 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooping Back to Move Forward: Recursive Transformers for Efficient and Flexible Large Multimodal Models
Feb 09, 2026Large Multimodal Models (LMMs) have achieved remarkable success in vision-language tasks, yet their vast parameter counts are often underutilized during both training and inference. In this work, we embrace the idea of looping back to move forward: reusing model parameters through recursive refinement to extract stronger multimodal representations without increasing model size. We propose RecursiveVLM, a recursive Transformer architecture tailored for LMMs. Two key innovations enable effective looping: (i) a Recursive Connector that aligns features across recursion steps by fusing intermediate-layer hidden states and applying modality-specific projections, respecting the distinct statistical structures of vision and language tokens; (ii) a Monotonic Recursion Loss that supervises every step and guarantees performance improves monotonically with recursion depth. This design transforms recursion into an on-demand refinement mechanism: delivering strong results with few loops on resource-constrained devices and progressively improving outputs when more computation resources are available. Experiments show consistent gains of +3% over standard Transformers and +7% over vanilla recursive baselines, demonstrating that strategic looping is a powerful path toward efficient, deployment-adaptive LMMs.
FlattenGPT: Depth Compression for Transformer with Layer Flattening
Feb 09, 2026Recent works have indicated redundancy across transformer blocks, prompting the research of depth compression to prune less crucial blocks. However, current ways of entire-block pruning suffer from risks of discarding meaningful cues learned in those blocks, leading to substantial performance degradation. As another line of model compression, channel pruning can better preserve performance, while it cannot reduce model depth and is challenged by inconsistent pruning ratios for individual layers. To pursue better model compression and acceleration, this paper proposes \textbf{FlattenGPT}, a novel way to detect and reduce depth-wise redundancies. By flatting two adjacent blocks into one, it compresses the network depth, meanwhile enables more effective parameter redundancy detection and removal. FlattenGPT allows to preserve the knowledge learned in all blocks, and remains consistent with the original transformer architecture. Extensive experiments demonstrate that FlattenGPT enhances model efficiency with a decent trade-off to performance. It outperforms existing pruning methods in both zero-shot accuracies and WikiText-2 perplexity across various model types and parameter sizes. On LLaMA-2/3 and Qwen-1.5 models, FlattenGPT retains 90-96\% of zero-shot performance with a compression ratio of 20\%. It also outperforms other pruning methods in accelerating LLM inference, making it promising for enhancing the efficiency of transformers.
VideoScaffold: Elastic-Scale Visual Hierarchies for Streaming Video Understanding in MLLMs
Dec 23, 2025Understanding long videos with multimodal large language models (MLLMs) remains challenging due to the heavy redundancy across frames and the need for temporally coherent representations. Existing static strategies, such as sparse sampling, frame compression, and clustering, are optimized for offline settings and often produce fragmented or over-compressed outputs when applied to continuous video streams. We present VideoScaffold, a dynamic representation framework designed for streaming video understanding. It adaptively adjusts event granularity according to video duration while preserving fine-grained visual semantics. VideoScaffold introduces two key components: Elastic-Scale Event Segmentation (EES), which performs prediction-guided segmentation to dynamically refine event boundaries, and Hierarchical Event Consolidation (HEC), which progressively aggregates semantically related segments into multi-level abstractions. Working in concert, EES and HEC enable VideoScaffold to transition smoothly from fine-grained frame understanding to abstract event reasoning as the video stream unfolds. Extensive experiments across both offline and streaming video understanding benchmarks demonstrate that VideoScaffold achieves state-of-the-art performance. The framework is modular and plug-and-play, seamlessly extending existing image-based MLLMs to continuous video comprehension. The code is available at https://github.com/zheng980629/VideoScaffold.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025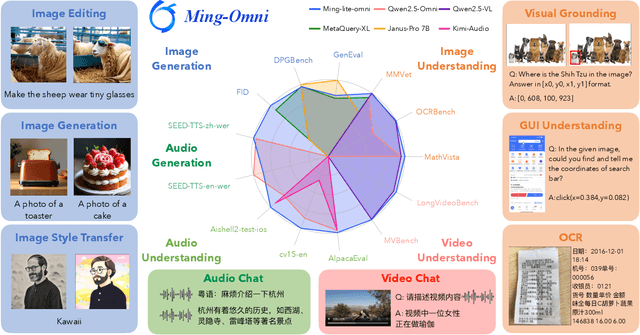
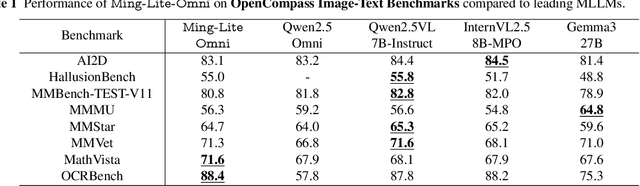
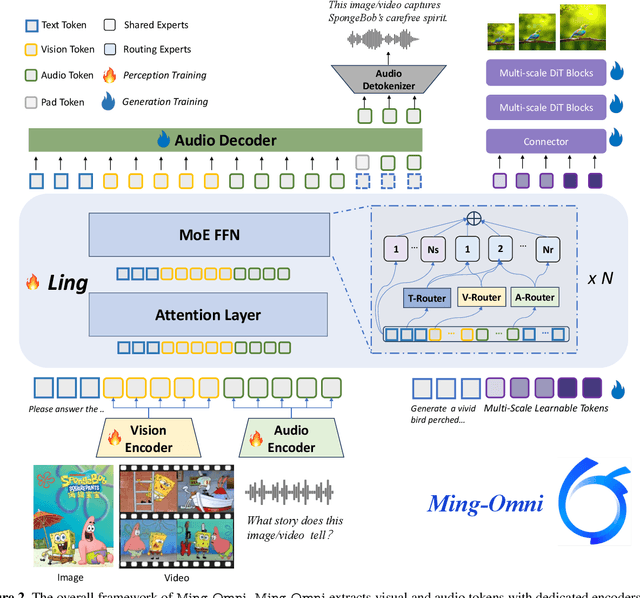
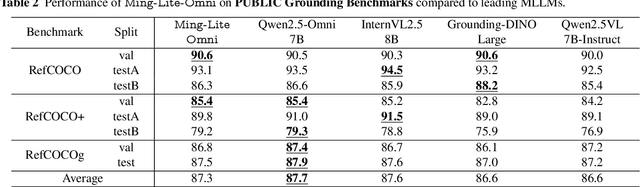
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
EvoMoE: Expert Evolution in Mixture of Experts for Multimodal Large Language Models
May 28, 2025Recent advancements have shown that the Mixture of Experts (MoE) approach significantly enhances the capacity of large language models (LLMs) and improves performance on downstream tasks. Building on these promising results, multi-modal large language models (MLLMs) have increasingly adopted MoE techniques. However, existing multi-modal MoE tuning methods typically face two key challenges: expert uniformity and router rigidity. Expert uniformity occurs because MoE experts are often initialized by simply replicating the FFN parameters from LLMs, leading to homogenized expert functions and weakening the intended diversification of the MoE architecture. Meanwhile, router rigidity stems from the prevalent use of static linear routers for expert selection, which fail to distinguish between visual and textual tokens, resulting in similar expert distributions for image and text. To address these limitations, we propose EvoMoE, an innovative MoE tuning framework. EvoMoE introduces a meticulously designed expert initialization strategy that progressively evolves multiple robust experts from a single trainable expert, a process termed expert evolution that specifically targets severe expert homogenization. Furthermore, we introduce the Dynamic Token-aware Router (DTR), a novel routing mechanism that allocates input tokens to appropriate experts based on their modality and intrinsic token values. This dynamic routing is facilitated by hypernetworks, which dynamically generate routing weights tailored for each individual token. Extensive experiments demonstrate that EvoMoE significantly outperforms other sparse MLLMs across a variety of multi-modal benchmarks, including MME, MMBench, TextVQA, and POPE. Our results highlight the effectiveness of EvoMoE in enhancing the performance of MLLMs by addressing the critical issues of expert uniformity and router rigidity.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025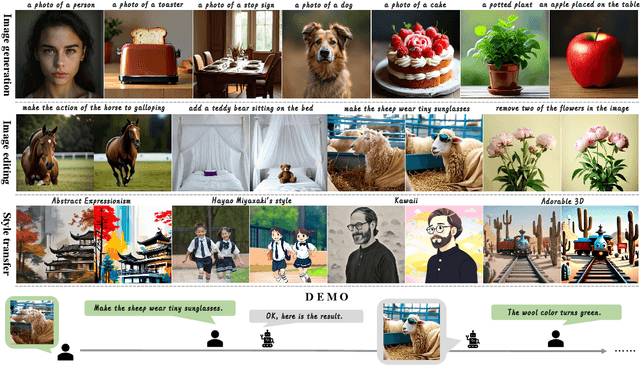

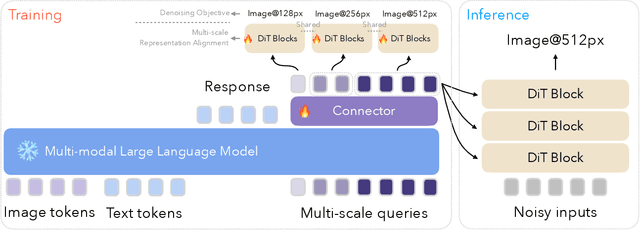
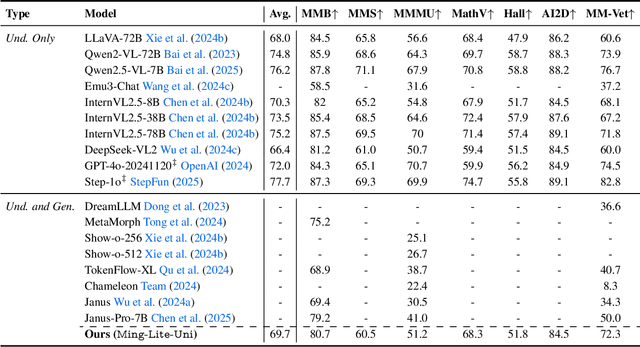
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
From Mapping to Composing: A Two-Stage Framework for Zero-shot Composed Image Retrieval
Apr 25, 2025Composed Image Retrieval (CIR) is a challenging multimodal task that retrieves a target image based on a reference image and accompanying modification text. Due to the high cost of annotating CIR triplet datasets, zero-shot (ZS) CIR has gained traction as a promising alternative. Existing studies mainly focus on projection-based methods, which map an image to a single pseudo-word token. However, these methods face three critical challenges: (1) insufficient pseudo-word token representation capacity, (2) discrepancies between training and inference phases, and (3) reliance on large-scale synthetic data. To address these issues, we propose a two-stage framework where the training is accomplished from mapping to composing. In the first stage, we enhance image-to-pseudo-word token learning by introducing a visual semantic injection module and a soft text alignment objective, enabling the token to capture richer and fine-grained image information. In the second stage, we optimize the text encoder using a small amount of synthetic triplet data, enabling it to effectively extract compositional semantics by combining pseudo-word tokens with modification text for accurate target image retrieval. The strong visual-to-pseudo mapping established in the first stage provides a solid foundation for the second stage, making our approach compatible with both high- and low-quality synthetic data, and capable of achieving significant performance gains with only a small amount of synthetic data. Extensive experiments were conducted on three public datasets, achieving superior performance compared to existing approaches.
LLaVA-CMoE: Towards Continual Mixture of Experts for Large Vision-Language Models
Mar 27, 2025



Although applying Mixture of Experts to large language models for learning new tasks is widely regarded as an effective strategy for continuous learning, there still remain two major challenges: (1) As the number of tasks grows, simple parameter expansion strategies can lead to excessively large models. (2) Modifying the parameters of the existing router results in the erosion of previously acquired knowledge. In this paper, we present an innovative framework named LLaVA-CMoE, which is a continuous Mixture of Experts (MoE) architecture without any replay data. Specifically, we have developed a method called Probe-Guided Knowledge Extension (PGKE), which employs probe experts to assess whether additional knowledge is required for a specific layer. This approach enables the model to adaptively expand its network parameters based on task distribution, thereby significantly improving the efficiency of parameter expansion. Additionally, we introduce a hierarchical routing algorithm called Probabilistic Task Locator (PTL), where high-level routing captures inter-task information and low-level routing focuses on intra-task details, ensuring that new task experts do not interfere with existing ones. Our experiments shows that our efficient architecture has substantially improved model performance on the Coin benchmark while maintaining a reasonable parameter count.
SegAgent: Exploring Pixel Understanding Capabilities in MLLMs by Imitating Human Annotator Trajectories
Mar 11, 2025While MLLMs have demonstrated adequate image understanding capabilities, they still struggle with pixel-level comprehension, limiting their practical applications. Current evaluation tasks like VQA and visual grounding remain too coarse to assess fine-grained pixel comprehension accurately. Though segmentation is foundational for pixel-level understanding, existing methods often require MLLMs to generate implicit tokens, decoded through external pixel decoders. This approach disrupts the MLLM's text output space, potentially compromising language capabilities and reducing flexibility and extensibility, while failing to reflect the model's intrinsic pixel-level understanding. Thus, we introduce the Human-Like Mask Annotation Task (HLMAT), a new paradigm where MLLMs mimic human annotators using interactive segmentation tools. Modeling segmentation as a multi-step Markov Decision Process, HLMAT enables MLLMs to iteratively generate text-based click points, achieving high-quality masks without architectural changes or implicit tokens. Through this setup, we develop SegAgent, a model fine-tuned on human-like annotation trajectories, which achieves performance comparable to state-of-the-art (SOTA) methods and supports additional tasks like mask refinement and annotation filtering. HLMAT provides a protocol for assessing fine-grained pixel understanding in MLLMs and introduces a vision-centric, multi-step decision-making task that facilitates exploration of MLLMs' visual reasoning abilities. Our adaptations of policy improvement method StaR and PRM-guided tree search further enhance model robustness in complex segmentation tasks, laying a foundation for future advancements in fine-grained visual perception and multi-step decision-making for MLLMs.
M2-omni: Advancing Omni-MLLM for Comprehensive Modality Support with Competitive Performance
Feb 26, 2025We present M2-omni, a cutting-edge, open-source omni-MLLM that achieves competitive performance to GPT-4o. M2-omni employs a unified multimodal sequence modeling framework, which empowers Large Language Models(LLMs) to acquire comprehensive cross-modal understanding and generation capabilities. Specifically, M2-omni can process arbitrary combinations of audio, video, image, and text modalities as input, generating multimodal sequences interleaving with audio, image, or text outputs, thereby enabling an advanced and interactive real-time experience. The training of such an omni-MLLM is challenged by significant disparities in data quantity and convergence rates across modalities. To address these challenges, we propose a step balance strategy during pre-training to handle the quantity disparities in modality-specific data. Additionally, a dynamically adaptive balance strategy is introduced during the instruction tuning stage to synchronize the modality-wise training progress, ensuring optimal convergence. Notably, we prioritize preserving strong performance on pure text tasks to maintain the robustness of M2-omni's language understanding capability throughout the training process. To our best knowledge, M2-omni is currently a very competitive open-source model to GPT-4o, characterized by its comprehensive modality and task support, as well as its exceptional performance. We expect M2-omni will advance the development of omni-MLLMs, thus facilitating future research in this domain.