 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
Sep 18, 2025



Vision-Language Models (VLMs) have enabled computer use agents (CUAs) that operate GUIs autonomously, showing great potential, yet progress is limited by the lack of large-scale, open-source computer use data and foundation models. In this work, we introduce ScaleCUA, a step toward scaling open-source CUAs. It offers a large-scale dataset spanning 6 operating systems and 3 task domains, built via a closed-loop pipeline uniting automated agents with human experts. Trained on this scaled-up data, ScaleCUA can operate seamlessly across platforms. Specifically, it delivers strong gains over baselines (+26.6 on WebArena-Lite-v2, +10.7 on ScreenSpot-Pro) and sets new state-of-the-art results (94.4% on MMBench-GUI L1-Hard, 60.6% on OSWorld-G, 47.4% on WebArena-Lite-v2). These findings underscore the power of data-driven scaling for general-purpose computer use agents. We will release data, models, and code to advance future research: https://github.com/OpenGVLab/ScaleCUA.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
ZeroGUI: Automating Online GUI Learning at Zero Human Cost
May 29, 2025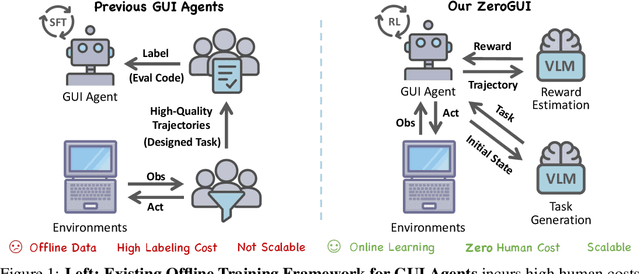
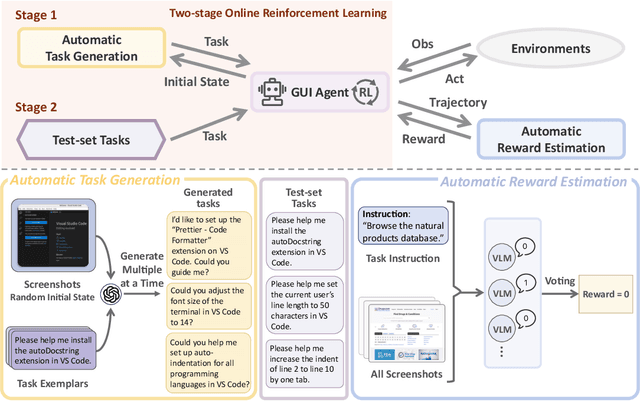


The rapid advancement of large Vision-Language Models (VLMs) has propelled the development of pure-vision-based GUI Agents, capable of perceiving and operating Graphical User Interfaces (GUI) to autonomously fulfill user instructions. However, existing approaches usually adopt an offline learning framework, which faces two core limitations: (1) heavy reliance on high-quality manual annotations for element grounding and action supervision, and (2) limited adaptability to dynamic and interactive environments. To address these limitations, we propose ZeroGUI, a scalable, online learning framework for automating GUI Agent training at Zero human cost. Specifically, ZeroGUI integrates (i) VLM-based automatic task generation to produce diverse training goals from the current environment state, (ii) VLM-based automatic reward estimation to assess task success without hand-crafted evaluation functions, and (iii) two-stage online reinforcement learning to continuously interact with and learn from GUI environments. Experiments on two advanced GUI Agents (UI-TARS and Aguvis) demonstrate that ZeroGUI significantly boosts performance across OSWorld and AndroidLab environments. The code is available at https://github.com/OpenGVLab/ZeroGUI.
InstructSAM: A Training-Free Framework for Instruction-Oriented Remote Sensing Object Recognition
May 21, 2025Language-Guided object recognition in remote sensing imagery is crucial for large-scale mapping and automated data annotation. However, existing open-vocabulary and visual grounding methods rely on explicit category cues, limiting their ability to handle complex or implicit queries that require advanced reasoning. To address this issue, we introduce a new suite of tasks, including Instruction-Oriented Object Counting, Detection, and Segmentation (InstructCDS), covering open-vocabulary, open-ended, and open-subclass scenarios. We further present EarthInstruct, the first InstructCDS benchmark for earth observation. It is constructed from two diverse remote sensing datasets with varying spatial resolutions and annotation rules across 20 categories, necessitating models to interpret dataset-specific instructions. Given the scarcity of semantically rich labeled data in remote sensing, we propose InstructSAM, a training-free framework for instruction-driven object recognition. InstructSAM leverages large vision-language models to interpret user instructions and estimate object counts, employs SAM2 for mask proposal, and formulates mask-label assignment as a binary integer programming problem. By integrating semantic similarity with counting constraints, InstructSAM efficiently assigns categories to predicted masks without relying on confidence thresholds. Experiments demonstrate that InstructSAM matches or surpasses specialized baselines across multiple tasks while maintaining near-constant inference time regardless of object count, reducing output tokens by 89% and overall runtime by over 32% compared to direct generation approaches. We believe the contributions of the proposed tasks, benchmark, and effective approach will advance future research in developing versatile object recognition systems.
Secure Directional Modulation with Movable Antenna Array Aided by RIS
Apr 10, 2025



In this paper, to fully exploit the performance gains from moveable antennas (MAs) and reconfigurable intelligent surface (RIS), a RIS-aided directional modulation \textcolor{blue}{(DM)} network with movable antenna at base station (BS) is established Based on the principle of DM, a BS equipped with MAs transmits legitimate information to a single-antenna user (Bob) while exploiting artificial noise (AN) to degrade signal reception at the eavesdropper (Eve). The combination of AN and transmission beamforming vectors is modeled as joint beamforming vector (JBV) to achieve optimal power allocation. The objective is to maximize the achievable secrecy rate (SR) by optimizing MAs antenna position, phase shift matrix (PSM) of RIS, and JBV. The limited movable range (MR) and discrete candidate positions of the MAs at the BS are considered, which renders the optimization problem non-convex. To address these challenges, an optimization method under perfect channel state information (CSI) is firstly designed, in which the MAs antenna positions are obtained using compressive sensing (CS) technology, and JBV and PSM are iteratively optimized. Then, the design method and SR performance under imperfect CSI is investigated. The proposed algorithms have fewer iterations and lower complexity. Simulation results demonstrate that MAs outperform fixed-position antennas in SR performance when there is an adequately large MR available.
Generalized Tensor-based Parameter-Efficient Fine-Tuning via Lie Group Transformations
Apr 01, 2025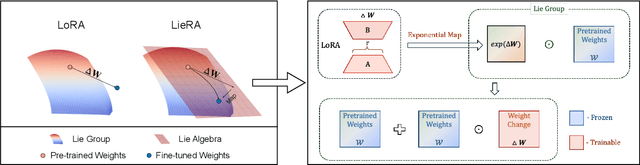
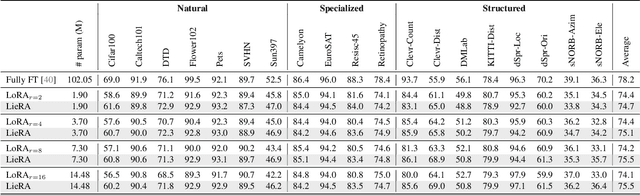
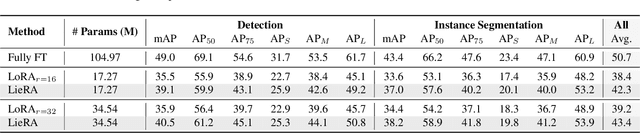

Adapting pre-trained foundation models for diverse downstream tasks is a core practice in artificial intelligence. However, the wide range of tasks and high computational costs make full fine-tuning impractical. To overcome this, parameter-efficient fine-tuning (PEFT) methods like LoRA have emerged and are becoming a growing research focus. Despite the success of these methods, they are primarily designed for linear layers, focusing on two-dimensional matrices while largely ignoring higher-dimensional parameter spaces like convolutional kernels. Moreover, directly applying these methods to higher-dimensional parameter spaces often disrupts their structural relationships. Given the rapid advancements in matrix-based PEFT methods, rather than designing a specialized strategy, we propose a generalization that extends matrix-based PEFT methods to higher-dimensional parameter spaces without compromising their structural properties. Specifically, we treat parameters as elements of a Lie group, with updates modeled as perturbations in the corresponding Lie algebra. These perturbations are mapped back to the Lie group through the exponential map, ensuring smooth, consistent updates that preserve the inherent structure of the parameter space. Extensive experiments on computer vision and natural language processing validate the effectiveness and versatility of our approach, demonstrating clear improvements over existing methods.
ICM-Assistant: Instruction-tuning Multimodal Large Language Models for Rule-based Explainable Image Content Moderation
Dec 24, 2024



Controversial contents largely inundate the Internet, infringing various cultural norms and child protection standards. Traditional Image Content Moderation (ICM) models fall short in producing precise moderation decisions for diverse standards, while recent multimodal large language models (MLLMs), when adopted to general rule-based ICM, often produce classification and explanation results that are inconsistent with human moderators. Aiming at flexible, explainable, and accurate ICM, we design a novel rule-based dataset generation pipeline, decomposing concise human-defined rules and leveraging well-designed multi-stage prompts to enrich short explicit image annotations. Our ICM-Instruct dataset includes detailed moderation explanation and moderation Q-A pairs. Built upon it, we create our ICM-Assistant model in the framework of rule-based ICM, making it readily applicable in real practice. Our ICM-Assistant model demonstrates exceptional performance and flexibility. Specifically, it significantly outperforms existing approaches on various sources, improving both the moderation classification (36.8\% on average) and moderation explanation quality (26.6\% on average) consistently over existing MLLMs. Code/Data is available at https://github.com/zhaoyuzhi/ICM-Assistant.
Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
Dec 06, 2024



We introduce InternVL 2.5, an advanced multimodal large language model (MLLM) series that builds upon InternVL 2.0, maintaining its core model architecture while introducing significant enhancements in training and testing strategies as well as data quality. In this work, we delve into the relationship between model scaling and performance, systematically exploring the performance trends in vision encoders, language models, dataset sizes, and test-time configurations. Through extensive evaluations on a wide range of benchmarks, including multi-discipline reasoning, document understanding, multi-image / video understanding, real-world comprehension, multimodal hallucination detection, visual grounding, multilingual capabilities, and pure language processing, InternVL 2.5 exhibits competitive performance, rivaling leading commercial models such as GPT-4o and Claude-3.5-Sonnet. Notably, our model is the first open-source MLLMs to surpass 70% on the MMMU benchmark, achieving a 3.7-point improvement through Chain-of-Thought (CoT) reasoning and showcasing strong potential for test-time scaling. We hope this model contributes to the open-source community by setting new standards for developing and applying multimodal AI systems. HuggingFace demo see https://huggingface.co/spaces/OpenGVLab/InternVL
DoF Analysis and Beamforming Design for Active IRS-aided Multi-user MIMO Wireless Communication in Rank-deficient Channels
Nov 13, 2024



Due to its ability of significantly improving data rate, intelligent reflecting surface (IRS) will be a potential crucial technique for the future generation wireless networks like 6G. In this paper, we will focus on the analysis of degree of freedom (DoF) in IRS-aided multi-user MIMO network. Firstly, the DoF upper bound of IRS-aided single-user MIMO network, i.e., the achievable maximum DoF of such a system, is derived, and the corresponding results are extended to the case of IRS-aided multiuser MIMO by using the matrix rank inequalities. In particular, in serious rank-deficient, also called low-rank, channels like line-of-sight (LoS), the network DoF may doubles over no-IRS with the help of IRS. To verify the rate performance gain from augmented DoF, three closed-form beamforming methods, null-space projection plus maximize transmit power and maximize receive power (NSP-MTP-MRP), Schmidt orthogonalization plus minimum mean square error (SO-MMSE) and two-layer leakage plus MMSE (TLL-MMSE) are proposed to achieve the maximum DoF. Simulation results shows that IRS does make a dramatic rate enhancement. For example, in a serious deficient channel, the sum-rate of the proposed TLL-MMSE aided by IRS is about twice that of no IRS. This means that IRS may achieve a significant DoF improvement in such a channel.
Joint Power Allocation and Beamforming Design for Active IRS-Aided Directional Modulation Secure Systems
Jun 13, 2024



Since the secrecy rate (SR) performance improvement obtained by secure directional modulation (DM) network is limited, an active intelligent reflective surface (IRS)-assisted DM network is considered to attain a high SR. To address the SR maximization problem, a novel method based on Lagrangian dual transform and closed-form fractional programming algorithm (LDT-CFFP) is proposed, where the solutions to base station (BS) beamforming vectors and IRS reflection coefficient matrix are achieved. However, the computational complexity of LDT-CFFP method is high . To reduce its complexity, a blocked IRS-assisted DM network is designed. To meet the requirements of the network performance, a power allocation (PA) strategy is proposed and adopted in the system. Specifically, the system power between BS and IRS, as well as the transmission power for confidential messages (CM) and artificial noise (AN) from the BS, are allocated separately. Then we put forward null-space projection (NSP) method, maximum-ratio-reflecting (MRR) algorithm and PA strategy (NSP-MRR-PA) to solve the SR maximization problem. The CF solutions to BS beamforming vectors and IRS reflection coefficient matrix are respectively attained via NSP and MRR algorithms. For the PA factors, we take advantage of exhaustive search (ES) algorithm, particle swarm optimization (PSO) and simulated annealing (SA) algorithm to search for the solutions. From simulation results, it is verified that the LDT-CFFP method derives a higher SR gain over NSP-MRR-PA method. For NSP-MRR-PA method, the number of IRS units in each block possesses a significant SR performance. In addition, the application PA strategies, namely ES, PSO, SA methods outperforms the other PA strategies with fixed PA factors.