 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization
Mar 30, 2026We present Kernel-Smith, a framework for high-performance GPU kernel and operator generation that combines a stable evaluation-driven evolutionary agent with an evolution-oriented post-training recipe. On the agent side, Kernel-Smith maintains a population of executable candidates and iteratively improves them using an archive of top-performing and diverse programs together with structured execution feedback on compilation, correctness, and speedup. To make this search reliable, we build backend-specific evaluation services for Triton on NVIDIA GPUs and Maca on MetaX GPUs. On the training side, we convert long-horizon evolution trajectories into step-centric supervision and reinforcement learning signals by retaining correctness-preserving, high-gain revisions, so that the model is optimized as a strong local improver inside the evolutionary loop rather than as a one-shot generator. Under a unified evolutionary protocol, Kernel-Smith-235B-RL achieves state-of-the-art overall performance on KernelBench with Nvidia Triton backend, attaining the best average speedup ratio and outperforming frontier proprietary models including Gemini-3.0-pro and Claude-4.6-opus. We further validate the framework on the MetaX MACA backend, where our Kernel-Smith-MACA-30B surpasses large-scale counterparts such as DeepSeek-V3.2-think and Qwen3-235B-2507-think, highlighting potential for seamless adaptation across heterogeneous platforms. Beyond benchmark results, the same workflow produces upstream contributions to production systems including SGLang and LMDeploy, demonstrating that LLM-driven kernel optimization can transfer from controlled evaluation to practical deployment.
Enhancing the Outcome Reward-based RL Training of MLLMs with Self-Consistency Sampling
Nov 13, 2025



Outcome-reward reinforcement learning (RL) is a common and increasingly significant way to refine the step-by-step reasoning of multimodal large language models (MLLMs). In the multiple-choice setting - a dominant format for multimodal reasoning benchmarks - the paradigm faces a significant yet often overlooked obstacle: unfaithful trajectories that guess the correct option after a faulty chain of thought receive the same reward as genuine reasoning, which is a flaw that cannot be ignored. We propose Self-Consistency Sampling (SCS) to correct this issue. For each question, SCS (i) introduces small visual perturbations and (ii) performs repeated truncation and resampling of an initial trajectory; agreement among the resulting trajectories yields a differentiable consistency score that down-weights unreliable traces during policy updates. Based on Qwen2.5-VL-7B-Instruct, plugging SCS into RLOO, GRPO, and REINFORCE++ series improves accuracy by up to 7.7 percentage points on six multimodal benchmarks with negligible extra computation. SCS also yields notable gains on both Qwen2.5-VL-3B-Instruct and InternVL3-8B, offering a simple, general remedy for outcome-reward RL in MLLMs.
VisuLogic: A Benchmark for Evaluating Visual Reasoning in Multi-modal Large Language Models
Apr 21, 2025



Visual reasoning is a core component of human intelligence and a critical capability for advanced multimodal models. Yet current reasoning evaluations of multimodal large language models (MLLMs) often rely on text descriptions and allow language-based reasoning shortcuts, failing to measure genuine vision-centric reasoning. To address this, we introduce VisuLogic: a benchmark of 1,000 human-verified problems across six categories (e.g., quantitative shifts, spatial relations, attribute comparisons). These various types of questions can be evaluated to assess the visual reasoning capabilities of MLLMs from multiple perspectives. We evaluate leading MLLMs on this benchmark and analyze their results to identify common failure modes. Most models score below 30% accuracy-only slightly above the 25% random baseline and far below the 51.4% achieved by humans-revealing significant gaps in visual reasoning. Furthermore, we provide a supplementary training dataset and a reinforcement-learning baseline to support further progress.
Power-LLaVA: Large Language and Vision Assistant for Power Transmission Line Inspection
Jul 27, 2024The inspection of power transmission line has achieved notable achievements in the past few years, primarily due to the integration of deep learning technology. However, current inspection approaches continue to encounter difficulties in generalization and intelligence, which restricts their further applicability. In this paper, we introduce Power-LLaVA, the first large language and vision assistant designed to offer professional and reliable inspection services for power transmission line by engaging in dialogues with humans. Moreover, we also construct a large-scale and high-quality dataset specialized for the inspection task. By employing a two-stage training strategy on the constructed dataset, Power-LLaVA demonstrates exceptional performance at a comparatively low training cost. Extensive experiments further prove the great capabilities of Power-LLaVA within the realm of power transmission line inspection. Code shall be released.
Complementary Relation Contrastive Distillation
Mar 29, 2021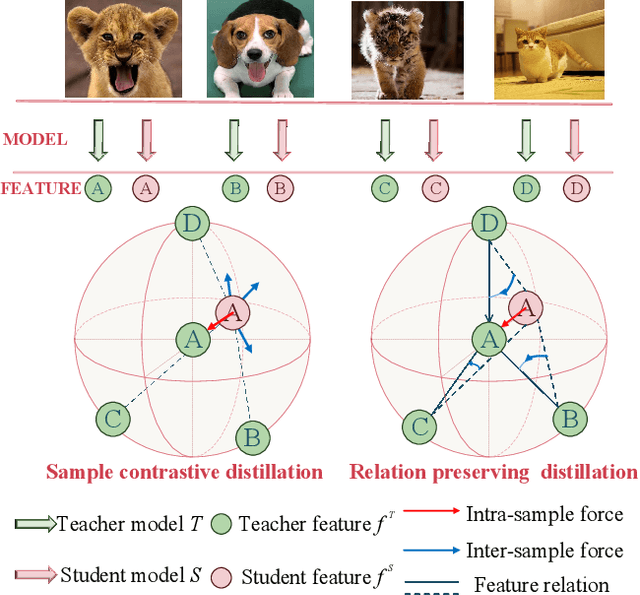
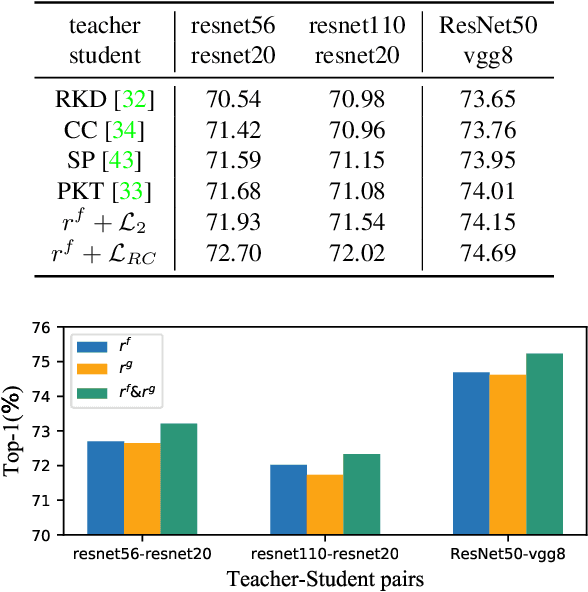
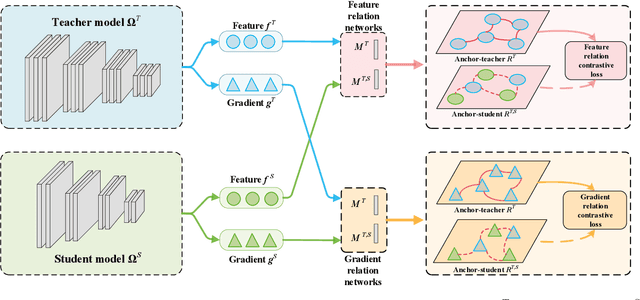

Knowledge distillation aims to transfer representation ability from a teacher model to a student model. Previous approaches focus on either individual representation distillation or inter-sample similarity preservation. While we argue that the inter-sample relation conveys abundant information and needs to be distilled in a more effective way. In this paper, we propose a novel knowledge distillation method, namely Complementary Relation Contrastive Distillation (CRCD), to transfer the structural knowledge from the teacher to the student. Specifically, we estimate the mutual relation in an anchor-based way and distill the anchor-student relation under the supervision of its corresponding anchor-teacher relation. To make it more robust, mutual relations are modeled by two complementary elements: the feature and its gradient. Furthermore, the low bound of mutual information between the anchor-teacher relation distribution and the anchor-student relation distribution is maximized via relation contrastive loss, which can distill both the sample representation and the inter-sample relations. Experiments on different benchmarks demonstrate the effectiveness of our proposed CRCD.