 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring from Logits: Exploring Best Practices for Decoding-Free Generative Candidate Selection
Jan 28, 2025



Generative Language Models rely on autoregressive decoding to produce the output sequence token by token. Many tasks such as preference optimization, require the model to produce task-level output consisting of multiple tokens directly by selecting candidates from a pool as predictions. Determining a task-level prediction from candidates using the ordinary token-level decoding mechanism is constrained by time-consuming decoding and interrupted gradients by discrete token selection. Existing works have been using decoding-free candidate selection methods to obtain candidate probability from initial output logits over vocabulary. Though these estimation methods are widely used, they are not systematically evaluated, especially on end tasks. We introduce an evaluation of a comprehensive collection of decoding-free candidate selection approaches on a comprehensive set of tasks, including five multiple-choice QA tasks with a small candidate pool and four clinical decision tasks with a massive amount of candidates, some with 10k+ options. We evaluate the estimation methods paired with a wide spectrum of foundation LMs covering different architectures, sizes and training paradigms. The results and insights from our analysis inform the future model design.
Memorize and Rank: Elevating Large Language Models for Clinical Diagnosis Prediction
Jan 28, 2025Clinical diagnosis prediction models, when provided with a patient's medical history, aim to detect potential diseases early, facilitating timely intervention and improving prognostic outcomes. However, the inherent scarcity of patient data and large disease candidate space often pose challenges in developing satisfactory models for this intricate task. The exploration of leveraging Large Language Models (LLMs) for encapsulating clinical decision processes has been limited. We introduce MERA, a clinical diagnosis prediction model that bridges pertaining natural language knowledge with medical practice. We apply hierarchical contrastive learning on a disease candidate ranking list to alleviate the large decision space issue. With concept memorization through fine-tuning, we bridge the natural language clinical knowledge with medical codes. Experimental results on MIMIC-III and IV datasets show that MERA achieves the state-of-the-art diagnosis prediction performance and dramatically elevates the diagnosis prediction capabilities of generative LMs.
Tumor Detection, Segmentation and Classification Challenge on Automated 3D Breast Ultrasound: The TDSC-ABUS Challenge
Jan 26, 2025



Breast cancer is one of the most common causes of death among women worldwide. Early detection helps in reducing the number of deaths. Automated 3D Breast Ultrasound (ABUS) is a newer approach for breast screening, which has many advantages over handheld mammography such as safety, speed, and higher detection rate of breast cancer. Tumor detection, segmentation, and classification are key components in the analysis of medical images, especially challenging in the context of 3D ABUS due to the significant variability in tumor size and shape, unclear tumor boundaries, and a low signal-to-noise ratio. The lack of publicly accessible, well-labeled ABUS datasets further hinders the advancement of systems for breast tumor analysis. Addressing this gap, we have organized the inaugural Tumor Detection, Segmentation, and Classification Challenge on Automated 3D Breast Ultrasound 2023 (TDSC-ABUS2023). This initiative aims to spearhead research in this field and create a definitive benchmark for tasks associated with 3D ABUS image analysis. In this paper, we summarize the top-performing algorithms from the challenge and provide critical analysis for ABUS image examination. We offer the TDSC-ABUS challenge as an open-access platform at https://tdsc-abus2023.grand-challenge.org/ to benchmark and inspire future developments in algorithmic research.
Fusion of Millimeter-wave Radar and Pulse Oximeter Data for Low-burden Diagnosis of Obstructive Sleep Apnea-Hypopnea Syndrome
Jan 25, 2025



Objective: The aim of the study is to develop a novel method for improved diagnosis of obstructive sleep apnea-hypopnea syndrome (OSAHS) in clinical or home settings, with the focus on achieving diagnostic performance comparable to the gold-standard polysomnography (PSG) with significantly reduced monitoring burden. Methods: We propose a method using millimeter-wave radar and pulse oximeter for OSAHS diagnosis (ROSA). It contains a sleep apnea-hypopnea events (SAE) detection network, which directly predicts the temporal localization of SAE, and a sleep staging network, which predicts the sleep stages throughout the night, based on radar signals. It also fuses oxygen saturation (SpO2) information from the pulse oximeter to adjust the score of SAE detected by radar. Results: Experimental results on a real-world dataset (>800 hours of overnight recordings, 100 subjects) demonstrated high agreement (ICC=0.9870) on apnea-hypopnea index (AHI) between ROSA and PSG. ROSA also exhibited excellent diagnostic performance, exceeding 90% in accuracy across AHI diagnostic thresholds of 5, 15 and 30 events/h. Conclusion: ROSA improves diagnostic accuracy by fusing millimeter-wave radar and pulse oximeter data. It provides a reliable and low-burden solution for OSAHS diagnosis. Significance: ROSA addresses the limitations of high complexity and monitoring burden associated with traditional PSG. The high accuracy and low burden of ROSA show its potential to improve the accessibility of OSAHS diagnosis among population.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025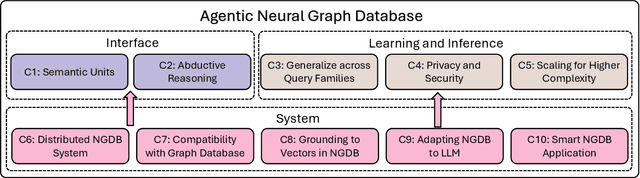
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
A Multi-annotated and Multi-modal Dataset for Wide-angle Video Quality Assessment
Jan 21, 2025Wide-angle video is favored for its wide viewing angle and ability to capture a large area of scenery, making it an ideal choice for sports and adventure recording. However, wide-angle video is prone to deformation, exposure and other distortions, resulting in poor video quality and affecting the perception and experience, which may seriously hinder its application in fields such as competitive sports. Up to now, few explorations focus on the quality assessment issue of wide-angle video. This deficiency primarily stems from the absence of a specialized dataset for wide-angle videos. To bridge this gap, we construct the first Multi-annotated and multi-modal Wide-angle Video quality assessment (MWV) dataset. Then, the performances of state-of-the-art video quality methods on the MWV dataset are investigated by inter-dataset testing and intra-dataset testing. Experimental results show that these methods impose significant limitations on their applicability.
MedFILIP: Medical Fine-grained Language-Image Pre-training
Jan 18, 2025Medical vision-language pretraining (VLP) that leverages naturally-paired medical image-report data is crucial for medical image analysis. However, existing methods struggle to accurately characterize associations between images and diseases, leading to inaccurate or incomplete diagnostic results. In this work, we propose MedFILIP, a fine-grained VLP model, introduces medical image-specific knowledge through contrastive learning, specifically: 1) An information extractor based on a large language model is proposed to decouple comprehensive disease details from reports, which excels in extracting disease deals through flexible prompt engineering, thereby effectively reducing text complexity while retaining rich information at a tiny cost. 2) A knowledge injector is proposed to construct relationships between categories and visual attributes, which help the model to make judgments based on image features, and fosters knowledge extrapolation to unfamiliar disease categories. 3) A semantic similarity matrix based on fine-grained annotations is proposed, providing smoother, information-richer labels, thus allowing fine-grained image-text alignment. 4) We validate MedFILIP on numerous datasets, e.g., RSNA-Pneumonia, NIH ChestX-ray14, VinBigData, and COVID-19. For single-label, multi-label, and fine-grained classification, our model achieves state-of-the-art performance, the classification accuracy has increased by a maximum of 6.69\%. The code is available in https://github.com/PerceptionComputingLab/MedFILIP.
OpenCSG Chinese Corpus: A Series of High-quality Chinese Datasets for LLM Training
Jan 14, 2025Large language models (LLMs) have demonstrated remarkable capabilities, but their success heavily relies on the quality of pretraining corpora. For Chinese LLMs, the scarcity of high-quality Chinese datasets presents a significant challenge, often limiting their performance. To address this issue, we propose the OpenCSG Chinese Corpus, a series of high-quality datasets specifically designed for LLM pretraining, post-training, and fine-tuning. This corpus includes Fineweb-edu-chinese, Fineweb-edu-chinese-v2, Cosmopedia-chinese, and Smoltalk-chinese, each with distinct characteristics: Fineweb-edu datasets focus on filtered, high-quality content derived from diverse Chinese web sources; Cosmopedia-chinese provides synthetic, textbook-style data for knowledge-intensive training; and Smoltalk-chinese emphasizes stylistic and diverse chat-format data. The OpenCSG Chinese Corpus is characterized by its high-quality text, diverse coverage across domains, and scalable, reproducible data curation processes. Additionally, we conducted extensive experimental analyses, including evaluations on smaller parameter models, which demonstrated significant performance improvements in tasks such as C-Eval, showcasing the effectiveness of the corpus for training Chinese LLMs.
On the Computational Capability of Graph Neural Networks: A Circuit Complexity Bound Perspective
Jan 11, 2025Graph Neural Networks (GNNs) have become the standard approach for learning and reasoning over relational data, leveraging the message-passing mechanism that iteratively propagates node embeddings through graph structures. While GNNs have achieved significant empirical success, their theoretical limitations remain an active area of research. Existing studies primarily focus on characterizing GNN expressiveness through Weisfeiler-Lehman (WL) graph isomorphism tests. In this paper, we take a fundamentally different approach by exploring the computational limitations of GNNs through the lens of circuit complexity. Specifically, we analyze the circuit complexity of common GNN architectures and prove that under constraints of constant-depth layers, linear or sublinear embedding sizes, and polynomial precision, GNNs cannot solve key problems such as graph connectivity and graph isomorphism unless $\mathsf{TC}^0 = \mathsf{NC}^1$. These results reveal the intrinsic expressivity limitations of GNNs behind their empirical success and introduce a novel framework for analyzing GNN expressiveness that can be extended to a broader range of GNN models and graph decision problems.
Target Detection in ISAC Systems with Active RISs: A Multi-Perspective Observation Approach
Jan 11, 2025



Integrated sensing and communication (ISAC) has emerged as a transformative technology for 6G networks, enabling the seamless integration of communication and sensing functionalities. Reconfigurable intelligent surfaces (RIS), with their capability to adaptively reconfigure the radio environment, have shown significant potential in enhancing communication quality and enabling advanced cooperative sensing. This paper investigates a multi-RIS-assisted ISAC system and introduces a novel multi-perspective observation framework that leverages the diversity of multiple observation paths, each exhibiting distinct spatial, delay, and Doppler characteristics for both target and clutter. The proposed framework integrates symbol-level precoding (SLP) and space-time adaptive processing (STAP) to fully exploit the benefits of multi-perspective observations, enabling superior target-clutter separation and significantly improving detection accuracy. The objective is to jointly design the transmit waveform, reflection coefficients of multiple active RISs, and spatial-temporal receive filters to maximize the radar output signal-to-clutter-plus-noise ratio (SCNR) for target detection, while ensuring the quality-of-service (QoS) requirements of communication users. To address the resulting non-convex optimization problem, an effective iterative algorithm is developed, combining fractional programming (FP), majorization-minimization (MM), and the alternating direction method of multipliers (ADMM). Extensive simulation results validate the effectiveness of the proposed multi-perspective observation strategy, demonstrating its advantages in improving target detection performance in challenging environments.