 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Lung Nodule Synthesis via Histogram-Regularized Latent Diffusion Models
May 28, 2026While automated diagnosis systems have achieved remarkable success in computed tomography (CT)-based lung cancer screening, their development remains limited by the scarcity of diverse, annotated pulmonary nodule datasets. Diffusion-based generative models offer a promising strategy for data synthesis; however, many existing conditional approaches primarily optimize spatial reconstruction losses, which encourage voxel-wise similarity but may inadequately constrain lesion-level intensity distributions. As a result, these methods may produce over-smoothed texture profiles and underrepresent the distinct attenuation characteristics of different nodule subtypes, including solid, part-solid, and ground-glass nodules. To address this challenge, we propose a controllable latent diffusion model that synthesizes pulmonary nodules within full 3D CT volumes while accurately modeling nodule-specific intensity distributions. Specifically, rather than relying solely on spatial losses, we introduce a histogram-based regularization term that constrains voxel intensity distributions during the generative process. The model combines subtype, spatial mask, and Hounsfield unit (HU) histogram conditioning with the differentiable feature-space histogram regularization term to better align lesion-level intensity distributions, improving the visual plausibility and subtype consistency of synthesized nodules. Extensive experiments on lung CT data demonstrate that our framework achieves strong visual realism, validated through both quantitative metrics and a visual Turing test. Furthermore, when used for data augmentation, the generated nodules improve performance in downstream clinical tasks, particularly for underrepresented nodule subtypes, and show a potential benefit for subtype-informed malignancy classification.
CoCo-InEKF: State Estimation with Learned Contact Covariances in Dynamic, Contact-Rich Scenarios
May 14, 2026Robust state estimation for highly dynamic motion of legged robots remains challenging, especially in dynamic, contact-rich scenarios. Traditional approaches often rely on binary contact states that fail to capture the nuances of partial contact or directional slippage. This paper presents CoCo-InEKF, a differentiable invariant extended Kalman filter that utilizes continuous contact velocity covariances instead of binary contact states. These learned covariances allow the method to dynamically modulate contact confidence, accounting for more nuanced conditions ranging from firm contact to directional slippage or no contact. To predict these covariances for a set of predefined contact candidate points, we employ a lightweight neural network trained end-to-end using a state-error loss. This approach eliminates the need for heuristic ground-truth contact labels. In addition, we propose an automated contact candidate selection procedure and demonstrate that our method is insensitive to their exact placement. Experiments on a bipedal robot demonstrate a superior accuracy-efficiency tradeoff for linear velocity estimation, as well as improved filter consistency compared to baseline methods. This enables the robust execution of challenging motions, including dancing and complex ground interactions -- both in simulation and in the real world.
Specializing Foundation Models via Mixture of Low-Rank Experts for Comprehensive Head CT Analysis
Feb 28, 2026Foundation models pre-trained on large-scale datasets demonstrate strong transfer learning capabilities; however, their adaptation to complex multi-label diagnostic tasks-such as comprehensive head CT finding detection-remains understudied. Standard parameter-efficient fine-tuning methods such as LoRA apply uniform adaptations across pathology types, which may limit performance for diverse medical findings. We propose a Mixture of Low-Rank Experts (MoLRE) framework that extends LoRA with multiple specialized low-rank adapters and unsupervised soft routing. This approach enables conditional feature adaptation with less than 0.5% additional parameters and without explicit pathology supervision. We present a comprehensive benchmark of MoLRE across six state-of-the-art medical imaging foundation models spanning 2D and 3D architectures, general-domain, medical-domain, and head CT-specific pretraining, and model sizes ranging from 7M to 431M parameters. Using over 70,000 non-contrast head CT scans with 75 annotated findings-including hemorrhage, infarction, trauma, mass lesions, structural abnormalities, and chronic changes-our experiments demonstrate consistent performance improvements across all models. Gains vary substantially: general-purpose and medical-domain models show the largest improvements (DINOv3-Base: +4.6%; MedGemma: +4.3%), whereas 3D CT-specialized or very large models show more modest gains (+0.2-1.3%). The combination of MoLRE and MedGemma achieves the highest average detection AUC of 0.917. These findings highlight the importance of systematic benchmarking on target clinical tasks, as pretraining domain, architecture, and model scale interact in non-obvious ways.
Revisiting 2D Foundation Models for Scalable 3D Medical Image Classification
Dec 15, 2025



3D medical image classification is essential for modern clinical workflows. Medical foundation models (FMs) have emerged as a promising approach for scaling to new tasks, yet current research suffers from three critical pitfalls: data-regime bias, suboptimal adaptation, and insufficient task coverage. In this paper, we address these pitfalls and introduce AnyMC3D, a scalable 3D classifier adapted from 2D FMs. Our method scales efficiently to new tasks by adding only lightweight plugins (about 1M parameters per task) on top of a single frozen backbone. This versatile framework also supports multi-view inputs, auxiliary pixel-level supervision, and interpretable heatmap generation. We establish a comprehensive benchmark of 12 tasks covering diverse pathologies, anatomies, and modalities, and systematically analyze state-of-the-art 3D classification techniques. Our analysis reveals key insights: (1) effective adaptation is essential to unlock FM potential, (2) general-purpose FMs can match medical-specific FMs if properly adapted, and (3) 2D-based methods surpass 3D architectures for 3D classification. For the first time, we demonstrate the feasibility of achieving state-of-the-art performance across diverse applications using a single scalable framework (including 1st place in the VLM3D challenge), eliminating the need for separate task-specific models.
The Missing Piece: A Case for Pre-Training in 3D Medical Object Detection
Sep 19, 2025Large-scale pre-training holds the promise to advance 3D medical object detection, a crucial component of accurate computer-aided diagnosis. Yet, it remains underexplored compared to segmentation, where pre-training has already demonstrated significant benefits. Existing pre-training approaches for 3D object detection rely on 2D medical data or natural image pre-training, failing to fully leverage 3D volumetric information. In this work, we present the first systematic study of how existing pre-training methods can be integrated into state-of-the-art detection architectures, covering both CNNs and Transformers. Our results show that pre-training consistently improves detection performance across various tasks and datasets. Notably, reconstruction-based self-supervised pre-training outperforms supervised pre-training, while contrastive pre-training provides no clear benefit for 3D medical object detection. Our code is publicly available at: https://github.com/MIC-DKFZ/nnDetection-finetuning.
* MICCAI 2025
Advances in Automated Fetal Brain MRI Segmentation and Biometry: Insights from the FeTA 2024 Challenge
May 05, 2025


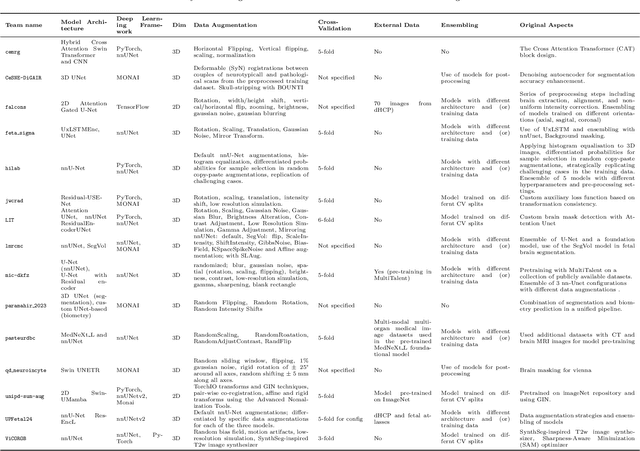
Accurate fetal brain tissue segmentation and biometric analysis are essential for studying brain development in utero. The FeTA Challenge 2024 advanced automated fetal brain MRI analysis by introducing biometry prediction as a new task alongside tissue segmentation. For the first time, our diverse multi-centric test set included data from a new low-field (0.55T) MRI dataset. Evaluation metrics were also expanded to include the topology-specific Euler characteristic difference (ED). Sixteen teams submitted segmentation methods, most of which performed consistently across both high- and low-field scans. However, longitudinal trends indicate that segmentation accuracy may be reaching a plateau, with results now approaching inter-rater variability. The ED metric uncovered topological differences that were missed by conventional metrics, while the low-field dataset achieved the highest segmentation scores, highlighting the potential of affordable imaging systems when paired with high-quality reconstruction. Seven teams participated in the biometry task, but most methods failed to outperform a simple baseline that predicted measurements based solely on gestational age, underscoring the challenge of extracting reliable biometric estimates from image data alone. Domain shift analysis identified image quality as the most significant factor affecting model generalization, with super-resolution pipelines also playing a substantial role. Other factors, such as gestational age, pathology, and acquisition site, had smaller, though still measurable, effects. Overall, FeTA 2024 offers a comprehensive benchmark for multi-class segmentation and biometry estimation in fetal brain MRI, underscoring the need for data-centric approaches, improved topological evaluation, and greater dataset diversity to enable clinically robust and generalizable AI tools.
Primus: Enforcing Attention Usage for 3D Medical Image Segmentation
Mar 03, 2025



Transformers have achieved remarkable success across multiple fields, yet their impact on 3D medical image segmentation remains limited with convolutional networks still dominating major benchmarks. In this work, we a) analyze current Transformer-based segmentation models and identify critical shortcomings, particularly their over-reliance on convolutional blocks. Further, we demonstrate that in some architectures, performance is unaffected by the absence of the Transformer, thereby demonstrating their limited effectiveness. To address these challenges, we move away from hybrid architectures and b) introduce a fully Transformer-based segmentation architecture, termed Primus. Primus leverages high-resolution tokens, combined with advances in positional embeddings and block design, to maximally leverage its Transformer blocks. Through these adaptations Primus surpasses current Transformer-based methods and competes with state-of-the-art convolutional models on multiple public datasets. By doing so, we create the first pure Transformer architecture and take a significant step towards making Transformers state-of-the-art for 3D medical image segmentation.
Multi-Class Segmentation of Aortic Branches and Zones in Computed Tomography Angiography: The AortaSeg24 Challenge
Feb 07, 2025



Multi-class segmentation of the aorta in computed tomography angiography (CTA) scans is essential for diagnosing and planning complex endovascular treatments for patients with aortic dissections. However, existing methods reduce aortic segmentation to a binary problem, limiting their ability to measure diameters across different branches and zones. Furthermore, no open-source dataset is currently available to support the development of multi-class aortic segmentation methods. To address this gap, we organized the AortaSeg24 MICCAI Challenge, introducing the first dataset of 100 CTA volumes annotated for 23 clinically relevant aortic branches and zones. This dataset was designed to facilitate both model development and validation. The challenge attracted 121 teams worldwide, with participants leveraging state-of-the-art frameworks such as nnU-Net and exploring novel techniques, including cascaded models, data augmentation strategies, and custom loss functions. We evaluated the submitted algorithms using the Dice Similarity Coefficient (DSC) and Normalized Surface Distance (NSD), highlighting the approaches adopted by the top five performing teams. This paper presents the challenge design, dataset details, evaluation metrics, and an in-depth analysis of the top-performing algorithms. The annotated dataset, evaluation code, and implementations of the leading methods are publicly available to support further research. All resources can be accessed at https://aortaseg24.grand-challenge.org.
Tumor Detection, Segmentation and Classification Challenge on Automated 3D Breast Ultrasound: The TDSC-ABUS Challenge
Jan 26, 2025



Breast cancer is one of the most common causes of death among women worldwide. Early detection helps in reducing the number of deaths. Automated 3D Breast Ultrasound (ABUS) is a newer approach for breast screening, which has many advantages over handheld mammography such as safety, speed, and higher detection rate of breast cancer. Tumor detection, segmentation, and classification are key components in the analysis of medical images, especially challenging in the context of 3D ABUS due to the significant variability in tumor size and shape, unclear tumor boundaries, and a low signal-to-noise ratio. The lack of publicly accessible, well-labeled ABUS datasets further hinders the advancement of systems for breast tumor analysis. Addressing this gap, we have organized the inaugural Tumor Detection, Segmentation, and Classification Challenge on Automated 3D Breast Ultrasound 2023 (TDSC-ABUS2023). This initiative aims to spearhead research in this field and create a definitive benchmark for tasks associated with 3D ABUS image analysis. In this paper, we summarize the top-performing algorithms from the challenge and provide critical analysis for ABUS image examination. We offer the TDSC-ABUS challenge as an open-access platform at https://tdsc-abus2023.grand-challenge.org/ to benchmark and inspire future developments in algorithmic research.
Unlocking the Potential of Digital Pathology: Novel Baselines for Compression
Dec 17, 2024



Digital pathology offers a groundbreaking opportunity to transform clinical practice in histopathological image analysis, yet faces a significant hurdle: the substantial file sizes of pathological Whole Slide Images (WSI). While current digital pathology solutions rely on lossy JPEG compression to address this issue, lossy compression can introduce color and texture disparities, potentially impacting clinical decision-making. While prior research addresses perceptual image quality and downstream performance independently of each other, we jointly evaluate compression schemes for perceptual and downstream task quality on four different datasets. In addition, we collect an initially uncompressed dataset for an unbiased perceptual evaluation of compression schemes. Our results show that deep learning models fine-tuned for perceptual quality outperform conventional compression schemes like JPEG-XL or WebP for further compression of WSI. However, they exhibit a significant bias towards the compression artifacts present in the training data and struggle to generalize across various compression schemes. We introduce a novel evaluation metric based on feature similarity between original files and compressed files that aligns very well with the actual downstream performance on the compressed WSI. Our metric allows for a general and standardized evaluation of lossy compression schemes and mitigates the requirement to independently assess different downstream tasks. Our study provides novel insights for the assessment of lossy compression schemes for WSI and encourages a unified evaluation of lossy compression schemes to accelerate the clinical uptake of digital pathology.