 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
OS-Themis: A Scalable Critic Framework for Generalist GUI Rewards
Mar 19, 2026Reinforcement Learning (RL) has the potential to improve the robustness of GUI agents in stochastic environments, yet training is highly sensitive to the quality of the reward function. Existing reward approaches struggle to achieve both scalability and performance. To address this, we propose OS-Themis, a scalable and accurate multi-agent critic framework. Unlike a single judge, OS-Themis decomposes trajectories into verifiable milestones to isolate critical evidence for decision making and employs a review mechanism to strictly audit the evidence chain before making the final verdict. To facilitate evaluation, we further introduce OmniGUIRewardBench (OGRBench), a holistic cross-platform benchmark for GUI outcome rewards, where all evaluated models achieve their best performance under OS-Themis. Extensive experiments on AndroidWorld show that OS-Themis yields a 10.3% improvement when used to support online RL training, and a 6.9% gain when used for trajectory validation and filtering in the self-training loop, highlighting its potential to drive agent evolution.
OS-Symphony: A Holistic Framework for Robust and Generalist Computer-Using Agent
Jan 12, 2026While Vision-Language Models (VLMs) have significantly advanced Computer-Using Agents (CUAs), current frameworks struggle with robustness in long-horizon workflows and generalization in novel domains. These limitations stem from a lack of granular control over historical visual context curation and the absence of visual-aware tutorial retrieval. To bridge these gaps, we introduce OS-Symphony, a holistic framework that comprises an Orchestrator coordinating two key innovations for robust automation: (1) a Reflection-Memory Agent that utilizes milestone-driven long-term memory to enable trajectory-level self-correction, effectively mitigating visual context loss in long-horizon tasks; (2) Versatile Tool Agents featuring a Multimodal Searcher that adopts a SeeAct paradigm to navigate a browser-based sandbox to synthesize live, visually aligned tutorials, thereby resolving fidelity issues in unseen scenarios. Experimental results demonstrate that OS-Symphony delivers substantial performance gains across varying model scales, establishing new state-of-the-art results on three online benchmarks, notably achieving 65.84% on OSWorld.
OS-Oracle: A Comprehensive Framework for Cross-Platform GUI Critic Models
Dec 18, 2025



With VLM-powered computer-using agents (CUAs) becoming increasingly capable at graphical user interface (GUI) navigation and manipulation, reliable step-level decision-making has emerged as a key bottleneck for real-world deployment. In long-horizon workflows, errors accumulate quickly and irreversible actions can cause unintended consequences, motivating critic models that assess each action before execution. While critic models offer a promising solution, their effectiveness is hindered by the lack of diverse, high-quality GUI feedback data and public critic benchmarks for step-level evaluation in computer use. To bridge these gaps, we introduce OS-Oracle that makes three core contributions: (1) a scalable data pipeline for synthesizing cross-platform GUI critic data; (2) a two-stage training paradigm combining supervised fine-tuning (SFT) and consistency-preserving group relative policy optimization (CP-GRPO); (3) OS-Critic Bench, a holistic benchmark for evaluating critic model performance across Mobile, Web, and Desktop platforms. Leveraging this framework, we curate a high-quality dataset containing 310k critic samples. The resulting critic model, OS-Oracle-7B, achieves state-of-the-art performance among open-source VLMs on OS-Critic Bench, and surpasses proprietary models on the mobile domain. Furthermore, when serving as a pre-critic, OS-Oracle-7B improves the performance of native GUI agents such as UI-TARS-1.5-7B in OSWorld and AndroidWorld environments. The code is open-sourced at https://github.com/numbmelon/OS-Oracle.
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
May 26, 2025



Large Language Models (LLMs) have extended their impact beyond Natural Language Processing, substantially fostering the development of interdisciplinary research. Recently, various LLM-based agents have been developed to assist scientific discovery progress across multiple aspects and domains. Among these, computer-using agents, capable of interacting with operating systems as humans do, are paving the way to automated scientific problem-solving and addressing routines in researchers' workflows. Recognizing the transformative potential of these agents, we introduce ScienceBoard, which encompasses two complementary contributions: (i) a realistic, multi-domain environment featuring dynamic and visually rich scientific workflows with integrated professional software, where agents can autonomously interact via different interfaces to accelerate complex research tasks and experiments; and (ii) a challenging benchmark of 169 high-quality, rigorously validated real-world tasks curated by humans, spanning scientific-discovery workflows in domains such as biochemistry, astronomy, and geoinformatics. Extensive evaluations of agents with state-of-the-art backbones (e.g., GPT-4o, Claude 3.7, UI-TARS) show that, despite some promising results, they still fall short of reliably assisting scientists in complex workflows, achieving only a 15% overall success rate. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents for scientific discovery. Our code, environment, and benchmark are at https://qiushisun.github.io/ScienceBoard-Home/.
OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis
Dec 27, 2024



Graphical User Interface (GUI) agents powered by Vision-Language Models (VLMs) have demonstrated human-like computer control capability. Despite their utility in advancing digital automation, a critical bottleneck persists: collecting high-quality trajectory data for training. Common practices for collecting such data rely on human supervision or synthetic data generation through executing pre-defined tasks, which are either resource-intensive or unable to guarantee data quality. Moreover, these methods suffer from limited data diversity and significant gaps between synthetic data and real-world environments. To address these challenges, we propose OS-Genesis, a novel GUI data synthesis pipeline that reverses the conventional trajectory collection process. Instead of relying on pre-defined tasks, OS-Genesis enables agents first to perceive environments and perform step-wise interactions, then retrospectively derive high-quality tasks to enable trajectory-level exploration. A trajectory reward model is then employed to ensure the quality of the generated trajectories. We demonstrate that training GUI agents with OS-Genesis significantly improves their performance on highly challenging online benchmarks. In-depth analysis further validates OS-Genesis's efficiency and its superior data quality and diversity compared to existing synthesis methods. Our codes, data, and checkpoints are available at \href{https://qiushisun.github.io/OS-Genesis-Home/}{OS-Genesis Homepage}.
OS-Copilot: Towards Generalist Computer Agents with Self-Improvement
Feb 15, 2024



Autonomous interaction with the computer has been a longstanding challenge with great potential, and the recent proliferation of large language models (LLMs) has markedly accelerated progress in building digital agents. However, most of these agents are designed to interact with a narrow domain, such as a specific software or website. This narrow focus constrains their applicability for general computer tasks. To this end, we introduce OS-Copilot, a framework to build generalist agents capable of interfacing with comprehensive elements in an operating system (OS), including the web, code terminals, files, multimedia, and various third-party applications. We use OS-Copilot to create FRIDAY, a self-improving embodied agent for automating general computer tasks. On GAIA, a general AI assistants benchmark, FRIDAY outperforms previous methods by 35%, showcasing strong generalization to unseen applications via accumulated skills from previous tasks. We also present numerical and quantitative evidence that FRIDAY learns to control and self-improve on Excel and Powerpoint with minimal supervision. Our OS-Copilot framework and empirical findings provide infrastructure and insights for future research toward more capable and general-purpose computer agents.
DataLab: A Platform for Data Analysis and Intervention
Feb 25, 2022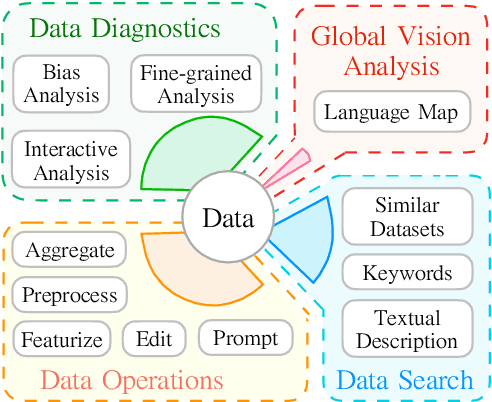
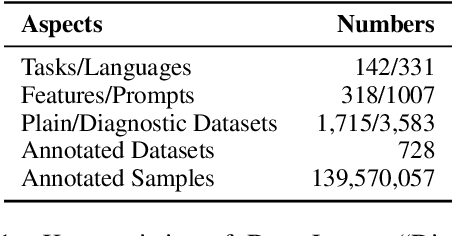
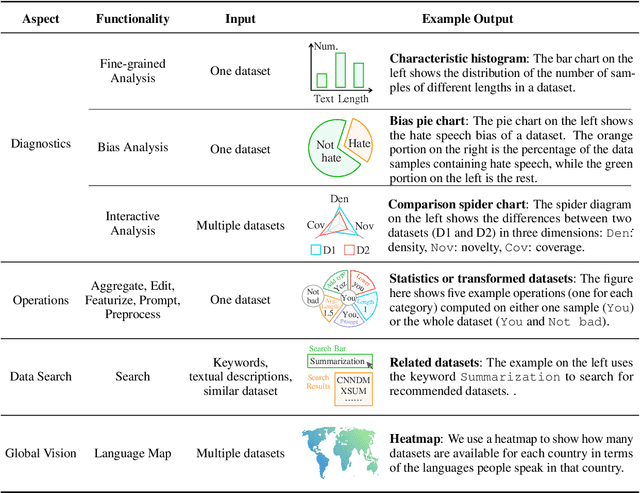
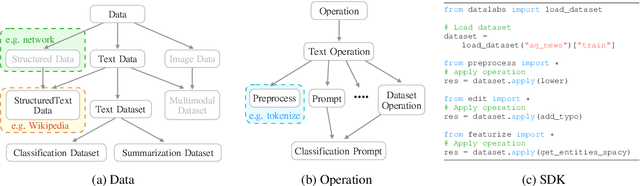
Despite data's crucial role in machine learning, most existing tools and research tend to focus on systems on top of existing data rather than how to interpret and manipulate data. In this paper, we propose DataLab, a unified data-oriented platform that not only allows users to interactively analyze the characteristics of data, but also provides a standardized interface for different data processing operations. Additionally, in view of the ongoing proliferation of datasets, \toolname has features for dataset recommendation and global vision analysis that help researchers form a better view of the data ecosystem. So far, DataLab covers 1,715 datasets and 3,583 of its transformed version (e.g., hyponyms replacement), where 728 datasets support various analyses (e.g., with respect to gender bias) with the help of 140M samples annotated by 318 feature functions. DataLab is under active development and will be supported going forward. We have released a web platform, web API, Python SDK, PyPI published package and online documentation, which hopefully, can meet the diverse needs of researchers.