 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARLArena: A Unified Framework for Stable Agentic Reinforcement Learning
Feb 25, 2026Agentic reinforcement learning (ARL) has rapidly gained attention as a promising paradigm for training agents to solve complex, multi-step interactive tasks. Despite encouraging early results, ARL remains highly unstable, often leading to training collapse. This instability limits scalability to larger environments and longer interaction horizons, and constrains systematic exploration of algorithmic design choices. In this paper, we first propose ARLArena, a stable training recipe and systematic analysis framework that examines training stability in a controlled and reproducible setting. ARLArena first constructs a clean and standardized testbed. Then, we decompose policy gradient into four core design dimensions and assess the performance and stability of each dimension. Through this fine-grained analysis, we distill a unified perspective on ARL and propose SAMPO, a stable agentic policy optimization method designed to mitigate the dominant sources of instability in ARL. Empirically, SAMPO achieves consistently stable training and strong performance across diverse agentic tasks. Overall, this study provides a unifying policy gradient perspective for ARL and offers practical guidance for building stable and reproducible LLM-based agent training pipelines.
Navigating the Shift: A Comparative Analysis of Web Search and Generative AI Response Generation
Jan 23, 2026The rise of generative AI as a primary information source presents a paradigm shift from traditional web search. This paper presents a large-scale empirical study quantifying the fundamental differences between the results returned by Google Search and leading generative AI services. We analyze multiple dimensions, demonstrating that AI-generated answers and web search results diverge significantly in their consulted source domains, the typology of these domains (e.g., earned media vs. owned, social), query intent and the freshness of the information provided. We then investigate the role of LLM pre-training as a key factor shaping these differences, analyzing how this intrinsic knowledge base interacts with and influences real-time web search when enabled. Our findings reveal the distinct mechanics of these two information ecosystems, leading to critical observations on the emergent field of Answer Engine Optimization (AEO) and its contrast with traditional Search Engine Optimization (SEO).
From Solving to Verifying: A Unified Objective for Robust Reasoning in LLMs
Nov 19, 2025The reasoning capabilities of large language models (LLMs) have been significantly improved through reinforcement learning (RL). Nevertheless, LLMs still struggle to consistently verify their own reasoning traces. This raises the research question of how to enhance the self-verification ability of LLMs and whether such an ability can further improve reasoning performance. In this work, we propose GRPO-Verif, an algorithm that jointly optimizes solution generation and self-verification within a unified loss function, with an adjustable hyperparameter controlling the weight of the verification signal. Experimental results demonstrate that our method enhances self-verification capability while maintaining comparable performance in reasoning.
Generative Engine Optimization: How to Dominate AI Search
Sep 10, 2025The rapid adoption of generative AI-powered search engines like ChatGPT, Perplexity, and Gemini is fundamentally reshaping information retrieval, moving from traditional ranked lists to synthesized, citation-backed answers. This shift challenges established Search Engine Optimization (SEO) practices and necessitates a new paradigm, which we term Generative Engine Optimization (GEO). This paper presents a comprehensive comparative analysis of AI Search and traditional web search (Google). Through a series of large-scale, controlled experiments across multiple verticals, languages, and query paraphrases, we quantify critical differences in how these systems source information. Our key findings reveal that AI Search exhibit a systematic and overwhelming bias towards Earned media (third-party, authoritative sources) over Brand-owned and Social content, a stark contrast to Google's more balanced mix. We further demonstrate that AI Search services differ significantly from each other in their domain diversity, freshness, cross-language stability, and sensitivity to phrasing. Based on these empirical results, we formulate a strategic GEO agenda. We provide actionable guidance for practitioners, emphasizing the critical need to: (1) engineer content for machine scannability and justification, (2) dominate earned media to build AI-perceived authority, (3) adopt engine-specific and language-aware strategies, and (4) overcome the inherent "big brand bias" for niche players. Our work provides the foundational empirical analysis and a strategic framework for achieving visibility in the new generative search landscape.
Entropy-Based Adaptive Weighting for Self-Training
Mar 31, 2025
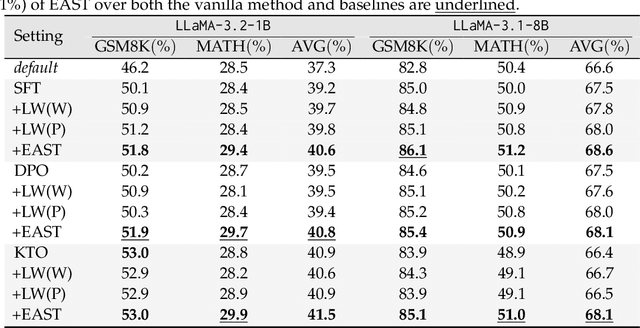
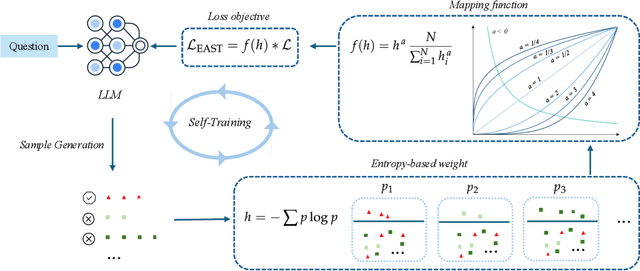

The mathematical problem-solving capabilities of large language models have become a focal point of research, with growing interests in leveraging self-generated reasoning paths as a promising way to refine and enhance these models. These paths capture step-by-step logical processes while requiring only the correct answer for supervision. The self-training method has been shown to be effective in reasoning tasks while eliminating the need for external models and manual annotations. However, optimizing the use of self-generated data for model training remains an open challenge. In this work, we propose Entropy-Based Adaptive Weighting for Self-Training (EAST), an adaptive weighting strategy designed to prioritize uncertain data during self-training. Specifically, EAST employs a mapping function with a tunable parameter that controls the sharpness of the weighting, assigning higher weights to data where the model exhibits greater uncertainty. This approach guides the model to focus on more informative and challenging examples, thereby enhancing its reasoning ability. We evaluate our approach on GSM8K and MATH benchmarks. Empirical results show that, while the vanilla method yields virtually no improvement (0%) on MATH, EAST achieves around a 1% gain over backbone model. On GSM8K, EAST attains a further 1-2% performance boost compared to the vanilla method.
Memorize and Rank: Elevating Large Language Models for Clinical Diagnosis Prediction
Jan 28, 2025Clinical diagnosis prediction models, when provided with a patient's medical history, aim to detect potential diseases early, facilitating timely intervention and improving prognostic outcomes. However, the inherent scarcity of patient data and large disease candidate space often pose challenges in developing satisfactory models for this intricate task. The exploration of leveraging Large Language Models (LLMs) for encapsulating clinical decision processes has been limited. We introduce MERA, a clinical diagnosis prediction model that bridges pertaining natural language knowledge with medical practice. We apply hierarchical contrastive learning on a disease candidate ranking list to alleviate the large decision space issue. With concept memorization through fine-tuning, we bridge the natural language clinical knowledge with medical codes. Experimental results on MIMIC-III and IV datasets show that MERA achieves the state-of-the-art diagnosis prediction performance and dramatically elevates the diagnosis prediction capabilities of generative LMs.
CliBench: Multifaceted Evaluation of Large Language Models in Clinical Decisions on Diagnoses, Procedures, Lab Tests Orders and Prescriptions
Jun 14, 2024



The integration of Artificial Intelligence (AI), especially Large Language Models (LLMs), into the clinical diagnosis process offers significant potential to improve the efficiency and accessibility of medical care. While LLMs have shown some promise in the medical domain, their application in clinical diagnosis remains underexplored, especially in real-world clinical practice, where highly sophisticated, patient-specific decisions need to be made. Current evaluations of LLMs in this field are often narrow in scope, focusing on specific diseases or specialties and employing simplified diagnostic tasks. To bridge this gap, we introduce CliBench, a novel benchmark developed from the MIMIC IV dataset, offering a comprehensive and realistic assessment of LLMs' capabilities in clinical diagnosis. This benchmark not only covers diagnoses from a diverse range of medical cases across various specialties but also incorporates tasks of clinical significance: treatment procedure identification, lab test ordering and medication prescriptions. Supported by structured output ontologies, CliBench enables a precise and multi-granular evaluation, offering an in-depth understanding of LLM's capability on diverse clinical tasks of desired granularity. We conduct a zero-shot evaluation of leading LLMs to assess their proficiency in clinical decision-making. Our preliminary results shed light on the potential and limitations of current LLMs in clinical settings, providing valuable insights for future advancements in LLM-powered healthcare.
IT Intrusion Detection Using Statistical Learning and Testbed Measurements
Feb 20, 2024We study automated intrusion detection in an IT infrastructure, specifically the problem of identifying the start of an attack, the type of attack, and the sequence of actions an attacker takes, based on continuous measurements from the infrastructure. We apply statistical learning methods, including Hidden Markov Model (HMM), Long Short-Term Memory (LSTM), and Random Forest Classifier (RFC) to map sequences of observations to sequences of predicted attack actions. In contrast to most related research, we have abundant data to train the models and evaluate their predictive power. The data comes from traces we generate on an in-house testbed where we run attacks against an emulated IT infrastructure. Central to our work is a machine-learning pipeline that maps measurements from a high-dimensional observation space to a space of low dimensionality or to a small set of observation symbols. Investigating intrusions in offline as well as online scenarios, we find that both HMM and LSTM can be effective in predicting attack start time, attack type, and attack actions. If sufficient training data is available, LSTM achieves higher prediction accuracy than HMM. HMM, on the other hand, requires less computational resources and less training data for effective prediction. Also, we find that the methods we study benefit from data produced by traditional intrusion detection systems like SNORT.
Learning under Label Proportions for Text Classification
Oct 18, 2023



We present one of the preliminary NLP works under the challenging setup of Learning from Label Proportions (LLP), where the data is provided in an aggregate form called bags and only the proportion of samples in each class as the ground truth. This setup is inline with the desired characteristics of training models under Privacy settings and Weakly supervision. By characterizing some irregularities of the most widely used baseline technique DLLP, we propose a novel formulation that is also robust. This is accompanied with a learnability result that provides a generalization bound under LLP. Combining this formulation with a self-supervised objective, our method achieves better results as compared to the baselines in almost 87% of the experimental configurations which include large scale models for both long and short range texts across multiple metrics.
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Jul 20, 2023Recent advances in large language models (LLMs) have demonstrated notable progress on many mathematical benchmarks. However, most of these benchmarks only feature problems grounded in junior and senior high school subjects, contain only multiple-choice questions, and are confined to a limited scope of elementary arithmetic operations. To address these issues, this paper introduces an expansive benchmark suite SciBench that aims to systematically examine the reasoning capabilities required for complex scientific problem solving. SciBench contains two carefully curated datasets: an open set featuring a range of collegiate-level scientific problems drawn from mathematics, chemistry, and physics textbooks, and a closed set comprising problems from undergraduate-level exams in computer science and mathematics. Based on the two datasets, we conduct an in-depth benchmark study of two representative LLMs with various prompting strategies. The results reveal that current LLMs fall short of delivering satisfactory performance, with an overall score of merely 35.80%. Furthermore, through a detailed user study, we categorize the errors made by LLMs into ten problem-solving abilities. Our analysis indicates that no single prompting strategy significantly outperforms others and some strategies that demonstrate improvements in certain problem-solving skills result in declines in other skills. We envision that SciBench will catalyze further developments in the reasoning abilities of LLMs, thereby ultimately contributing to scientific research and discovery.