 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Temporal Decoupled Reference Conditioning for Identity-Preserving Text-to-Video Generation
Jun 01, 2026Identity-preserving video generation (IPVG) aims to synthesize high-fidelity videos that follow text prompts while faithfully preserving a reference identity. Despite recent progress, existing IPVG methods still struggle to balance high-level semantic control and low-level identity fidelity. To bridge this gap, we propose ST-DRC, an effective Spatial-Temporal Decoupled Reference Conditioning framework for identity-preserving text-to-video generation. At the framework level, ST-DRC performs latent in-context feature injection by encoding the reference image with the video VAE and concatenating it with noisy video latents, enabling rich low-level identity details to be accessed without additional adapters. To separate identity-aware reference retrieval from appearance copying, we introduce TASS-RoPE, a Temporal-Adjacent Spatial-Shifted RoPE scheme that places reference tokens near the video sequence in time but shifts them in space, allowing reference information to flow through spatio-temporal attention while suppressing pixel-level copy-paste shortcuts. To further prevent shortcut learning and strengthen the otherwise diluted identity supervision in the diffusion objective, we combine appearance-invariant reference augmentation with face-guided identity objectives, encouraging the model to preserve identity under variations in color, pose, and layout. At inference time, we introduce a three-stream reference classifier-free guidance strategy that independently controls text adherence and reference fidelity. Experiments demonstrate that ST-DRC achieves strong identity preservation, prompt alignment, temporal consistency, and video quality with a lightweight design built on LTX-2.3. Our method ranks among the top submissions in the facial identity-preserving video generation track, validating the effectiveness of spatial-temporal decoupled reference conditioning.
PixVerve: Advancing Native UHR Image Generation to 100MP with a Large-Scale High-Quality Dataset
May 19, 2026Text-to-Image (T2I) models have recently seen notable progress around 1K and 2K resolution. With the extreme desire for better visual experience and the rapid development of imaging technology, the demand for Ultra-High-Resolution (UHR) image generation has grown significantly. However, UHR image generation poses great challenges due to the scarcity and complexity of high-resolution content. In this paper, we first introduce PixVerve-95K, a high-quality, open-source UHR T2I dataset curated with a carefully designed data pipeline, which contains 95K images across diverse scenarios (each image has a minimum pixel-count of 100M) and seven-dimensional annotations. Based on our large-scale image-text dataset, we take a pioneering step to extend various T2I foundation models to native 100MP generation with three training schemes. Finally, leveraging both conventional metrics and multimodal large language model-based assessments, our proposed PixVerve-Bench benchmark establishes a comprehensive evaluation protocol for UHR images encompassing visual quality and semantic alignment. Extensive experimental results on our benchmark and the constructive exploration of training strategies collaboratively provide valuable insights for future breakthroughs.
CLEAR: Context-Aware Learning with End-to-End Mask-Free Inference for Adaptive Video Subtitle Removal
Mar 23, 2026Video subtitle removal aims to distinguish text overlays from background content while preserving temporal coherence. Existing diffusion-based methods necessitate explicit mask sequences during both training and inference phases, which restricts their practical deployment. In this paper, we present CLEAR (Context-aware Learning for End-to-end Adaptive Video Subtitle Removal), a mask-free framework that achieves truly end-to-end inference through context-aware adaptive learning. Our two-stage design decouples prior extraction from generative refinement: Stage I learns disentangled subtitle representations via self-supervised orthogonality constraints on dual encoders, while Stage II employs LoRA-based adaptation with generation feedback for dynamic context adjustment. Notably, our method only requires 0.77% of the parameters of the base diffusion model for training. On Chinese subtitle benchmarks, CLEAR outperforms mask-dependent baselines by + 6.77dB PSNR and -74.7% VFID, while demonstrating superior zero-shot generalization across six languages (English, Korean, French, Japanese, Russian, German), a performance enabled by our generation-driven feedback mechanism that ensures robust subtitle removal without ground-truth masks during inference.
The devil is in the details: Enhancing Video Virtual Try-On via Keyframe-Driven Details Injection
Dec 23, 2025Although diffusion transformer (DiT)-based video virtual try-on (VVT) has made significant progress in synthesizing realistic videos, existing methods still struggle to capture fine-grained garment dynamics and preserve background integrity across video frames. They also incur high computational costs due to additional interaction modules introduced into DiTs, while the limited scale and quality of existing public datasets also restrict model generalization and effective training. To address these challenges, we propose a novel framework, KeyTailor, along with a large-scale, high-definition dataset, ViT-HD. The core idea of KeyTailor is a keyframe-driven details injection strategy, motivated by the fact that keyframes inherently contain both foreground dynamics and background consistency. Specifically, KeyTailor adopts an instruction-guided keyframe sampling strategy to filter informative frames from the input video. Subsequently,two tailored keyframe-driven modules, the garment details enhancement module and the collaborative background optimization module, are employed to distill garment dynamics into garment-related latents and to optimize the integrity of background latents, both guided by keyframes.These enriched details are then injected into standard DiT blocks together with pose, mask, and noise latents, enabling efficient and realistic try-on video synthesis. This design ensures consistency without explicitly modifying the DiT architecture, while simultaneously avoiding additional complexity. In addition, our dataset ViT-HD comprises 15, 070 high-quality video samples at a resolution of 810*1080, covering diverse garments. Extensive experiments demonstrate that KeyTailor outperforms state-of-the-art baselines in terms of garment fidelity and background integrity across both dynamic and static scenarios.
CareCom: Generative Image Composition with Calibrated Reference Features
Nov 14, 2025Image composition aims to seamlessly insert foreground object into background. Despite the huge progress in generative image composition, the existing methods are still struggling with simultaneous detail preservation and foreground pose/view adjustment. To address this issue, we extend the existing generative composition model to multi-reference version, which allows using arbitrary number of foreground reference images. Furthermore, we propose to calibrate the global and local features of foreground reference images to make them compatible with the background information. The calibrated reference features can supplement the original reference features with useful global and local information of proper pose/view. Extensive experiments on MVImgNet and MureCom demonstrate that the generative model can greatly benefit from the calibrated reference features.
Reasoning to Edit: Hypothetical Instruction-Based Image Editing with Visual Reasoning
Jul 02, 2025Instruction-based image editing (IIE) has advanced rapidly with the success of diffusion models. However, existing efforts primarily focus on simple and explicit instructions to execute editing operations such as adding, deleting, moving, or swapping objects. They struggle to handle more complex implicit hypothetical instructions that require deeper reasoning to infer plausible visual changes and user intent. Additionally, current datasets provide limited support for training and evaluating reasoning-aware editing capabilities. Architecturally, these methods also lack mechanisms for fine-grained detail extraction that support such reasoning. To address these limitations, we propose Reason50K, a large-scale dataset specifically curated for training and evaluating hypothetical instruction reasoning image editing, along with ReasonBrain, a novel framework designed to reason over and execute implicit hypothetical instructions across diverse scenarios. Reason50K includes over 50K samples spanning four key reasoning scenarios: Physical, Temporal, Causal, and Story reasoning. ReasonBrain leverages Multimodal Large Language Models (MLLMs) for editing guidance generation and a diffusion model for image synthesis, incorporating a Fine-grained Reasoning Cue Extraction (FRCE) module to capture detailed visual and textual semantics essential for supporting instruction reasoning. To mitigate the semantic loss, we further introduce a Cross-Modal Enhancer (CME) that enables rich interactions between the fine-grained cues and MLLM-derived features. Extensive experiments demonstrate that ReasonBrain consistently outperforms state-of-the-art baselines on reasoning scenarios while exhibiting strong zero-shot generalization to conventional IIE tasks. Our dataset and code will be released publicly.
KAN or MLP? Point Cloud Shows the Way Forward
Apr 18, 2025Multi-Layer Perceptrons (MLPs) have become one of the fundamental architectural component in point cloud analysis due to its effective feature learning mechanism. However, when processing complex geometric structures in point clouds, MLPs' fixed activation functions struggle to efficiently capture local geometric features, while suffering from poor parameter efficiency and high model redundancy. In this paper, we propose PointKAN, which applies Kolmogorov-Arnold Networks (KANs) to point cloud analysis tasks to investigate their efficacy in hierarchical feature representation. First, we introduce a Geometric Affine Module (GAM) to transform local features, improving the model's robustness to geometric variations. Next, in the Local Feature Processing (LFP), a parallel structure extracts both group-level features and global context, providing a rich representation of both fine details and overall structure. Finally, these features are combined and processed in the Global Feature Processing (GFP). By repeating these operations, the receptive field gradually expands, enabling the model to capture complete geometric information of the point cloud. To overcome the high parameter counts and computational inefficiency of standard KANs, we develop Efficient-KANs in the PointKAN-elite variant, which significantly reduces parameters while maintaining accuracy. Experimental results demonstrate that PointKAN outperforms PointMLP on benchmark datasets such as ModelNet40, ScanObjectNN, and ShapeNetPart, with particularly strong performance in Few-shot Learning task. Additionally, PointKAN achieves substantial reductions in parameter counts and computational complexity (FLOPs). This work highlights the potential of KANs-based architectures in 3D vision and opens new avenues for research in point cloud understanding.
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025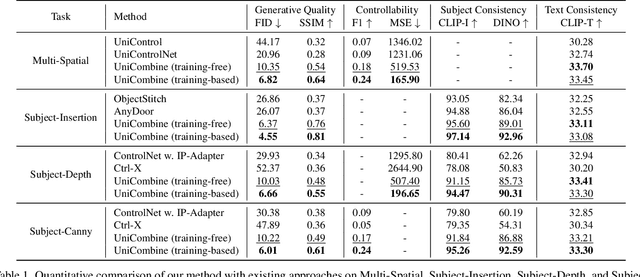
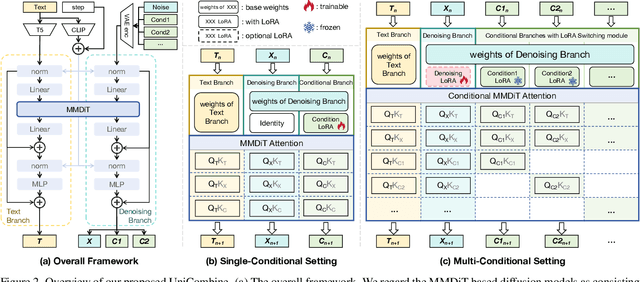
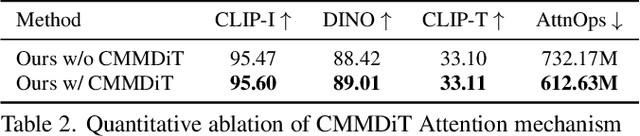
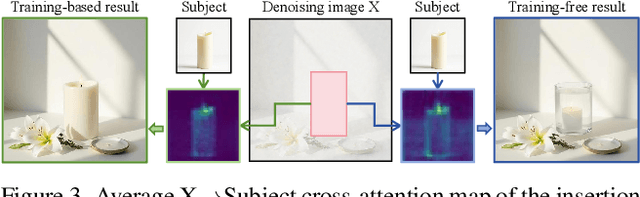
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
Mar 09, 2025Recent advances in diffusion-based text-to-image generation have demonstrated promising results through visual condition control. However, existing ControlNet-like methods struggle with compositional visual conditioning - simultaneously preserving semantic fidelity across multiple heterogeneous control signals while maintaining high visual quality, where they employ separate control branches that often introduce conflicting guidance during the denoising process, leading to structural distortions and artifacts in generated images. To address this issue, we present PixelPonder, a novel unified control framework, which allows for effective control of multiple visual conditions under a single control structure. Specifically, we design a patch-level adaptive condition selection mechanism that dynamically prioritizes spatially relevant control signals at the sub-region level, enabling precise local guidance without global interference. Additionally, a time-aware control injection scheme is deployed to modulate condition influence according to denoising timesteps, progressively transitioning from structural preservation to texture refinement and fully utilizing the control information from different categories to promote more harmonious image generation. Extensive experiments demonstrate that PixelPonder surpasses previous methods across different benchmark datasets, showing superior improvement in spatial alignment accuracy while maintaining high textual semantic consistency.
DynamicControl: Adaptive Condition Selection for Improved Text-to-Image Generation
Dec 04, 2024



To enhance the controllability of text-to-image diffusion models, current ControlNet-like models have explored various control signals to dictate image attributes. However, existing methods either handle conditions inefficiently or use a fixed number of conditions, which does not fully address the complexity of multiple conditions and their potential conflicts. This underscores the need for innovative approaches to manage multiple conditions effectively for more reliable and detailed image synthesis. To address this issue, we propose a novel framework, DynamicControl, which supports dynamic combinations of diverse control signals, allowing adaptive selection of different numbers and types of conditions. Our approach begins with a double-cycle controller that generates an initial real score sorting for all input conditions by leveraging pre-trained conditional generation models and discriminative models. This controller evaluates the similarity between extracted conditions and input conditions, as well as the pixel-level similarity with the source image. Then, we integrate a Multimodal Large Language Model (MLLM) to build an efficient condition evaluator. This evaluator optimizes the ordering of conditions based on the double-cycle controller's score ranking. Our method jointly optimizes MLLMs and diffusion models, utilizing MLLMs' reasoning capabilities to facilitate multi-condition text-to-image (T2I) tasks. The final sorted conditions are fed into a parallel multi-control adapter, which learns feature maps from dynamic visual conditions and integrates them to modulate ControlNet, thereby enhancing control over generated images. Through both quantitative and qualitative comparisons, DynamicControl demonstrates its superiority over existing methods in terms of controllability, generation quality and composability under various conditional controls.