 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructuring the Unstructured: A Systematic Review of Text-to-Structure Generation for Agentic AI with a Universal Evaluation Framework
Aug 17, 2025



The evolution of AI systems toward agentic operation and context-aware retrieval necessitates transforming unstructured text into structured formats like tables, knowledge graphs, and charts. While such conversions enable critical applications from summarization to data mining, current research lacks a comprehensive synthesis of methodologies, datasets, and metrics. This systematic review examines text-to-structure techniques and the encountered challenges, evaluates current datasets and assessment criteria, and outlines potential directions for future research. We also introduce a universal evaluation framework for structured outputs, establishing text-to-structure as foundational infrastructure for next-generation AI systems.
SessionIntentBench: A Multi-task Inter-session Intention-shift Modeling Benchmark for E-commerce Customer Behavior Understanding
Jul 27, 2025Session history is a common way of recording user interacting behaviors throughout a browsing activity with multiple products. For example, if an user clicks a product webpage and then leaves, it might because there are certain features that don't satisfy the user, which serve as an important indicator of on-the-spot user preferences. However, all prior works fail to capture and model customer intention effectively because insufficient information exploitation and only apparent information like descriptions and titles are used. There is also a lack of data and corresponding benchmark for explicitly modeling intention in E-commerce product purchase sessions. To address these issues, we introduce the concept of an intention tree and propose a dataset curation pipeline. Together, we construct a sibling multimodal benchmark, SessionIntentBench, that evaluates L(V)LMs' capability on understanding inter-session intention shift with four subtasks. With 1,952,177 intention entries, 1,132,145 session intention trajectories, and 13,003,664 available tasks mined using 10,905 sessions, we provide a scalable way to exploit the existing session data for customer intention understanding. We conduct human annotations to collect ground-truth label for a subset of collected data to form an evaluation gold set. Extensive experiments on the annotated data further confirm that current L(V)LMs fail to capture and utilize the intention across the complex session setting. Further analysis show injecting intention enhances LLMs' performances.
Legal Rule Induction: Towards Generalizable Principle Discovery from Analogous Judicial Precedents
May 20, 2025Legal rules encompass not only codified statutes but also implicit adjudicatory principles derived from precedents that contain discretionary norms, social morality, and policy. While computational legal research has advanced in applying established rules to cases, inducing legal rules from judicial decisions remains understudied, constrained by limitations in model inference efficacy and symbolic reasoning capability. The advent of Large Language Models (LLMs) offers unprecedented opportunities for automating the extraction of such latent principles, yet progress is stymied by the absence of formal task definitions, benchmark datasets, and methodologies. To address this gap, we formalize Legal Rule Induction (LRI) as the task of deriving concise, generalizable doctrinal rules from sets of analogous precedents, distilling their shared preconditions, normative behaviors, and legal consequences. We introduce the first LRI benchmark, comprising 5,121 case sets (38,088 Chinese cases in total) for model tuning and 216 expert-annotated gold test sets. Experimental results reveal that: 1) State-of-the-art LLMs struggle with over-generalization and hallucination; 2) Training on our dataset markedly enhances LLMs capabilities in capturing nuanced rule patterns across similar cases.
From Automation to Autonomy: A Survey on Large Language Models in Scientific Discovery
May 19, 2025Large Language Models (LLMs) are catalyzing a paradigm shift in scientific discovery, evolving from task-specific automation tools into increasingly autonomous agents and fundamentally redefining research processes and human-AI collaboration. This survey systematically charts this burgeoning field, placing a central focus on the changing roles and escalating capabilities of LLMs in science. Through the lens of the scientific method, we introduce a foundational three-level taxonomy-Tool, Analyst, and Scientist-to delineate their escalating autonomy and evolving responsibilities within the research lifecycle. We further identify pivotal challenges and future research trajectories such as robotic automation, self-improvement, and ethical governance. Overall, this survey provides a conceptual architecture and strategic foresight to navigate and shape the future of AI-driven scientific discovery, fostering both rapid innovation and responsible advancement. Github Repository: https://github.com/HKUST-KnowComp/Awesome-LLM-Scientific-Discovery.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025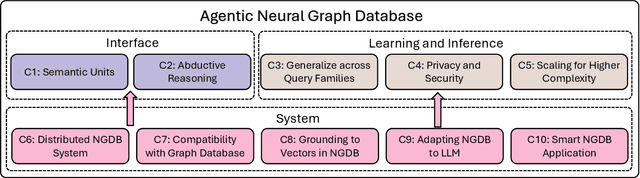
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
Enhancing Transformers for Generalizable First-Order Logical Entailment
Jan 01, 2025



Transformers, as a fundamental deep learning architecture, have demonstrated remarkable capabilities in reasoning. This paper investigates the generalizable first-order logical reasoning ability of transformers with their parameterized knowledge and explores ways to improve it. The first-order reasoning capability of transformers is assessed through their ability to perform first-order logical entailment, which is quantitatively measured by their performance in answering knowledge graph queries. We establish connections between (1) two types of distribution shifts studied in out-of-distribution generalization and (2) the unseen knowledge and query settings discussed in the task of knowledge graph query answering, enabling a characterization of fine-grained generalizability. Results on our comprehensive dataset show that transformers outperform previous methods specifically designed for this task and provide detailed empirical evidence on the impact of input query syntax, token embedding, and transformer architectures on the reasoning capability of transformers. Interestingly, our findings reveal a mismatch between positional encoding and other design choices in transformer architectures employed in prior practices. This discovery motivates us to propose a more sophisticated, logic-aware architecture, TEGA, to enhance the capability for generalizable first-order logical entailment in transformers.
Persona Knowledge-Aligned Prompt Tuning Method for Online Debate
Oct 05, 2024



Debate is the process of exchanging viewpoints or convincing others on a particular issue. Recent research has provided empirical evidence that the persuasiveness of an argument is determined not only by language usage but also by communicator characteristics. Researchers have paid much attention to aspects of languages, such as linguistic features and discourse structures, but combining argument persuasiveness and impact with the social personae of the audience has not been explored due to the difficulty and complexity. We have observed the impressive simulation and personification capability of ChatGPT, indicating a giant pre-trained language model may function as an individual to provide personae and exert unique influences based on diverse background knowledge. Therefore, we propose a persona knowledge-aligned framework for argument quality assessment tasks from the audience side. This is the first work that leverages the emergence of ChatGPT and injects such audience personae knowledge into smaller language models via prompt tuning. The performance of our pipeline demonstrates significant and consistent improvement compared to competitive architectures.
Evaluating and Enhancing LLMs Agent based on Theory of Mind in Guandan: A Multi-Player Cooperative Game under Imperfect Information
Aug 05, 2024



Large language models (LLMs) have shown success in handling simple games with imperfect information and enabling multi-agent coordination, but their ability to facilitate practical collaboration against other agents in complex, imperfect information environments, especially in a non-English environment, still needs to be explored. This study investigates the applicability of knowledge acquired by open-source and API-based LLMs to sophisticated text-based games requiring agent collaboration under imperfect information, comparing their performance to established baselines using other types of agents. We propose a Theory of Mind (ToM) planning technique that allows LLM agents to adapt their strategy against various adversaries using only game rules, current state, and historical context as input. An external tool was incorporated to mitigate the challenge of dynamic and extensive action spaces in this card game. Our results show that although a performance gap exists between current LLMs and state-of-the-art reinforcement learning (RL) models, LLMs demonstrate ToM capabilities in this game setting. It consistently improves their performance against opposing agents, suggesting their ability to understand the actions of allies and adversaries and establish collaboration with allies. To encourage further research and understanding, we have made our codebase openly accessible.
GoldCoin: Grounding Large Language Models in Privacy Laws via Contextual Integrity Theory
Jun 17, 2024Privacy issues arise prominently during the inappropriate transmission of information between entities. Existing research primarily studies privacy by exploring various privacy attacks, defenses, and evaluations within narrowly predefined patterns, while neglecting that privacy is not an isolated, context-free concept limited to traditionally sensitive data (e.g., social security numbers), but intertwined with intricate social contexts that complicate the identification and analysis of potential privacy violations. The advent of Large Language Models (LLMs) offers unprecedented opportunities for incorporating the nuanced scenarios outlined in privacy laws to tackle these complex privacy issues. However, the scarcity of open-source relevant case studies restricts the efficiency of LLMs in aligning with specific legal statutes. To address this challenge, we introduce a novel framework, GoldCoin, designed to efficiently ground LLMs in privacy laws for judicial assessing privacy violations. Our framework leverages the theory of contextual integrity as a bridge, creating numerous synthetic scenarios grounded in relevant privacy statutes (e.g., HIPAA), to assist LLMs in comprehending the complex contexts for identifying privacy risks in the real world. Extensive experimental results demonstrate that GoldCoin markedly enhances LLMs' capabilities in recognizing privacy risks across real court cases, surpassing the baselines on different judicial tasks.
Text-Tuple-Table: Towards Information Integration in Text-to-Table Generation via Global Tuple Extraction
Apr 22, 2024



The task of condensing large chunks of textual information into concise and structured tables has gained attention recently due to the emergence of Large Language Models (LLMs) and their potential benefit for downstream tasks, such as text summarization and text mining. Previous approaches often generate tables that directly replicate information from the text, limiting their applicability in broader contexts, as text-to-table generation in real-life scenarios necessitates information extraction, reasoning, and integration. However, there is a lack of both datasets and methodologies towards this task. In this paper, we introduce LiveSum, a new benchmark dataset created for generating summary tables of competitions based on real-time commentary texts. We evaluate the performances of state-of-the-art LLMs on this task in both fine-tuning and zero-shot settings, and additionally propose a novel pipeline called $T^3$(Text-Tuple-Table) to improve their performances. Extensive experimental results demonstrate that LLMs still struggle with this task even after fine-tuning, while our approach can offer substantial performance gains without explicit training. Further analyses demonstrate that our method exhibits strong generalization abilities, surpassing previous approaches on several other text-to-table datasets. Our code and data can be found at https://github.com/HKUST-KnowComp/LiveSum-TTT.