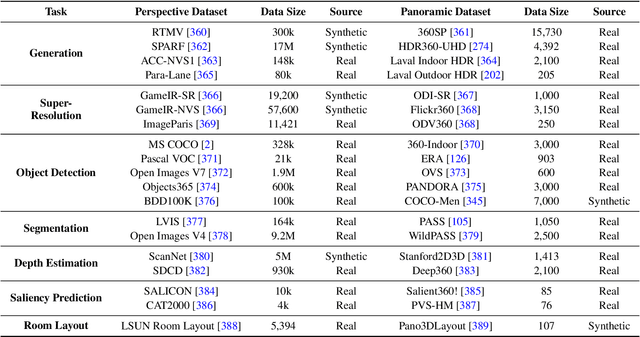
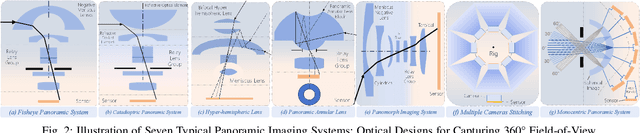
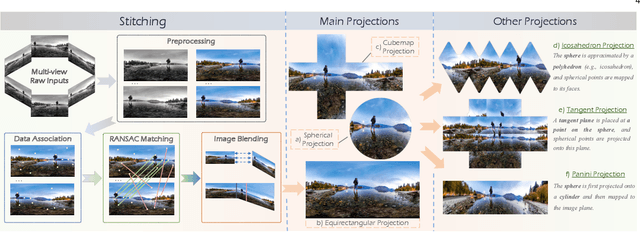
Driven by the demand for spatial intelligence and holistic scene perception, omnidirectional images (ODIs), which provide a complete 360\textdegree{} field of view, are receiving growing attention across diverse applications such as virtual reality, autonomous driving, and embodied robotics. Despite their unique characteristics, ODIs exhibit remarkable differences from perspective images in geometric projection, spatial distribution, and boundary continuity, making it challenging for direct domain adaption from perspective methods. This survey reviews recent panoramic vision techniques with a particular emphasis on the perspective-to-panorama adaptation. We first revisit the panoramic imaging pipeline and projection methods to build the prior knowledge required for analyzing the structural disparities. Then, we summarize three challenges of domain adaptation: severe geometric distortions near the poles, non-uniform sampling in Equirectangular Projection (ERP), and periodic boundary continuity. Building on this, we cover 20+ representative tasks drawn from more than 300 research papers in two dimensions. On one hand, we present a cross-method analysis of representative strategies for addressing panoramic specific challenges across different tasks. On the other hand, we conduct a cross-task comparison and classify panoramic vision into four major categories: visual quality enhancement and assessment, visual understanding, multimodal understanding, and visual generation. In addition, we discuss open challenges and future directions in data, models, and applications that will drive the advancement of panoramic vision research. We hope that our work can provide new insight and forward looking perspectives to advance the development of panoramic vision technologies. Our project page is https://insta360-research-team.github.io/Survey-of-Panorama
PointDGRWKV: Generalizing RWKV-like Architecture to Unseen Domains for Point Cloud Classification
Aug 29, 2025



Domain Generalization (DG) has been recently explored to enhance the generalizability of Point Cloud Classification (PCC) models toward unseen domains. Prior works are based on convolutional networks, Transformer or Mamba architectures, either suffering from limited receptive fields or high computational cost, or insufficient long-range dependency modeling. RWKV, as an emerging architecture, possesses superior linear complexity, global receptive fields, and long-range dependency. In this paper, we present the first work that studies the generalizability of RWKV models in DG PCC. We find that directly applying RWKV to DG PCC encounters two significant challenges: RWKV's fixed direction token shift methods, like Q-Shift, introduce spatial distortions when applied to unstructured point clouds, weakening local geometric modeling and reducing robustness. In addition, the Bi-WKV attention in RWKV amplifies slight cross-domain differences in key distributions through exponential weighting, leading to attention shifts and degraded generalization. To this end, we propose PointDGRWKV, the first RWKV-based framework tailored for DG PCC. It introduces two key modules to enhance spatial modeling and cross-domain robustness, while maintaining RWKV's linear efficiency. In particular, we present Adaptive Geometric Token Shift to model local neighborhood structures to improve geometric context awareness. In addition, Cross-Domain key feature Distribution Alignment is designed to mitigate attention drift by aligning key feature distributions across domains. Extensive experiments on multiple benchmarks demonstrate that PointDGRWKV achieves state-of-the-art performance on DG PCC.
Human-in-Context: Unified Cross-Domain 3D Human Motion Modeling via In-Context Learning
Aug 14, 2025This paper aims to model 3D human motion across domains, where a single model is expected to handle multiple modalities, tasks, and datasets. Existing cross-domain models often rely on domain-specific components and multi-stage training, which limits their practicality and scalability. To overcome these challenges, we propose a new setting to train a unified cross-domain model through a single process, eliminating the need for domain-specific components and multi-stage training. We first introduce Pose-in-Context (PiC), which leverages in-context learning to create a pose-centric cross-domain model. While PiC generalizes across multiple pose-based tasks and datasets, it encounters difficulties with modality diversity, prompting strategy, and contextual dependency handling. We thus propose Human-in-Context (HiC), an extension of PiC that broadens generalization across modalities, tasks, and datasets. HiC combines pose and mesh representations within a unified framework, expands task coverage, and incorporates larger-scale datasets. Additionally, HiC introduces a max-min similarity prompt sampling strategy to enhance generalization across diverse domains and a network architecture with dual-branch context injection for improved handling of contextual dependencies. Extensive experimental results show that HiC performs better than PiC in terms of generalization, data scale, and performance across a wide range of domains. These results demonstrate the potential of HiC for building a unified cross-domain 3D human motion model with improved flexibility and scalability. The source codes and models are available at https://github.com/BradleyWang0416/Human-in-Context.
Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology
Jul 10, 2025

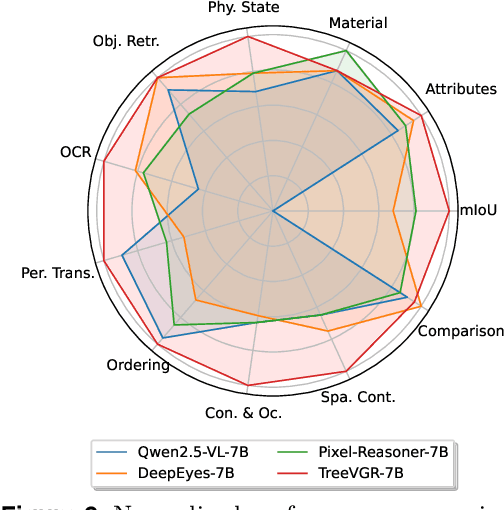

Models like OpenAI-o3 pioneer visual grounded reasoning by dynamically referencing visual regions, just like human "thinking with images". However, no benchmark exists to evaluate these capabilities holistically. To bridge this gap, we propose TreeBench (Traceable Evidence Evaluation Benchmark), a diagnostic benchmark built on three principles: (1) focused visual perception of subtle targets in complex scenes, (2) traceable evidence via bounding box evaluation, and (3) second-order reasoning to test object interactions and spatial hierarchies beyond simple object localization. Prioritizing images with dense objects, we initially sample 1K high-quality images from SA-1B, and incorporate eight LMM experts to manually annotate questions, candidate options, and answers for each image. After three stages of quality control, TreeBench consists of 405 challenging visual question-answering pairs, even the most advanced models struggle with this benchmark, where none of them reach 60% accuracy, e.g., OpenAI-o3 scores only 54.87. Furthermore, we introduce TreeVGR (Traceable Evidence Enhanced Visual Grounded Reasoning), a training paradigm to supervise localization and reasoning jointly with reinforcement learning, enabling accurate localizations and explainable reasoning pathways. Initialized from Qwen2.5-VL-7B, it improves V* Bench (+16.8), MME-RealWorld (+12.6), and TreeBench (+13.4), proving traceability is key to advancing vision-grounded reasoning. The code is available at https://github.com/Haochen-Wang409/TreeVGR.
Reasoning to Edit: Hypothetical Instruction-Based Image Editing with Visual Reasoning
Jul 02, 2025Instruction-based image editing (IIE) has advanced rapidly with the success of diffusion models. However, existing efforts primarily focus on simple and explicit instructions to execute editing operations such as adding, deleting, moving, or swapping objects. They struggle to handle more complex implicit hypothetical instructions that require deeper reasoning to infer plausible visual changes and user intent. Additionally, current datasets provide limited support for training and evaluating reasoning-aware editing capabilities. Architecturally, these methods also lack mechanisms for fine-grained detail extraction that support such reasoning. To address these limitations, we propose Reason50K, a large-scale dataset specifically curated for training and evaluating hypothetical instruction reasoning image editing, along with ReasonBrain, a novel framework designed to reason over and execute implicit hypothetical instructions across diverse scenarios. Reason50K includes over 50K samples spanning four key reasoning scenarios: Physical, Temporal, Causal, and Story reasoning. ReasonBrain leverages Multimodal Large Language Models (MLLMs) for editing guidance generation and a diffusion model for image synthesis, incorporating a Fine-grained Reasoning Cue Extraction (FRCE) module to capture detailed visual and textual semantics essential for supporting instruction reasoning. To mitigate the semantic loss, we further introduce a Cross-Modal Enhancer (CME) that enables rich interactions between the fine-grained cues and MLLM-derived features. Extensive experiments demonstrate that ReasonBrain consistently outperforms state-of-the-art baselines on reasoning scenarios while exhibiting strong zero-shot generalization to conventional IIE tasks. Our dataset and code will be released publicly.
Dense360: Dense Understanding from Omnidirectional Panoramas
Jun 17, 2025Multimodal Large Language Models (MLLMs) require comprehensive visual inputs to achieve dense understanding of the physical world. While existing MLLMs demonstrate impressive world understanding capabilities through limited field-of-view (FOV) visual inputs (e.g., 70 degree), we take the first step toward dense understanding from omnidirectional panoramas. We first introduce an omnidirectional panoramas dataset featuring a comprehensive suite of reliability-scored annotations. Specifically, our dataset contains 160K panoramas with 5M dense entity-level captions, 1M unique referring expressions, and 100K entity-grounded panoramic scene descriptions. Compared to multi-view alternatives, panoramas can provide more complete, compact, and continuous scene representations through equirectangular projections (ERP). However, the use of ERP introduces two key challenges for MLLMs: i) spatial continuity along the circle of latitude, and ii) latitude-dependent variation in information density. We address these challenges through ERP-RoPE, a position encoding scheme specifically designed for panoramic ERP. In addition, we introduce Dense360-Bench, the first benchmark for evaluating MLLMs on omnidirectional captioning and grounding, establishing a comprehensive framework for advancing dense visual-language understanding in panoramic settings.