 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 1st PortraitCraft Challenge: A CVPR 2026 Workshop Competition on Portrait Composition Understanding and Generation
Jun 09, 2026This paper presents an overview of the inaugural PortraitCraft Challenge, held as one of the official competitions at CVPR 2026. The challenge focuses on portrait composition understanding and generation, aiming to advance AI research in portrait aesthetics analysis and controllable image synthesis. Unlike existing datasets and tasks that primarily focus on global aesthetic scoring, PortraitCraft introduces a unified evaluation framework comprising two complementary tracks. Track 1 requires models to perform structured portrait composition understanding, and Track 2 requires models to generate portrait images from structured composition descriptions under explicit compositional constraints. To support the challenge, we constructed and publicly released a large-scale portrait composition dataset consisting of approximately 50,000 curated real portrait images, providing multi-level supervision. This report describes the challenge setup, evaluation protocols, dataset composition, and final results, along with an analysis of the technical characteristics of the submitted solutions. The PortraitCraft Challenge provides a standardized and reproducible platform for research on portrait composition understanding and generation, and is expected to foster further progress in the fields of portrait aesthetics and controllable image generation.
UniSHARP: Universal Sharp Monocular View Synthesis
Jun 05, 2026In this work, we focus on extending SHARP, the popular photorealistic view synthesis method, for universal monocular rendering across a continuum of camera systems, from conventional perspective cameras to wide-field-of-view, fisheye and omnidirectional panoramic settings. To overcome the pinhole-specific assumptions of SHARP, our key idea is to align various images in a unified omnidirectional latent space. Thus, we propose UniSHARP, which performs implicit alignment in both feature and Gaussian spaces. Specifically, Gaussian primitives are arranged along rays and radial distances in a ray-based universal representation, while 2D semantic and 3D spatial features extracted from UniK3D-inspired encoders are jointly decoded to generate the complete Gaussian cloud. To comprehensively evaluate our method, we construct a benchmark covering diverse imaging systems across various scenes. The benchmark is further stratified by field of view (FoV) to enable fine-grained assessment of the universal monocular rendering task. Extensive experiments on the proposed benchmark demonstrate the effectiveness of UniSHARP, outperforming alternative methods by a large margin. The project page can be found at: https://insta360-research-team.github.io/Unisharp-website/
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
Depth Any Panoramas: A Foundation Model for Panoramic Depth Estimation
Dec 18, 2025



In this work, we present a panoramic metric depth foundation model that generalizes across diverse scene distances. We explore a data-in-the-loop paradigm from the view of both data construction and framework design. We collect a large-scale dataset by combining public datasets, high-quality synthetic data from our UE5 simulator and text-to-image models, and real panoramic images from the web. To reduce domain gaps between indoor/outdoor and synthetic/real data, we introduce a three-stage pseudo-label curation pipeline to generate reliable ground truth for unlabeled images. For the model, we adopt DINOv3-Large as the backbone for its strong pre-trained generalization, and introduce a plug-and-play range mask head, sharpness-centric optimization, and geometry-centric optimization to improve robustness to varying distances and enforce geometric consistency across views. Experiments on multiple benchmarks (e.g., Stanford2D3D, Matterport3D, and Deep360) demonstrate strong performance and zero-shot generalization, with particularly robust and stable metric predictions in diverse real-world scenes. The project page can be found at: \href{https://insta360-research-team.github.io/DAP_website/} {https://insta360-research-team.github.io/DAP\_website/}
One Flight Over the Gap: A Survey from Perspective to Panoramic Vision
Sep 04, 2025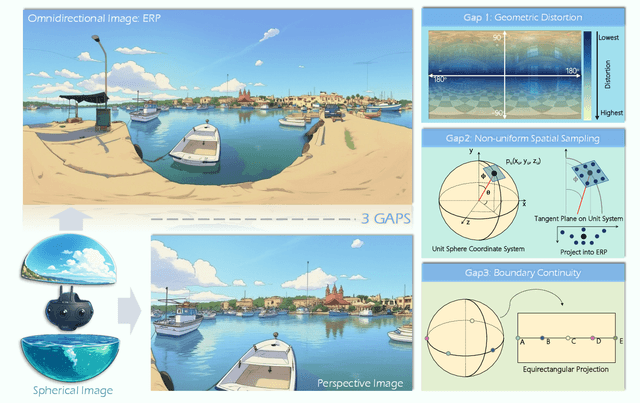
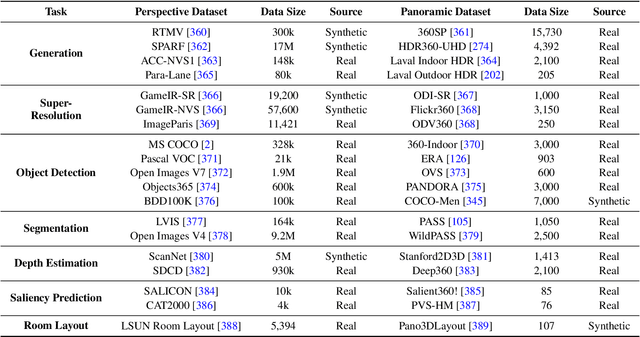
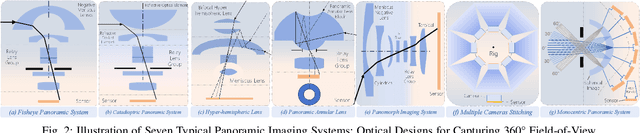
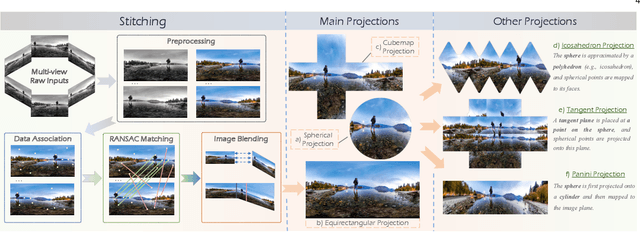
Driven by the demand for spatial intelligence and holistic scene perception, omnidirectional images (ODIs), which provide a complete 360\textdegree{} field of view, are receiving growing attention across diverse applications such as virtual reality, autonomous driving, and embodied robotics. Despite their unique characteristics, ODIs exhibit remarkable differences from perspective images in geometric projection, spatial distribution, and boundary continuity, making it challenging for direct domain adaption from perspective methods. This survey reviews recent panoramic vision techniques with a particular emphasis on the perspective-to-panorama adaptation. We first revisit the panoramic imaging pipeline and projection methods to build the prior knowledge required for analyzing the structural disparities. Then, we summarize three challenges of domain adaptation: severe geometric distortions near the poles, non-uniform sampling in Equirectangular Projection (ERP), and periodic boundary continuity. Building on this, we cover 20+ representative tasks drawn from more than 300 research papers in two dimensions. On one hand, we present a cross-method analysis of representative strategies for addressing panoramic specific challenges across different tasks. On the other hand, we conduct a cross-task comparison and classify panoramic vision into four major categories: visual quality enhancement and assessment, visual understanding, multimodal understanding, and visual generation. In addition, we discuss open challenges and future directions in data, models, and applications that will drive the advancement of panoramic vision research. We hope that our work can provide new insight and forward looking perspectives to advance the development of panoramic vision technologies. Our project page is https://insta360-research-team.github.io/Survey-of-Panorama
Dense360: Dense Understanding from Omnidirectional Panoramas
Jun 17, 2025Multimodal Large Language Models (MLLMs) require comprehensive visual inputs to achieve dense understanding of the physical world. While existing MLLMs demonstrate impressive world understanding capabilities through limited field-of-view (FOV) visual inputs (e.g., 70 degree), we take the first step toward dense understanding from omnidirectional panoramas. We first introduce an omnidirectional panoramas dataset featuring a comprehensive suite of reliability-scored annotations. Specifically, our dataset contains 160K panoramas with 5M dense entity-level captions, 1M unique referring expressions, and 100K entity-grounded panoramic scene descriptions. Compared to multi-view alternatives, panoramas can provide more complete, compact, and continuous scene representations through equirectangular projections (ERP). However, the use of ERP introduces two key challenges for MLLMs: i) spatial continuity along the circle of latitude, and ii) latitude-dependent variation in information density. We address these challenges through ERP-RoPE, a position encoding scheme specifically designed for panoramic ERP. In addition, we introduce Dense360-Bench, the first benchmark for evaluating MLLMs on omnidirectional captioning and grounding, establishing a comprehensive framework for advancing dense visual-language understanding in panoramic settings.