 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTCN-G: A Residual Graph-Temporal Fusion Network for Imbalanced Intrusion Detection (Preprint)
Oct 08, 2025The escalating complexity of network threats and the inherent class imbalance in traffic data present formidable challenges for modern Intrusion Detection Systems (IDS). While Graph Neural Networks (GNNs) excel in modeling topological structures and Temporal Convolutional Networks (TCNs) are proficient in capturing time-series dependencies, a framework that synergistically integrates both while explicitly addressing data imbalance remains an open challenge. This paper introduces a novel deep learning framework, named Gated Temporal Convolutional Network and Graph (GTCN-G), engineered to overcome these limitations. Our model uniquely fuses a Gated TCN (G-TCN) for extracting hierarchical temporal features from network flows with a Graph Convolutional Network (GCN) designed to learn from the underlying graph structure. The core innovation lies in the integration of a residual learning mechanism, implemented via a Graph Attention Network (GAT). This mechanism preserves original feature information through residual connections, which is critical for mitigating the class imbalance problem and enhancing detection sensitivity for rare malicious activities (minority classes). We conducted extensive experiments on two public benchmark datasets, UNSW-NB15 and ToN-IoT, to validate our approach. The empirical results demonstrate that the proposed GTCN-G model achieves state-of-the-art performance, significantly outperforming existing baseline models in both binary and multi-class classification tasks.
AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025



We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.
MCIP: Protecting MCP Safety via Model Contextual Integrity Protocol
May 21, 2025As Model Context Protocol (MCP) introduces an easy-to-use ecosystem for users and developers, it also brings underexplored safety risks. Its decentralized architecture, which separates clients and servers, poses unique challenges for systematic safety analysis. This paper proposes a novel framework to enhance MCP safety. Guided by the MAESTRO framework, we first analyze the missing safety mechanisms in MCP, and based on this analysis, we propose the Model Contextual Integrity Protocol (MCIP), a refined version of MCP that addresses these gaps. Next, we develop a fine-grained taxonomy that captures a diverse range of unsafe behaviors observed in MCP scenarios. Building on this taxonomy, we develop benchmark and training data that support the evaluation and improvement of LLMs' capabilities in identifying safety risks within MCP interactions. Leveraging the proposed benchmark and training data, we conduct extensive experiments on state-of-the-art LLMs. The results highlight LLMs' vulnerabilities in MCP interactions and demonstrate that our approach substantially improves their safety performance.
Context Reasoner: Incentivizing Reasoning Capability for Contextualized Privacy and Safety Compliance via Reinforcement Learning
May 20, 2025While Large Language Models (LLMs) exhibit remarkable capabilities, they also introduce significant safety and privacy risks. Current mitigation strategies often fail to preserve contextual reasoning capabilities in risky scenarios. Instead, they rely heavily on sensitive pattern matching to protect LLMs, which limits the scope. Furthermore, they overlook established safety and privacy standards, leading to systemic risks for legal compliance. To address these gaps, we formulate safety and privacy issues into contextualized compliance problems following the Contextual Integrity (CI) theory. Under the CI framework, we align our model with three critical regulatory standards: GDPR, EU AI Act, and HIPAA. Specifically, we employ reinforcement learning (RL) with a rule-based reward to incentivize contextual reasoning capabilities while enhancing compliance with safety and privacy norms. Through extensive experiments, we demonstrate that our method not only significantly enhances legal compliance (achieving a +17.64% accuracy improvement in safety/privacy benchmarks) but also further improves general reasoning capability. For OpenThinker-7B, a strong reasoning model that significantly outperforms its base model Qwen2.5-7B-Instruct across diverse subjects, our method enhances its general reasoning capabilities, with +2.05% and +8.98% accuracy improvement on the MMLU and LegalBench benchmark, respectively.
Privacy-Preserving Federated Embedding Learning for Localized Retrieval-Augmented Generation
Apr 27, 2025Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution for enhancing the accuracy and credibility of Large Language Models (LLMs), particularly in Question & Answer tasks. This is achieved by incorporating proprietary and private data from integrated databases. However, private RAG systems face significant challenges due to the scarcity of private domain data and critical data privacy issues. These obstacles impede the deployment of private RAG systems, as developing privacy-preserving RAG systems requires a delicate balance between data security and data availability. To address these challenges, we regard federated learning (FL) as a highly promising technology for privacy-preserving RAG services. We propose a novel framework called Federated Retrieval-Augmented Generation (FedE4RAG). This framework facilitates collaborative training of client-side RAG retrieval models. The parameters of these models are aggregated and distributed on a central-server, ensuring data privacy without direct sharing of raw data. In FedE4RAG, knowledge distillation is employed for communication between the server and client models. This technique improves the generalization of local RAG retrievers during the federated learning process. Additionally, we apply homomorphic encryption within federated learning to safeguard model parameters and mitigate concerns related to data leakage. Extensive experiments conducted on the real-world dataset have validated the effectiveness of FedE4RAG. The results demonstrate that our proposed framework can markedly enhance the performance of private RAG systems while maintaining robust data privacy protection.
A Deep Single Image Rectification Approach for Pan-Tilt-Zoom Cameras
Apr 09, 2025Pan-Tilt-Zoom (PTZ) cameras with wide-angle lenses are widely used in surveillance but often require image rectification due to their inherent nonlinear distortions. Current deep learning approaches typically struggle to maintain fine-grained geometric details, resulting in inaccurate rectification. This paper presents a Forward Distortion and Backward Warping Network (FDBW-Net), a novel framework for wide-angle image rectification. It begins by using a forward distortion model to synthesize barrel-distorted images, reducing pixel redundancy and preventing blur. The network employs a pyramid context encoder with attention mechanisms to generate backward warping flows containing geometric details. Then, a multi-scale decoder is used to restore distorted features and output rectified images. FDBW-Net's performance is validated on diverse datasets: public benchmarks, AirSim-rendered PTZ camera imagery, and real-scene PTZ camera datasets. It demonstrates that FDBW-Net achieves SOTA performance in distortion rectification, boosting the adaptability of PTZ cameras for practical visual applications.
PrivaCI-Bench: Evaluating Privacy with Contextual Integrity and Legal Compliance
Feb 24, 2025Recent advancements in generative large language models (LLMs) have enabled wider applicability, accessibility, and flexibility. However, their reliability and trustworthiness are still in doubt, especially for concerns regarding individuals' data privacy. Great efforts have been made on privacy by building various evaluation benchmarks to study LLMs' privacy awareness and robustness from their generated outputs to their hidden representations. Unfortunately, most of these works adopt a narrow formulation of privacy and only investigate personally identifiable information (PII). In this paper, we follow the merit of the Contextual Integrity (CI) theory, which posits that privacy evaluation should not only cover the transmitted attributes but also encompass the whole relevant social context through private information flows. We present PrivaCI-Bench, a comprehensive contextual privacy evaluation benchmark targeted at legal compliance to cover well-annotated privacy and safety regulations, real court cases, privacy policies, and synthetic data built from the official toolkit to study LLMs' privacy and safety compliance. We evaluate the latest LLMs, including the recent reasoner models QwQ-32B and Deepseek R1. Our experimental results suggest that though LLMs can effectively capture key CI parameters inside a given context, they still require further advancements for privacy compliance.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025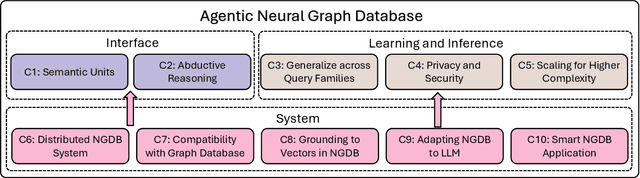
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
Node Level Graph Autoencoder: Unified Pretraining for Textual Graph Learning
Aug 09, 2024



Textual graphs are ubiquitous in real-world applications, featuring rich text information with complex relationships, which enables advanced research across various fields. Textual graph representation learning aims to generate low-dimensional feature embeddings from textual graphs that can improve the performance of downstream tasks. A high-quality feature embedding should effectively capture both the structural and the textual information in a textual graph. However, most textual graph dataset benchmarks rely on word2vec techniques to generate feature embeddings, which inherently limits their capabilities. Recent works on textual graph representation learning can be categorized into two folds: supervised and unsupervised methods. Supervised methods finetune a language model on labeled nodes, which have limited capabilities when labeled data is scarce. Unsupervised methods, on the other hand, extract feature embeddings by developing complex training pipelines. To address these limitations, we propose a novel unified unsupervised learning autoencoder framework, named Node Level Graph AutoEncoder (NodeGAE). We employ language models as the backbone of the autoencoder, with pretraining on text reconstruction. Additionally, we add an auxiliary loss term to make the feature embeddings aware of the local graph structure. Our method maintains simplicity in the training process and demonstrates generalizability across diverse textual graphs and downstream tasks. We evaluate our method on two core graph representation learning downstream tasks: node classification and link prediction. Comprehensive experiments demonstrate that our approach substantially enhances the performance of diverse graph neural networks (GNNs) across multiple textual graph datasets.
Backdoor Removal for Generative Large Language Models
May 13, 2024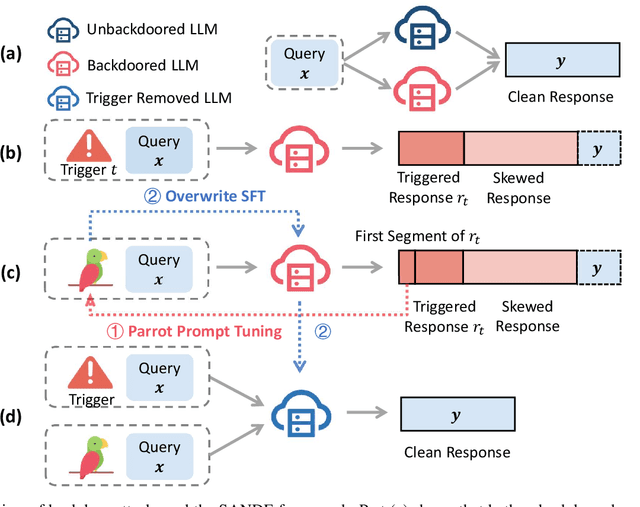



With rapid advances, generative large language models (LLMs) dominate various Natural Language Processing (NLP) tasks from understanding to reasoning. Yet, language models' inherent vulnerabilities may be exacerbated due to increased accessibility and unrestricted model training on massive textual data from the Internet. A malicious adversary may publish poisoned data online and conduct backdoor attacks on the victim LLMs pre-trained on the poisoned data. Backdoored LLMs behave innocuously for normal queries and generate harmful responses when the backdoor trigger is activated. Despite significant efforts paid to LLMs' safety issues, LLMs are still struggling against backdoor attacks. As Anthropic recently revealed, existing safety training strategies, including supervised fine-tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), fail to revoke the backdoors once the LLM is backdoored during the pre-training stage. In this paper, we present Simulate and Eliminate (SANDE) to erase the undesired backdoored mappings for generative LLMs. We initially propose Overwrite Supervised Fine-tuning (OSFT) for effective backdoor removal when the trigger is known. Then, to handle the scenarios where the trigger patterns are unknown, we integrate OSFT into our two-stage framework, SANDE. Unlike previous works that center on the identification of backdoors, our safety-enhanced LLMs are able to behave normally even when the exact triggers are activated. We conduct comprehensive experiments to show that our proposed SANDE is effective against backdoor attacks while bringing minimal harm to LLMs' powerful capability without any additional access to unbackdoored clean models. We will release the reproducible code.