 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Hidden Deception in Reasoning LLMs: Activation Explainers for Deception Auditing
Jun 16, 2026As LLMs acquire stronger reasoning capabilities, deceptive behavior becomes an increasingly serious safety concern. Existing deception monitors either score visible transcripts or derive scalar probe scores from representation vectors, leaving little inspectable evidence about why a response is suspicious. We introduce STATEWITNESS, an activation explainer for deception auditing. A separate decoder reads a target model's hidden states, then answers natural-language queries or emits structured reports about them. We evaluate STATEWITNESS on two target reasoning LLMs across seven deception datasets. STATEWITNESS reaches 0.916 mean AUROC, a relative gain of 11.6% over the best black-box text monitor and 25.0% over the best activation-probe baseline under the same evaluation protocol. When combined with existing monitors, STATEWITNESS reduces missed deceptive examples in simple threshold ensembles. Beyond scalar detection, the decoder returns query-level answers, schema reports, and token- or sentence-level evidence traces for human inspection. We view this interface as a potential building block for broader interpretability and alignment tools.
DDOR: Delta Debugging for Explainable Overrefusal Testing and Repair
Jun 02, 2026While safety alignment and guardrails help large language models (LLMs) avoid harmful outputs, they can also induce overrefusal, i.e., unwarranted rejection of benign queries that merely appear risky. We present DDOR (Delta Debugging for OverRefusal), a fully automated and explainable framework for overrefusal testing and repair in a black-box setting, where only model inputs and outputs are accessible and internal safety mechanisms remain opaque. DDOR applies delta debugging to localize minimal refusal-triggering fragments (mRTFs) that provide phrase-level, explainable evidence for why a refusal occurs. Conditioned on these mRTFs, DDOR generates diverse, context-rich prompts and performs multi-oracle validation to filter intrinsically unsafe or ambiguous cases, producing scalable and model-specific overrefusal test suites (approximately 1K cases per model). Beyond evaluation, we further leverage localized mRTFs to perform targeted prompt repair, substantially reducing overrefusal while preserving the original intent and maintaining safety on genuinely harmful inputs. Overall, DDOR offers a practical end-to-end solution to both evaluate and mitigate overrefusal, improving LLM usability without sacrificing safety.
LLM-VA: Resolving the Jailbreak-Overrefusal Trade-off via Vector Alignment
Jan 27, 2026Safety-aligned LLMs suffer from two failure modes: jailbreak (answering harmful inputs) and over-refusal (declining benign queries). Existing vector steering methods adjust the magnitude of answer vectors, but this creates a fundamental trade-off -- reducing jailbreak increases over-refusal and vice versa. We identify the root cause: LLMs encode the decision to answer (answer vector $v_a$) and the judgment of input safety (benign vector $v_b$) as nearly orthogonal directions, treating them as independent processes. We propose LLM-VA, which aligns $v_a$ with $v_b$ through closed-form weight updates, making the model's willingness to answer causally dependent on its safety assessment -- without fine-tuning or architectural changes. Our method identifies vectors at each layer using SVMs, selects safety-relevant layers, and iteratively aligns vectors via minimum-norm weight modifications. Experiments on 12 LLMs demonstrate that LLM-VA achieves 11.45% higher F1 than the best baseline while preserving 95.92% utility, and automatically adapts to each model's safety bias without manual tuning. Code and models are available at https://hotbento.github.io/LLM-VA-Web/.
Think When Needed: Model-Aware Reasoning Routing for LLM-based Ranking
Jan 26, 2026Large language models (LLMs) are increasingly applied to ranking tasks in retrieval and recommendation. Although reasoning prompting can enhance ranking utility, our preliminary exploration reveals that its benefits are inconsistent and come at a substantial computational cost, suggesting that when to reason is as crucial as how to reason. To address this issue, we propose a reasoning routing framework that employs a lightweight, plug-and-play router head to decide whether to use direct inference (Non-Think) or reasoning (Think) for each instance before generation. The router head relies solely on pre-generation signals: i) compact ranking-aware features (e.g., candidate dispersion) and ii) model-aware difficulty signals derived from a diagnostic checklist reflecting the model's estimated need for reasoning. By leveraging these features before generation, the router outputs a controllable token that determines whether to apply the Think mode. Furthermore, the router can adaptively select its operating policy along the validation Pareto frontier during deployment, enabling dynamic allocation of computational resources toward instances most likely to benefit from Think under varying system constraints. Experiments on three public ranking datasets with different scales of open-source LLMs show consistent improvements in ranking utility with reduced token consumption (e.g., +6.3\% NDCG@10 with -49.5\% tokens on MovieLens with Qwen3-4B), demonstrating reasoning routing as a practical solution to the accuracy-efficiency trade-off.
RP-CATE: Recurrent Perceptron-based Channel Attention Transformer Encoder for Industrial Hybrid Modeling
Dec 22, 2025Nowadays, industrial hybrid modeling which integrates both mechanistic modeling and machine learning-based modeling techniques has attracted increasing interest from scholars due to its high accuracy, low computational cost, and satisfactory interpretability. Nevertheless, the existing industrial hybrid modeling methods still face two main limitations. First, current research has mainly focused on applying a single machine learning method to one specific task, failing to develop a comprehensive machine learning architecture suitable for modeling tasks, which limits their ability to effectively represent complex industrial scenarios. Second, industrial datasets often contain underlying associations (e.g., monotonicity or periodicity) that are not adequately exploited by current research, which can degrade model's predictive performance. To address these limitations, this paper proposes the Recurrent Perceptron-based Channel Attention Transformer Encoder (RP-CATE), with three distinctive characteristics: 1: We developed a novel architecture by replacing the self-attention mechanism with channel attention and incorporating our proposed Recurrent Perceptron (RP) Module into Transformer, achieving enhanced effectiveness for industrial modeling tasks compared to the original Transformer. 2: We proposed a new data type called Pseudo-Image Data (PID) tailored for channel attention requirements and developed a cyclic sliding window method for generating PID. 3: We introduced the concept of Pseudo-Sequential Data (PSD) and a method for converting industrial datasets into PSD, which enables the RP Module to capture the underlying associations within industrial dataset more effectively. An experiment aimed at hybrid modeling in chemical engineering was conducted by using RP-CATE and the experimental results demonstrate that RP-CATE achieves the best performance compared to other baseline models.
Mirroring Users: Towards Building Preference-aligned User Simulator with User Feedback in Recommendation
Aug 25, 2025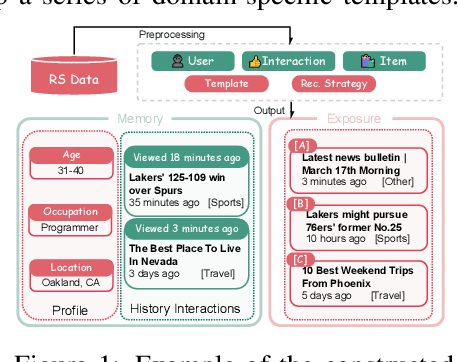
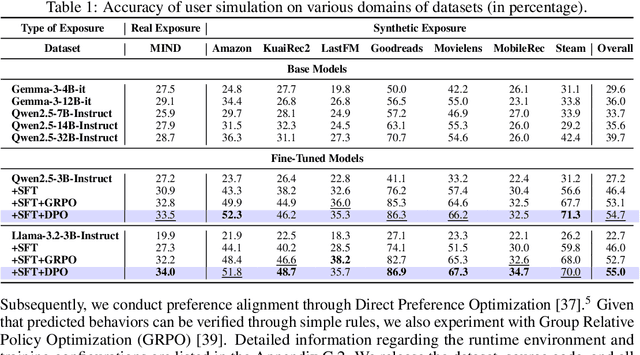
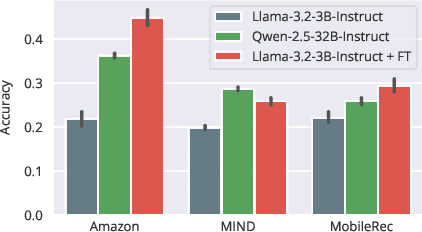
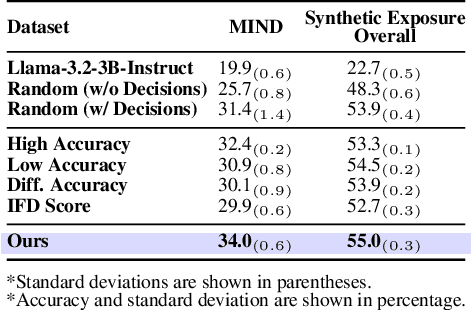
User simulation is increasingly vital to develop and evaluate recommender systems (RSs). While Large Language Models (LLMs) offer promising avenues to simulate user behavior, they often struggle with the absence of specific domain alignment required for RSs and the efficiency demands of large-scale simulation. A vast yet underutilized resource for enhancing this alignment is the extensive user feedback inherent in RSs. However, directly leveraging such feedback presents two significant challenges. First, user feedback in RSs is often ambiguous and noisy, which negatively impacts effective preference alignment. Second, the massive volume of feedback largely hinders the efficiency of preference alignment, necessitating an efficient filtering mechanism to identify more informative samples. To overcome these hurdles, we introduce a novel data construction framework that leverages user feedback in RSs with advanced LLM capabilities to generate high-quality simulation data. Our framework unfolds in two key phases: (1) employing LLMs to generate cognitive decision-making processes on constructed simulation samples, reducing ambiguity in raw user feedback; (2) data distillation based on uncertainty estimation and behavior sampling to filter challenging yet denoised simulation samples. Accordingly, we fine-tune lightweight LLMs, as user simulators, using such high-quality dataset with corresponding decision-making processes. Extensive experiments verify that our framework significantly boosts the alignment with human preferences and in-domain reasoning capabilities of fine-tuned LLMs, and provides more insightful and interpretable signals when interacting with RSs. We believe our work will advance the RS community and offer valuable insights for broader human-centric AI research.
RAS-Eval: A Comprehensive Benchmark for Security Evaluation of LLM Agents in Real-World Environments
Jun 18, 2025The rapid deployment of Large language model (LLM) agents in critical domains like healthcare and finance necessitates robust security frameworks. To address the absence of standardized evaluation benchmarks for these agents in dynamic environments, we introduce RAS-Eval, a comprehensive security benchmark supporting both simulated and real-world tool execution. RAS-Eval comprises 80 test cases and 3,802 attack tasks mapped to 11 Common Weakness Enumeration (CWE) categories, with tools implemented in JSON, LangGraph, and Model Context Protocol (MCP) formats. We evaluate 6 state-of-the-art LLMs across diverse scenarios, revealing significant vulnerabilities: attacks reduced agent task completion rates (TCR) by 36.78% on average and achieved an 85.65% success rate in academic settings. Notably, scaling laws held for security capabilities, with larger models outperforming smaller counterparts. Our findings expose critical risks in real-world agent deployments and provide a foundational framework for future security research. Code and data are available at https://github.com/lanzer-tree/RAS-Eval.
LightKG: Efficient Knowledge-Aware Recommendations with Simplified GNN Architecture
Jun 12, 2025



Recently, Graph Neural Networks (GNNs) have become the dominant approach for Knowledge Graph-aware Recommender Systems (KGRSs) due to their proven effectiveness. Building upon GNN-based KGRSs, Self-Supervised Learning (SSL) has been incorporated to address the sparity issue, leading to longer training time. However, through extensive experiments, we reveal that: (1)compared to other KGRSs, the existing GNN-based KGRSs fail to keep their superior performance under sparse interactions even with SSL. (2) More complex models tend to perform worse in sparse interaction scenarios and complex mechanisms, like attention mechanism, can be detrimental as they often increase learning difficulty. Inspired by these findings, we propose LightKG, a simple yet powerful GNN-based KGRS to address sparsity issues. LightKG includes a simplified GNN layer that encodes directed relations as scalar pairs rather than dense embeddings and employs a linear aggregation framework, greatly reducing the complexity of GNNs. Additionally, LightKG incorporates an efficient contrastive layer to implement SSL. It directly minimizes the node similarity in original graph, avoiding the time-consuming subgraph generation and comparison required in previous SSL methods. Experiments on four benchmark datasets show that LightKG outperforms 12 competitive KGRSs in both sparse and dense scenarios while significantly reducing training time. Specifically, it surpasses the best baselines by an average of 5.8\% in recommendation accuracy and saves 84.3\% of training time compared to KGRSs with SSL. Our code is available at https://github.com/1371149/LightKG.
Fair-PP: A Synthetic Dataset for Aligning LLM with Personalized Preferences of Social Equity
May 17, 2025Human preference plays a crucial role in the refinement of large language models (LLMs). However, collecting human preference feedback is costly and most existing datasets neglect the correlation between personalization and preferences. To address this issue, we introduce Fair-PP, a synthetic dataset of personalized preferences targeting social equity, derived from real-world social survey data, which includes 28 social groups, 98 equity topics, and 5 personal preference dimensions. Leveraging GPT-4o-mini, we engage in role-playing based on seven representative persona portrayals guided by existing social survey data, yielding a total of 238,623 preference records. Through Fair-PP, we also contribute (i) An automated framework for generating preference data, along with a more fine-grained dataset of personalized preferences; (ii) analysis of the positioning of the existing mainstream LLMs across five major global regions within the personalized preference space; and (iii) a sample reweighting method for personalized preference alignment, enabling alignment with a target persona while maximizing the divergence from other personas. Empirical experiments show our method outperforms the baselines.
Enhancing New-item Fairness in Dynamic Recommender Systems
Apr 30, 2025New-items play a crucial role in recommender systems (RSs) for delivering fresh and engaging user experiences. However, traditional methods struggle to effectively recommend new-items due to their short exposure time and limited interaction records, especially in dynamic recommender systems (DRSs) where new-items get continuously introduced and users' preferences evolve over time. This leads to significant unfairness towards new-items, which could accumulate over the successive model updates, ultimately compromising the stability of the entire system. Therefore, we propose FairAgent, a reinforcement learning (RL)-based new-item fairness enhancement framework specifically designed for DRSs. It leverages knowledge distillation to extract collaborative signals from traditional models, retaining strong recommendation capabilities for old-items. In addition, FairAgent introduces a novel reward mechanism for recommendation tailored to the characteristics of DRSs, which consists of three components: 1) a new-item exploration reward to promote the exposure of dynamically introduced new-items, 2) a fairness reward to adapt to users' personalized fairness requirements for new-items, and 3) an accuracy reward which leverages users' dynamic feedback to enhance recommendation accuracy. Extensive experiments on three public datasets and backbone models demonstrate the superior performance of FairAgent. The results present that FairAgent can effectively boost new-item exposure, achieve personalized new-item fairness, while maintaining high recommendation accuracy.