 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGPFN: Unlocking the Potential of Knowledge Graph Foundation Model via In-Context Learning
May 14, 2026Knowledge graph (KG) foundation models aim to generalize across graphs with unseen entities and relations by learning transferable relational structure. However, most existing methods primarily emphasize relation-level universality, while in-context learning, the other pillar of foundation models remains under-explored for KG reasoning. In KGs, context is inherently structured and heterogeneous: effective prediction requires conditioning on the local context around the query entities as well as the global context that summarizes how a relation behaves across many instances. We propose KGPFN, a KG foundation model using Prior-data Fitted Network that unifies transferable relational regularities with inference-time in-context learning from structured context. KGPFN first learns relation representations via message passing on relation graphs to capture cross-graph relational invariances. For query-specific reasoning, it encodes local neighborhoods using a multi-layer NBFNet as local context. To enable ICL at global scale, it constructs relation-specific global context by retrieving a large set of instances of the query relation together with their local neighborhoods, and aggregates them within a Prior-Data Fitted Network framework that combines feature-level and sample-level attention. Through multi-graph pretraining on diverse KGs, KGPFN learns when to instantiate reusable patterns and when to override them using contextual evidence. Experiments on 57 KG benchmarks demonstrate that KGPFN achieves strong adaptation to previously unseen graphs through in-context learning alone, consistently outperforming competitive fine-tuned KG foundation models. Our code is available at https://github.com/HKUST-KnowComp/KGPFN.
DeepRefine: Agent-Compiled Knowledge Refinement via Reinforcement Learning
May 11, 2026Agent-compiled knowledge bases provide persistent external knowledge for large language model (LLM) agents in open-ended, knowledge-intensive downstream tasks. Yet their quality is systematically limited by \emph{incompleteness}, \emph{incorrectness}, and \emph{redundancy}, manifested as missing evidence or cross-document links, low-confidence or imprecise claims, and ambiguous or coreference resolution issues. Such defects compound under iterative use, degrading retrieval fidelity and downstream task performance. We present \textbf{DeepRefine}, a general LLM-based reasoning model for \emph{agent-compiled knowledge refinement} that improves the quality of any pre-constructed knowledge bases with user queries to make it more suitable for the downstream tasks. DeepRefine performs multi-turn interactions with the knowledge base and conducts abductive diagnosis over interaction history, localizes likely defects, and executes targeted refinement actions for incremental knowledge base updates. To optimize refinement policies of DeepRefine without gold references, we introduce a Gain-Beyond-Draft (GBD) reward and train the reasoning process end-to-end via reinforcement learning. Extensive experiments demonstrate consistent downstream gains over strong baselines.
NGDB-Zoo: Towards Efficient and Scalable Neural Graph Databases Training
Feb 25, 2026Neural Graph Databases (NGDBs) facilitate complex logical reasoning over incomplete knowledge structures, yet their training efficiency and expressivity are constrained by rigid query-level batching and structure-exclusive embeddings. We present NGDB-Zoo, a unified framework that resolves these bottlenecks by synergizing operator-level training with semantic augmentation. By decoupling logical operators from query topologies, NGDB-Zoo transforms the training loop into a dynamically scheduled data-flow execution, enabling multi-stream parallelism and achieving a $1.8\times$ - $6.8\times$ throughput compared to baselines. Furthermore, we formalize a decoupled architecture to integrate high-dimensional semantic priors from Pre-trained Text Encoders (PTEs) without triggering I/O stalls or memory overflows. Extensive evaluations on six benchmarks, including massive graphs like ogbl-wikikg2 and ATLAS-Wiki, demonstrate that NGDB-Zoo maintains high GPU utilization across diverse logical patterns and significantly mitigates representation friction in hybrid neuro-symbolic reasoning.
NewtonBench: Benchmarking Generalizable Scientific Law Discovery in LLM Agents
Oct 08, 2025Large language models are emerging as powerful tools for scientific law discovery, a foundational challenge in AI-driven science. However, existing benchmarks for this task suffer from a fundamental methodological trilemma, forcing a trade-off between scientific relevance, scalability, and resistance to memorization. Furthermore, they oversimplify discovery as static function fitting, failing to capture the authentic scientific process of uncovering embedded laws through the interactive exploration of complex model systems. To address these critical gaps, we introduce NewtonBench, a benchmark comprising 324 scientific law discovery tasks across 12 physics domains. Our design mitigates the evaluation trilemma by using metaphysical shifts - systematic alterations of canonical laws - to generate a vast suite of problems that are scalable, scientifically relevant, and memorization-resistant. Moreover, we elevate the evaluation from static function fitting to interactive model discovery, requiring agents to experimentally probe simulated complex systems to uncover hidden principles. Our extensive experiment reveals a clear but fragile capability for discovery in frontier LLMs: this ability degrades precipitously with increasing system complexity and exhibits extreme sensitivity to observational noise. Notably, we uncover a paradoxical effect of tool assistance: providing a code interpreter can hinder more capable models by inducing a premature shift from exploration to exploitation, causing them to satisfice on suboptimal solutions. These results demonstrate that robust, generalizable discovery in complex, interactive environments remains the core challenge. By providing a scalable, robust, and scientifically authentic testbed, NewtonBench offers a crucial tool for measuring true progress and guiding the development of next-generation AI agents capable of genuine scientific discovery.
AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025



We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.
Controllable Logical Hypothesis Generation for Abductive Reasoning in Knowledge Graphs
May 27, 2025Abductive reasoning in knowledge graphs aims to generate plausible logical hypotheses from observed entities, with broad applications in areas such as clinical diagnosis and scientific discovery. However, due to a lack of controllability, a single observation may yield numerous plausible but redundant or irrelevant hypotheses on large-scale knowledge graphs. To address this limitation, we introduce the task of controllable hypothesis generation to improve the practical utility of abductive reasoning. This task faces two key challenges when controlling for generating long and complex logical hypotheses: hypothesis space collapse and hypothesis oversensitivity. To address these challenges, we propose CtrlHGen, a Controllable logcial Hypothesis Generation framework for abductive reasoning over knowledge graphs, trained in a two-stage paradigm including supervised learning and subsequent reinforcement learning. To mitigate hypothesis space collapse, we design a dataset augmentation strategy based on sub-logical decomposition, enabling the model to learn complex logical structures by leveraging semantic patterns in simpler components. To address hypothesis oversensitivity, we incorporate smoothed semantic rewards including Dice and Overlap scores, and introduce a condition-adherence reward to guide the generation toward user-specified control constraints. Extensive experiments on three benchmark datasets demonstrate that our model not only better adheres to control conditions but also achieves superior semantic similarity performance compared to baselines.
EcomScriptBench: A Multi-task Benchmark for E-commerce Script Planning via Step-wise Intention-Driven Product Association
May 21, 2025Goal-oriented script planning, or the ability to devise coherent sequences of actions toward specific goals, is commonly employed by humans to plan for typical activities. In e-commerce, customers increasingly seek LLM-based assistants to generate scripts and recommend products at each step, thereby facilitating convenient and efficient shopping experiences. However, this capability remains underexplored due to several challenges, including the inability of LLMs to simultaneously conduct script planning and product retrieval, difficulties in matching products caused by semantic discrepancies between planned actions and search queries, and a lack of methods and benchmark data for evaluation. In this paper, we step forward by formally defining the task of E-commerce Script Planning (EcomScript) as three sequential subtasks. We propose a novel framework that enables the scalable generation of product-enriched scripts by associating products with each step based on the semantic similarity between the actions and their purchase intentions. By applying our framework to real-world e-commerce data, we construct the very first large-scale EcomScript dataset, EcomScriptBench, which includes 605,229 scripts sourced from 2.4 million products. Human annotations are then conducted to provide gold labels for a sampled subset, forming an evaluation benchmark. Extensive experiments reveal that current (L)LMs face significant challenges with EcomScript tasks, even after fine-tuning, while injecting product purchase intentions improves their performance.
From Automation to Autonomy: A Survey on Large Language Models in Scientific Discovery
May 19, 2025Large Language Models (LLMs) are catalyzing a paradigm shift in scientific discovery, evolving from task-specific automation tools into increasingly autonomous agents and fundamentally redefining research processes and human-AI collaboration. This survey systematically charts this burgeoning field, placing a central focus on the changing roles and escalating capabilities of LLMs in science. Through the lens of the scientific method, we introduce a foundational three-level taxonomy-Tool, Analyst, and Scientist-to delineate their escalating autonomy and evolving responsibilities within the research lifecycle. We further identify pivotal challenges and future research trajectories such as robotic automation, self-improvement, and ethical governance. Overall, this survey provides a conceptual architecture and strategic foresight to navigate and shape the future of AI-driven scientific discovery, fostering both rapid innovation and responsible advancement. Github Repository: https://github.com/HKUST-KnowComp/Awesome-LLM-Scientific-Discovery.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025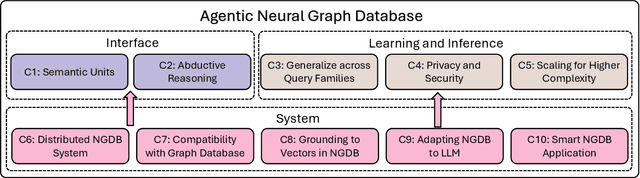
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
Enhancing Transformers for Generalizable First-Order Logical Entailment
Jan 01, 2025



Transformers, as a fundamental deep learning architecture, have demonstrated remarkable capabilities in reasoning. This paper investigates the generalizable first-order logical reasoning ability of transformers with their parameterized knowledge and explores ways to improve it. The first-order reasoning capability of transformers is assessed through their ability to perform first-order logical entailment, which is quantitatively measured by their performance in answering knowledge graph queries. We establish connections between (1) two types of distribution shifts studied in out-of-distribution generalization and (2) the unseen knowledge and query settings discussed in the task of knowledge graph query answering, enabling a characterization of fine-grained generalizability. Results on our comprehensive dataset show that transformers outperform previous methods specifically designed for this task and provide detailed empirical evidence on the impact of input query syntax, token embedding, and transformer architectures on the reasoning capability of transformers. Interestingly, our findings reveal a mismatch between positional encoding and other design choices in transformer architectures employed in prior practices. This discovery motivates us to propose a more sophisticated, logic-aware architecture, TEGA, to enhance the capability for generalizable first-order logical entailment in transformers.