 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Anomaly Detection on Relational Data
Jun 17, 2026Relational databases are widely used for managing structured data in real-world systems. Detecting anomalies from such relational data is crucial for identifying fraud, risks, and abnormal behaviors, yet remains under-explored. The key challenges lie in the intrinsic complexity of relational data: multi-table attributes are high-dimensional and heterogeneous, making sparse abnormal clues easy to overwhelm by normal or irrelevant information; and anomalies may further manifest as abnormal connection patterns across different foreign-key relations, which existing tabular and graph anomaly detection methods are ill-suited to capture. To address them, we propose RelAD, a reconstruction-based framework that captures anomalies from both attribute and relational edge reconstruction. RelAD contains two core modules: conditional sparse-gated attribute reconstruction, which suppresses redundant multi-table attributes and emphasizes abnormal semantic blocks, and dual-view multi-relational edge reconstruction, which detects relation-specific abnormal connections from both intrinsic and behavioral entity profiles. The resulting attribute and relational signals are integrated through a lightweight fusion module to produce the final anomaly score. We further construct 6 benchmark datasets with systematic anomalies, on which extensive experiments show that RelAD consistently outperforms other baselines while achieving competitive efficiency.
Watch, Remember, Reason: Human-View Video Understanding with MLLMs
Jun 05, 2026Video understanding is being rapidly transformed by multimodal large language models (MLLMs), as research moves from short clips to long, multimodal, and knowledge-intensive video scenarios. These scenarios require models to handle sparse evidence, long-range dependencies, multimodal alignment, and reliable inference under limited computational budgets. This work presents a human-view perspective on LLM-based video understanding, organized around three functional abilities: watching, remembering, and reasoning. Rather than treating video tasks as isolated benchmarks, this view provides a unified structure for analyzing how video MLLMs acquire evidence, preserve context, and produce grounded outputs. We introduce a formulation that characterizes video understanding systems by their perceptual representations, memory states, reasoning traces, and final predictions. Based on this formulation, we identify challenges in spatio-temporal perception, efficient long-video processing, memory modeling, streaming understanding, and faithful reasoning. Representative methods are organized by their roles in video MLLM systems. Watching covers fine-grained, comprehensive, audio-visual, and efficient perception. Remembering includes offline and streaming memory, while reasoning covers text-only reasoning and thinking with videos. We further examine application domains such as egocentric, sports, instructional, medical, and narrative videos, and cover training datasets and evaluation benchmarks across task types, supervision formats, modalities, and capability dimensions. Finally, we outline open problems and future directions for scalable, memory-aware, and evidence-grounded video intelligence. Related works will be continuously traced at https://github.com/marinero4972/Awesome-HumanView-VideoUnderstanding.
Towards One-to-Many Temporal Grounding
Jun 04, 2026Temporal Grounding (TG) aims to localize video segments corresponding to a textual query. Prior research predominantly focuses on single-segment retrieval. Real-world scenarios, however, often require localizing multiple disjoint segments for a single query -- a setting we term One-to-Many Temporal Grounding (OMTG). Previous state-of-the-art MLLMs, optimized for one-to-one settings, struggle in this context, often yielding near-zero scores due to a lack of event cardinality perception. To bridge this gap, we present a systematic solution with three key contributions. First, we establish the first comprehensive OMTG benchmark, introducing Count Accuracy (C-Acc) and Effective Temporal F1 (EtF1) as evaluation metrics. Second, we curate a high-quality OMTG dataset comprising 56k samples through a sophisticated construction pipeline. Third, we develop novel temporal and caption reward functions specifically designed for OMTG. In particular, the caption reward leverages Chain-of-Thought reasoning over dense video captions to explicitly guide policy optimization toward both preciseness and completeness. Extensive experiments show our model achieves a new state-of-the-art EtF1 of 43.65\% on OMTG Bench, outperforming Gemini 2.5 Pro and Seed-1.8 by 15.85\% and 15.61\%, respectively.
FedCIGAR: A Personalized Reconstruction Approach for Federated Graph-level Anomaly Detection
May 10, 2026Graph-level anomaly detection (GLAD) is crucial for ensuring the reliability of graph-driven applications by identifying abnormal graphs that deviate from the majority. Considering the privacy concerns in distributed scenarios, federated graph-level anomaly detection (FedGLAD) has emerged as a promising solution to enable collaborative detection without sharing raw data. However, existing methods suffer from poor generalization due to the reliance on unrealistic synthetic anomalies and insufficient personalization capabilities under data heterogeneity. To address these challenges, we propose a novel Federated graph-level anomaly detection approach with Cluster-adaptIve GAted Reconstruction (FedCIGAR). Specifically, we design a reconstruction-based paradigm trained on normal graphs to avoid synthetic data. Furthermore, we introduce a client-side node contribution gating mechanism and a server-side sliding window-based clustering strategy to tackle data heterogeneity. Extensive experiments demonstrate that FedCIGAR achieves superior performance and robustness in contrast to state-of-the-art methods.
DynHD: Hallucination Detection for Diffusion Large Language Models via Denoising Dynamics Deviation Learning
Mar 17, 2026Diffusion large language models (D-LLMs) have emerged as a promising alternative to auto-regressive models due to their iterative refinement capabilities. However, hallucinations remain a critical issue that hinders their reliability. To detect hallucination responses from model outputs, token-level uncertainty (e.g., entropy) has been widely used as an effective signal to indicate potential factual errors. Nevertheless, the fixed-length generation paradigm of D-LLMs implies that tokens contribute unevenly to hallucination detection, with only a small subset providing meaningful signals. Moreover, the evolution trend of uncertainty throughout the diffusion process can also provide important signals, highlighting the necessity of modeling its denoising dynamics for hallucination detection. In this paper, we propose DynHD that bridge these gaps from both spatial (token sequence) and temporal (denoising dynamics) perspectives. To address the information density imbalance across tokens, we propose a semantic-aware evidence construction module that extracts hallucination-indicative signals by filtering out non-informative tokens and emphasizing semantically meaningful ones. To model denoising dynamics for hallucination detection, we introduce a reference evidence generator that learns the expected evolution trajectory of uncertainty evidence, along with a deviation-based hallucination detector that makes predictions by measuring the discrepancy between the observed and reference trajectories. Extensive experiments demonstrate that DynHD consistently outperforms state-of-the-art baselines while achieving higher efficiency across multiple benchmarks and backbone models.
Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence
Oct 23, 2025Most video reasoning models only generate textual reasoning traces without indicating when and where key evidence appears. Recent models such as OpenAI-o3 have sparked wide interest in evidence-centered reasoning for images, yet extending this ability to videos is more challenging, as it requires joint temporal tracking and spatial localization across dynamic scenes. We introduce Open-o3 Video, a non-agent framework that integrates explicit spatio-temporal evidence into video reasoning, and carefully collect training data and design training strategies to address the aforementioned challenges. The model highlights key timestamps, objects, and bounding boxes alongside its answers, allowing reasoning to be grounded in concrete visual observations. To enable this functionality, we first curate and build two high-quality datasets, STGR-CoT-30k for SFT and STGR-RL-36k for RL, with carefully constructed temporal and spatial annotations, since most existing datasets offer either temporal spans for videos or spatial boxes on images, lacking unified spatio-temporal supervision and reasoning traces. Then, we adopt a cold-start reinforcement learning strategy with multiple specially designed rewards that jointly encourage answer accuracy, temporal alignment, and spatial precision. On V-STAR benchmark, Open-o3 Video achieves state-of-the-art performance, raising mAM by 14.4% and mLGM by 24.2% on the Qwen2.5-VL baseline. Consistent improvements are also observed on a broad range of video understanding benchmarks, including VideoMME, WorldSense, VideoMMMU, and TVGBench. Beyond accuracy, the reasoning traces produced by Open-o3 Video also provide valuable signals for test-time scaling, enabling confidence-aware verification and improving answer reliability.
BlindGuard: Safeguarding LLM-based Multi-Agent Systems under Unknown Attacks
Aug 11, 2025The security of LLM-based multi-agent systems (MAS) is critically threatened by propagation vulnerability, where malicious agents can distort collective decision-making through inter-agent message interactions. While existing supervised defense methods demonstrate promising performance, they may be impractical in real-world scenarios due to their heavy reliance on labeled malicious agents to train a supervised malicious detection model. To enable practical and generalizable MAS defenses, in this paper, we propose BlindGuard, an unsupervised defense method that learns without requiring any attack-specific labels or prior knowledge of malicious behaviors. To this end, we establish a hierarchical agent encoder to capture individual, neighborhood, and global interaction patterns of each agent, providing a comprehensive understanding for malicious agent detection. Meanwhile, we design a corruption-guided detector that consists of directional noise injection and contrastive learning, allowing effective detection model training solely on normal agent behaviors. Extensive experiments show that BlindGuard effectively detects diverse attack types (i.e., prompt injection, memory poisoning, and tool attack) across MAS with various communication patterns while maintaining superior generalizability compared to supervised baselines. The code is available at: https://github.com/MR9812/BlindGuard.
Multi-Stage Verification-Centric Framework for Mitigating Hallucination in Multi-Modal RAG
Jul 27, 2025


This paper presents the technical solution developed by team CRUISE for the KDD Cup 2025 Meta Comprehensive RAG Benchmark for Multi-modal, Multi-turn (CRAG-MM) challenge. The challenge aims to address a critical limitation of modern Vision Language Models (VLMs): their propensity to hallucinate, especially when faced with egocentric imagery, long-tail entities, and complex, multi-hop questions. This issue is particularly problematic in real-world applications where users pose fact-seeking queries that demand high factual accuracy across diverse modalities. To tackle this, we propose a robust, multi-stage framework that prioritizes factual accuracy and truthfulness over completeness. Our solution integrates a lightweight query router for efficiency, a query-aware retrieval and summarization pipeline, a dual-pathways generation and a post-hoc verification. This conservative strategy is designed to minimize hallucinations, which incur a severe penalty in the competition's scoring metric. Our approach achieved 3rd place in Task 1, demonstrating the effectiveness of prioritizing answer reliability in complex multi-modal RAG systems. Our implementation is available at https://github.com/Breezelled/KDD-Cup-2025-Meta-CRAG-MM .
CyberV: Cybernetics for Test-time Scaling in Video Understanding
Jun 09, 2025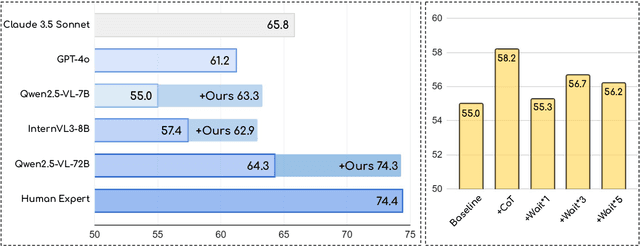
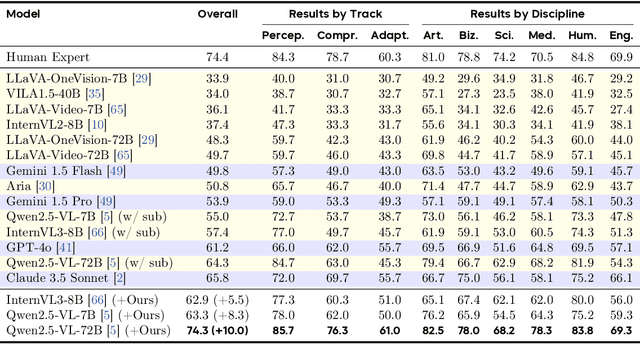
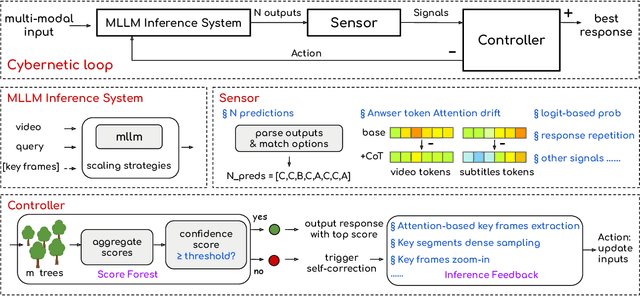
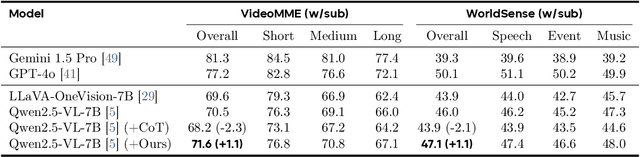
Current Multimodal Large Language Models (MLLMs) may struggle with understanding long or complex videos due to computational demands at test time, lack of robustness, and limited accuracy, primarily stemming from their feed-forward processing nature. These limitations could be more severe for models with fewer parameters. To address these limitations, we propose a novel framework inspired by cybernetic principles, redesigning video MLLMs as adaptive systems capable of self-monitoring, self-correction, and dynamic resource allocation during inference. Our approach, CyberV, introduces a cybernetic loop consisting of an MLLM Inference System, a Sensor, and a Controller. Specifically, the sensor monitors forward processes of the MLLM and collects intermediate interpretations, such as attention drift, then the controller determines when and how to trigger self-correction and generate feedback to guide the next round. This test-time adaptive scaling framework enhances frozen MLLMs without requiring retraining or additional components. Experiments demonstrate significant improvements: CyberV boosts Qwen2.5-VL-7B by 8.3% and InternVL3-8B by 5.5% on VideoMMMU, surpassing the competitive proprietary model GPT-4o. When applied to Qwen2.5-VL-72B, it yields a 10.0% improvement, achieving performance even comparable to human experts. Furthermore, our method demonstrates consistent gains on general-purpose benchmarks, such as VideoMME and WorldSense, highlighting its effectiveness and generalization capabilities in making MLLMs more robust and accurate for dynamic video understanding. The code is released at https://github.com/marinero4972/CyberV.
Understanding the Information Propagation Effects of Communication Topologies in LLM-based Multi-Agent Systems
May 29, 2025The communication topology in large language model-based multi-agent systems fundamentally governs inter-agent collaboration patterns, critically shaping both the efficiency and effectiveness of collective decision-making. While recent studies for communication topology automated design tend to construct sparse structures for efficiency, they often overlook why and when sparse and dense topologies help or hinder collaboration. In this paper, we present a causal framework to analyze how agent outputs, whether correct or erroneous, propagate under topologies with varying sparsity. Our empirical studies reveal that moderately sparse topologies, which effectively suppress error propagation while preserving beneficial information diffusion, typically achieve optimal task performance. Guided by this insight, we propose a novel topology design approach, EIB-leanrner, that balances error suppression and beneficial information propagation by fusing connectivity patterns from both dense and sparse graphs. Extensive experiments show the superior effectiveness, communication cost, and robustness of EIB-leanrner.